 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnvy-Free Classification
Sep 23, 2018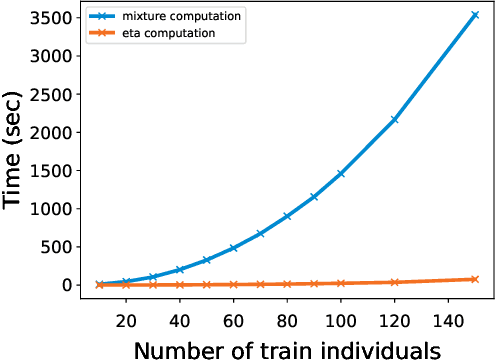
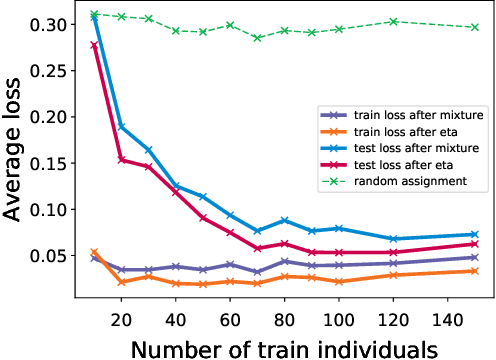
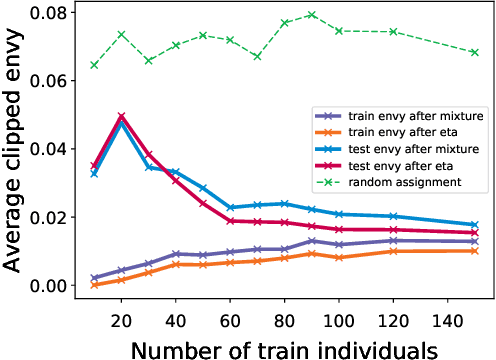
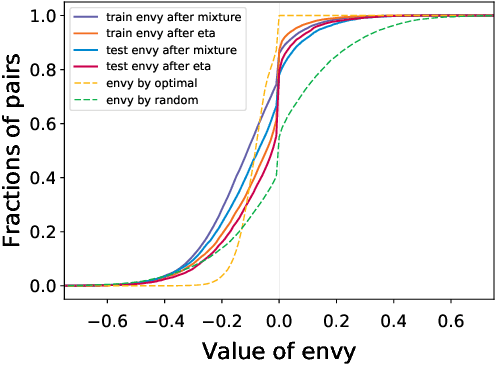
In classic fair division problems such as cake cutting and rent division, envy-freeness requires that each individual (weakly) prefer his allocation to anyone else's. On a conceptual level, we argue that envy-freeness also provides a compelling notion of fairness for classification tasks. Our technical focus is the generalizability of envy-free classification, i.e., understanding whether a classifier that is envy free on a sample would be almost envy free with respect to the underlying distribution with high probability. Our main result establishes that a small sample is sufficient to achieve such guarantees, when the classifier in question is a mixture of deterministic classifiers that belong to a family of low Natarajan dimension.
Interpretable Multi-Objective Reinforcement Learning through Policy Orchestration
Sep 21, 2018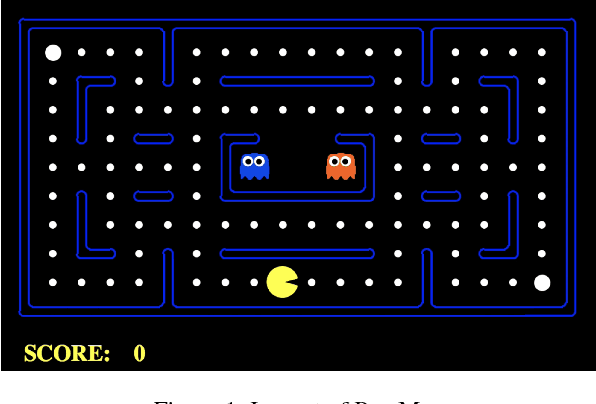
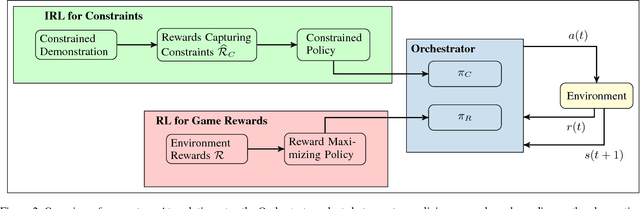
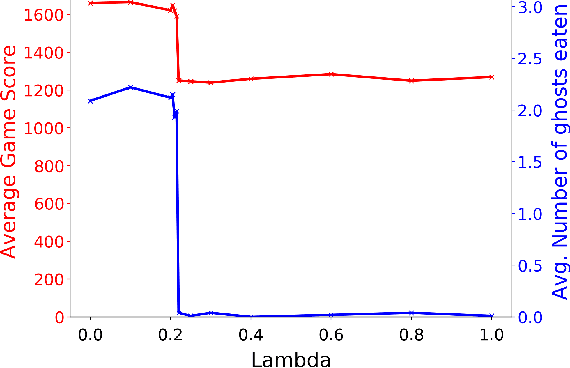
Autonomous cyber-physical agents and systems play an increasingly large role in our lives. To ensure that agents behave in ways aligned with the values of the societies in which they operate, we must develop techniques that allow these agents to not only maximize their reward in an environment, but also to learn and follow the implicit constraints of society. These constraints and norms can come from any number of sources including regulations, business process guidelines, laws, ethical principles, social norms, and moral values. We detail a novel approach that uses inverse reinforcement learning to learn a set of unspecified constraints from demonstrations of the task, and reinforcement learning to learn to maximize the environment rewards. More precisely, we assume that an agent can observe traces of behavior of members of the society but has no access to the explicit set of constraints that give rise to the observed behavior. Inverse reinforcement learning is used to learn such constraints, that are then combined with a possibly orthogonal value function through the use of a contextual bandit-based orchestrator that picks a contextually-appropriate choice between the two policies (constraint-based and environment reward-based) when taking actions. The contextual bandit orchestrator allows the agent to mix policies in novel ways, taking the best actions from either a reward maximizing or constrained policy. In addition, the orchestrator is transparent on which policy is being employed at each time step. We test our algorithms using a Pac-Man domain and show that the agent is able to learn to act optimally, act within the demonstrated constraints, and mix these two functions in complex ways.
Choosing How to Choose Papers
Aug 27, 2018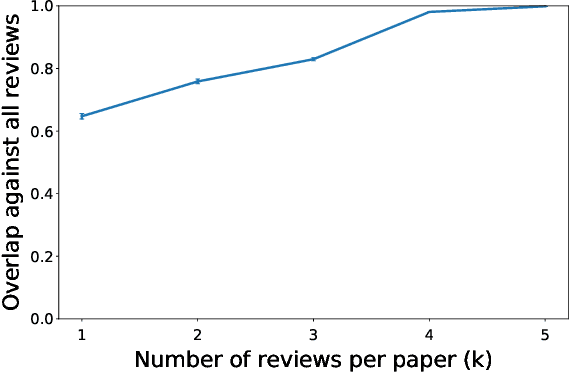

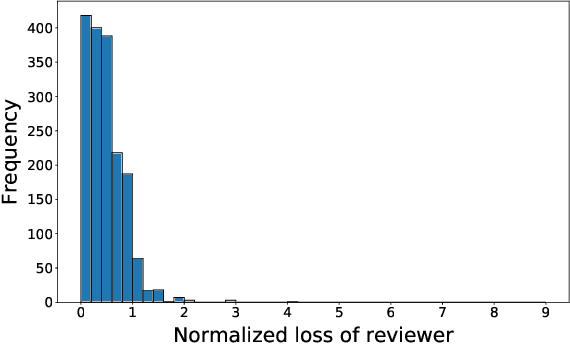

It is common to see a handful of reviewers reject a highly novel paper, because they view, say, extensive experiments as far more important than novelty, whereas the community as a whole would have embraced the paper. More generally, the disparate mapping of criteria scores to final recommendations by different reviewers is a major source of inconsistency in peer review. In this paper we present a framework --- based on $L(p,q)$-norm empirical risk minimization --- for learning the community's aggregate mapping. We draw on computational social choice to identify desirable values of $p$ and $q$; specifically, we characterize $p=q=1$ as the only choice that satisfies three natural axiomatic properties. Finally, we implement and apply our approach to reviews from IJCAI 2017.
A Voting-Based System for Ethical Decision Making
Sep 20, 2017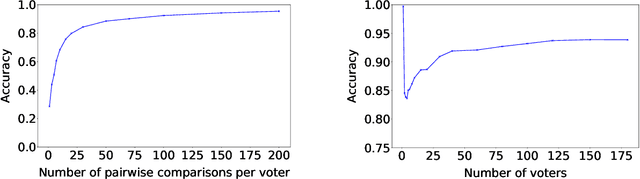
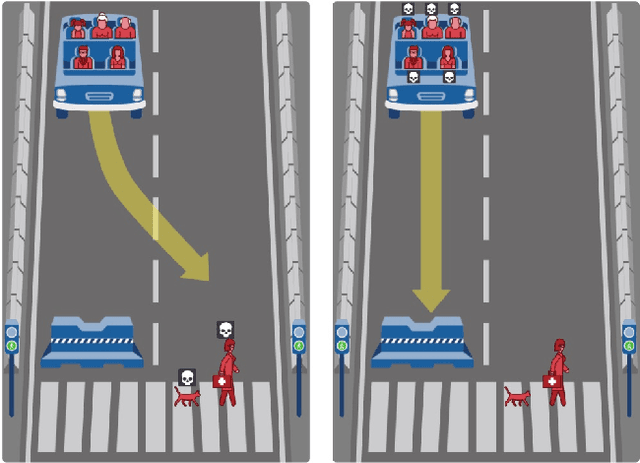
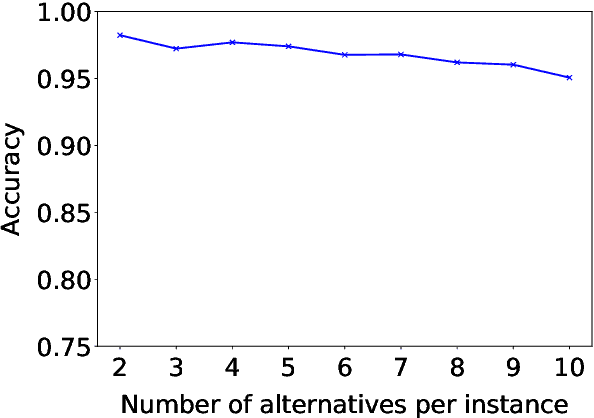
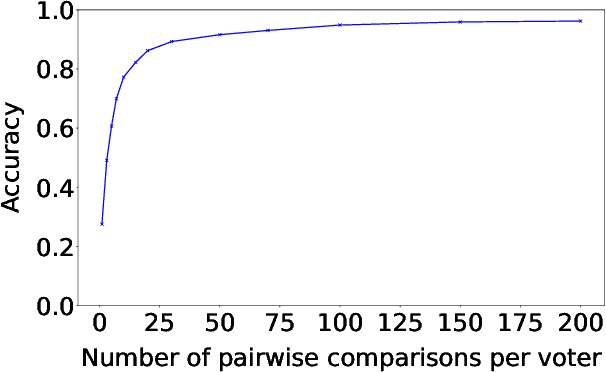
We present a general approach to automating ethical decisions, drawing on machine learning and computational social choice. In a nutshell, we propose to learn a model of societal preferences, and, when faced with a specific ethical dilemma at runtime, efficiently aggregate those preferences to identify a desirable choice. We provide a concrete algorithm that instantiates our approach; some of its crucial steps are informed by a new theory of swap-dominance efficient voting rules. Finally, we implement and evaluate a system for ethical decision making in the autonomous vehicle domain, using preference data collected from 1.3 million people through the Moral Machine website.
Non-Count Symmetries in Boolean & Multi-Valued Prob. Graphical Models
Jul 27, 2017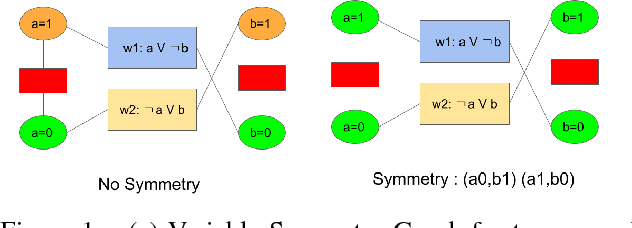
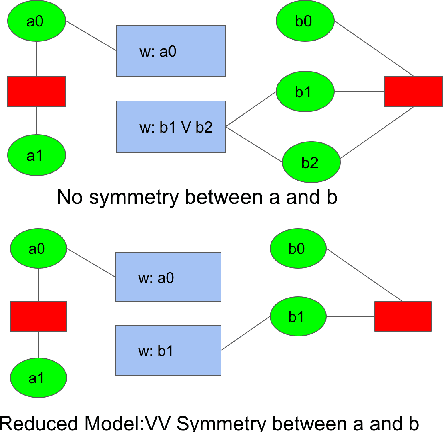
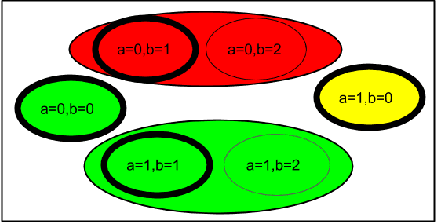
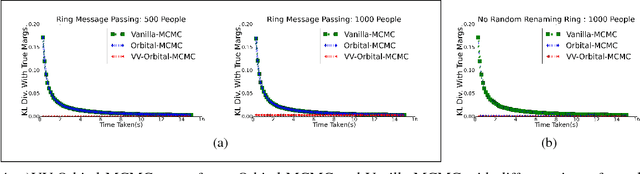
Lifted inference algorithms commonly exploit symmetries in a probabilistic graphical model (PGM) for efficient inference. However, existing algorithms for Boolean-valued domains can identify only those pairs of states as symmetric, in which the number of ones and zeros match exactly (count symmetries). Moreover, algorithms for lifted inference in multi-valued domains also compute a multi-valued extension of count symmetries only. These algorithms miss many symmetries in a domain. In this paper, we present first algorithms to compute non-count symmetries in both Boolean-valued and multi-valued domains. Our methods can also find symmetries between multi-valued variables that have different domain cardinalities. The key insight in the algorithms is that they change the unit of symmetry computation from a variable to a variable-value (VV) pair. Our experiments find that exploiting these symmetries in MCMC can obtain substantial computational gains over existing algorithms.
* 9 pages, 5 figures
Weighted Voting Via No-Regret Learning
Mar 14, 2017Voting systems typically treat all voters equally. We argue that perhaps they should not: Voters who have supported good choices in the past should be given higher weight than voters who have supported bad ones. To develop a formal framework for desirable weighting schemes, we draw on no-regret learning. Specifically, given a voting rule, we wish to design a weighting scheme such that applying the voting rule, with voters weighted by the scheme, leads to choices that are almost as good as those endorsed by the best voter in hindsight. We derive possibility and impossibility results for the existence of such weighting schemes, depending on whether the voting rule and the weighting scheme are deterministic or randomized, as well as on the social choice axioms satisfied by the voting rule.