 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextures: Representations from Contexts
May 02, 2025Despite the empirical success of foundation models, we do not have a systematic characterization of the representations that these models learn. In this paper, we establish the contexture theory. It shows that a large class of representation learning methods can be characterized as learning from the association between the input and a context variable. Specifically, we show that many popular methods aim to approximate the top-d singular functions of the expectation operator induced by the context, in which case we say that the representation learns the contexture. We demonstrate the generality of the contexture theory by proving that representation learning within various learning paradigms -- supervised, self-supervised, and manifold learning -- can all be studied from such a perspective. We also prove that the representations that learn the contexture are optimal on those tasks that are compatible with the context. One important implication of the contexture theory is that once the model is large enough to approximate the top singular functions, further scaling up the model size yields diminishing returns. Therefore, scaling is not all we need, and further improvement requires better contexts. To this end, we study how to evaluate the usefulness of a context without knowing the downstream tasks. We propose a metric and show by experiments that it correlates well with the actual performance of the encoder on many real datasets.
Identifying General Mechanism Shifts in Linear Causal Representations
Oct 31, 2024



We consider the linear causal representation learning setting where we observe a linear mixing of $d$ unknown latent factors, which follow a linear structural causal model. Recent work has shown that it is possible to recover the latent factors as well as the underlying structural causal model over them, up to permutation and scaling, provided that we have at least $d$ environments, each of which corresponds to perfect interventions on a single latent node (factor). After this powerful result, a key open problem faced by the community has been to relax these conditions: allow for coarser than perfect single-node interventions, and allow for fewer than $d$ of them, since the number of latent factors $d$ could be very large. In this work, we consider precisely such a setting, where we allow a smaller than $d$ number of environments, and also allow for very coarse interventions that can very coarsely \textit{change the entire causal graph over the latent factors}. On the flip side, we relax what we wish to extract to simply the \textit{list of nodes that have shifted between one or more environments}. We provide a surprising identifiability result that it is indeed possible, under some very mild standard assumptions, to identify the set of shifted nodes. Our identifiability proof moreover is a constructive one: we explicitly provide necessary and sufficient conditions for a node to be a shifted node, and show that we can check these conditions given observed data. Our algorithm lends itself very naturally to the sample setting where instead of just interventional distributions, we are provided datasets of samples from each of these distributions. We corroborate our results on both synthetic experiments as well as an interesting psychometric dataset. The code can be found at https://github.com/TianyuCodings/iLCS.
Likelihood-based Differentiable Structure Learning
Oct 08, 2024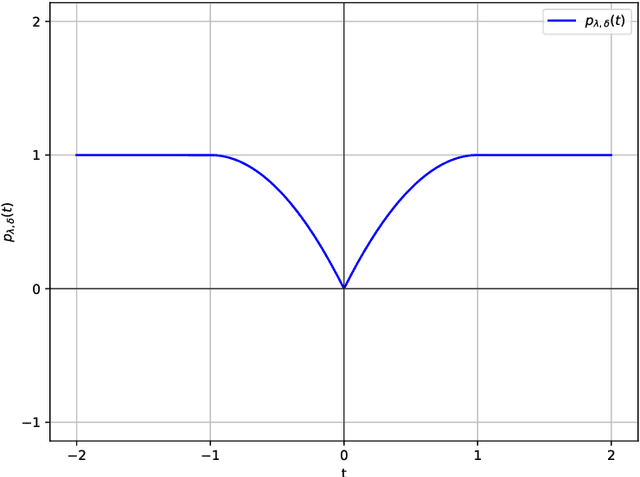
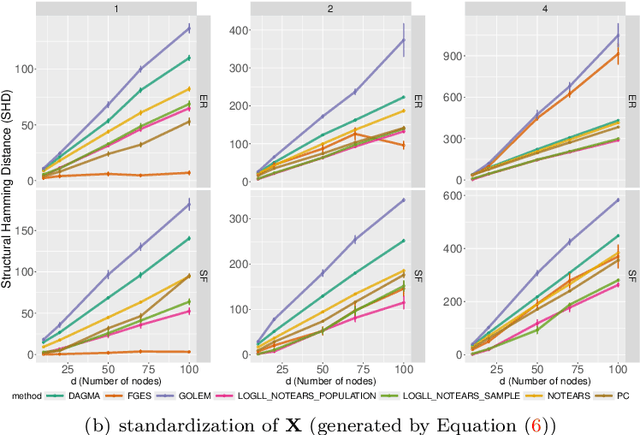
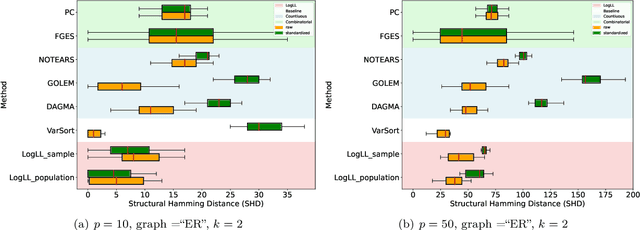
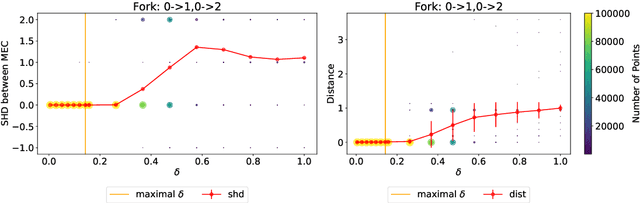
Existing approaches to differentiable structure learning of directed acyclic graphs (DAGs) rely on strong identifiability assumptions in order to guarantee that global minimizers of the acyclicity-constrained optimization problem identifies the true DAG. Moreover, it has been observed empirically that the optimizer may exploit undesirable artifacts in the loss function. We explain and remedy these issues by studying the behavior of differentiable acyclicity-constrained programs under general likelihoods with multiple global minimizers. By carefully regularizing the likelihood, it is possible to identify the sparsest model in the Markov equivalence class, even in the absence of an identifiable parametrization. We first study the Gaussian case in detail, showing how proper regularization of the likelihood defines a score that identifies the sparsest model. Assuming faithfulness, it also recovers the Markov equivalence class. These results are then generalized to general models and likelihoods, where the same claims hold. These theoretical results are validated empirically, showing how this can be done using standard gradient-based optimizers, thus paving the way for differentiable structure learning under general models and losses.
LLM-Select: Feature Selection with Large Language Models
Jul 02, 2024In this paper, we demonstrate a surprising capability of large language models (LLMs): given only input feature names and a description of a prediction task, they are capable of selecting the most predictive features, with performance rivaling the standard tools of data science. Remarkably, these models exhibit this capacity across various query mechanisms. For example, we zero-shot prompt an LLM to output a numerical importance score for a feature (e.g., "blood pressure") in predicting an outcome of interest (e.g., "heart failure"), with no additional context. In particular, we find that the latest models, such as GPT-4, can consistently identify the most predictive features regardless of the query mechanism and across various prompting strategies. We illustrate these findings through extensive experiments on real-world data, where we show that LLM-based feature selection consistently achieves strong performance competitive with data-driven methods such as the LASSO, despite never having looked at the downstream training data. Our findings suggest that LLMs may be useful not only for selecting the best features for training but also for deciding which features to collect in the first place. This could potentially benefit practitioners in domains like healthcare, where collecting high-quality data comes at a high cost.
Do LLMs dream of elephants (when told not to)? Latent concept association and associative memory in transformers
Jun 26, 2024



Large Language Models (LLMs) have the capacity to store and recall facts. Through experimentation with open-source models, we observe that this ability to retrieve facts can be easily manipulated by changing contexts, even without altering their factual meanings. These findings highlight that LLMs might behave like an associative memory model where certain tokens in the contexts serve as clues to retrieving facts. We mathematically explore this property by studying how transformers, the building blocks of LLMs, can complete such memory tasks. We study a simple latent concept association problem with a one-layer transformer and we show theoretically and empirically that the transformer gathers information using self-attention and uses the value matrix for associative memory.
On the Origins of Linear Representations in Large Language Models
Mar 06, 2024Recent works have argued that high-level semantic concepts are encoded "linearly" in the representation space of large language models. In this work, we study the origins of such linear representations. To that end, we introduce a simple latent variable model to abstract and formalize the concept dynamics of the next token prediction. We use this formalism to show that the next token prediction objective (softmax with cross-entropy) and the implicit bias of gradient descent together promote the linear representation of concepts. Experiments show that linear representations emerge when learning from data matching the latent variable model, confirming that this simple structure already suffices to yield linear representations. We additionally confirm some predictions of the theory using the LLaMA-2 large language model, giving evidence that the simplified model yields generalizable insights.
Learning Interpretable Concepts: Unifying Causal Representation Learning and Foundation Models
Feb 14, 2024To build intelligent machine learning systems, there are two broad approaches. One approach is to build inherently interpretable models, as endeavored by the growing field of causal representation learning. The other approach is to build highly-performant foundation models and then invest efforts into understanding how they work. In this work, we relate these two approaches and study how to learn human-interpretable concepts from data. Weaving together ideas from both fields, we formally define a notion of concepts and show that they can be provably recovered from diverse data. Experiments on synthetic data and large language models show the utility of our unified approach.
Spectrally Transformed Kernel Regression
Feb 01, 2024Unlabeled data is a key component of modern machine learning. In general, the role of unlabeled data is to impose a form of smoothness, usually from the similarity information encoded in a base kernel, such as the $\epsilon$-neighbor kernel or the adjacency matrix of a graph. This work revisits the classical idea of spectrally transformed kernel regression (STKR), and provides a new class of general and scalable STKR estimators able to leverage unlabeled data. Intuitively, via spectral transformation, STKR exploits the data distribution for which unlabeled data can provide additional information. First, we show that STKR is a principled and general approach, by characterizing a universal type of "target smoothness", and proving that any sufficiently smooth function can be learned by STKR. Second, we provide scalable STKR implementations for the inductive setting and a general transformation function, while prior work is mostly limited to the transductive setting. Third, we derive statistical guarantees for two scenarios: STKR with a known polynomial transformation, and STKR with kernel PCA when the transformation is unknown. Overall, we believe that this work helps deepen our understanding of how to work with unlabeled data, and its generality makes it easier to inspire new methods.
An Interventional Perspective on Identifiability in Gaussian LTI Systems with Independent Component Analysis
Nov 29, 2023We investigate the relationship between system identification and intervention design in dynamical systems. While previous research demonstrated how identifiable representation learning methods, such as Independent Component Analysis (ICA), can reveal cause-effect relationships, it relied on a passive perspective without considering how to collect data. Our work shows that in Gaussian Linear Time-Invariant (LTI) systems, the system parameters can be identified by introducing diverse intervention signals in a multi-environment setting. By harnessing appropriate diversity assumptions motivated by the ICA literature, our findings connect experiment design and representational identifiability in dynamical systems. We corroborate our findings on synthetic and (simulated) physical data. Additionally, we show that Hidden Markov Models, in general, and (Gaussian) LTI systems, in particular, fulfil a generalization of the Causal de Finetti theorem with continuous parameters.
Responsible AI (RAI) Games and Ensembles
Oct 28, 2023Several recent works have studied the societal effects of AI; these include issues such as fairness, robustness, and safety. In many of these objectives, a learner seeks to minimize its worst-case loss over a set of predefined distributions (known as uncertainty sets), with usual examples being perturbed versions of the empirical distribution. In other words, aforementioned problems can be written as min-max problems over these uncertainty sets. In this work, we provide a general framework for studying these problems, which we refer to as Responsible AI (RAI) games. We provide two classes of algorithms for solving these games: (a) game-play based algorithms, and (b) greedy stagewise estimation algorithms. The former class is motivated by online learning and game theory, whereas the latter class is motivated by the classical statistical literature on boosting, and regression. We empirically demonstrate the applicability and competitive performance of our techniques for solving several RAI problems, particularly around subpopulation shift.