 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextures: Representations from Contexts
May 02, 2025Despite the empirical success of foundation models, we do not have a systematic characterization of the representations that these models learn. In this paper, we establish the contexture theory. It shows that a large class of representation learning methods can be characterized as learning from the association between the input and a context variable. Specifically, we show that many popular methods aim to approximate the top-d singular functions of the expectation operator induced by the context, in which case we say that the representation learns the contexture. We demonstrate the generality of the contexture theory by proving that representation learning within various learning paradigms -- supervised, self-supervised, and manifold learning -- can all be studied from such a perspective. We also prove that the representations that learn the contexture are optimal on those tasks that are compatible with the context. One important implication of the contexture theory is that once the model is large enough to approximate the top singular functions, further scaling up the model size yields diminishing returns. Therefore, scaling is not all we need, and further improvement requires better contexts. To this end, we study how to evaluate the usefulness of a context without knowing the downstream tasks. We propose a metric and show by experiments that it correlates well with the actual performance of the encoder on many real datasets.
CLUE: Concept-Level Uncertainty Estimation for Large Language Models
Sep 04, 2024Large Language Models (LLMs) have demonstrated remarkable proficiency in various natural language generation (NLG) tasks. Previous studies suggest that LLMs' generation process involves uncertainty. However, existing approaches to uncertainty estimation mainly focus on sequence-level uncertainty, overlooking individual pieces of information within sequences. These methods fall short in separately assessing the uncertainty of each component in a sequence. In response, we propose a novel framework for Concept-Level Uncertainty Estimation (CLUE) for LLMs. We leverage LLMs to convert output sequences into concept-level representations, breaking down sequences into individual concepts and measuring the uncertainty of each concept separately. We conduct experiments to demonstrate that CLUE can provide more interpretable uncertainty estimation results compared with sentence-level uncertainty, and could be a useful tool for various tasks such as hallucination detection and story generation.
Sample based Explanations via Generalized Representers
Oct 27, 2023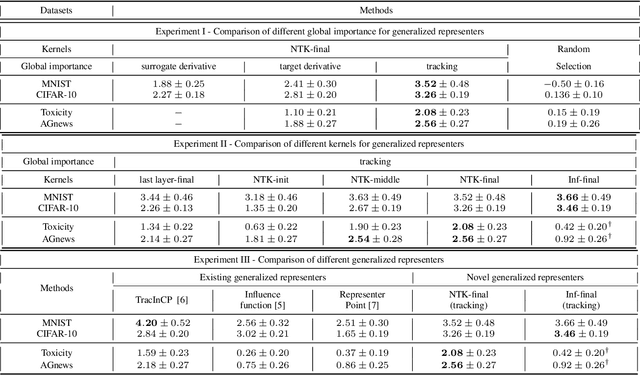
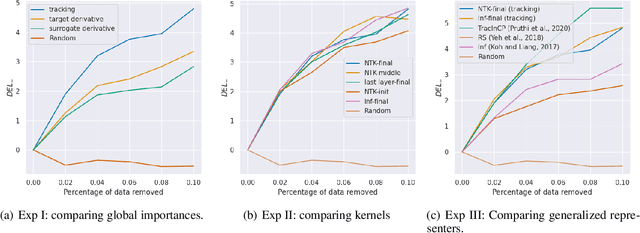
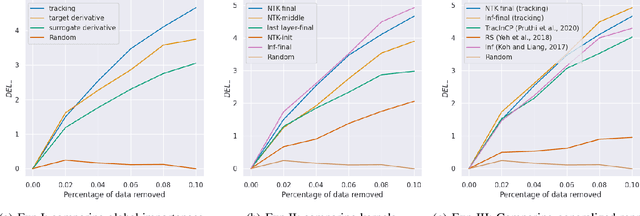
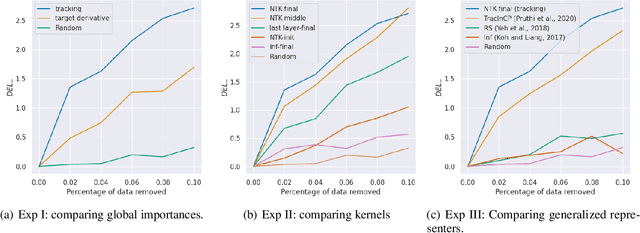
We propose a general class of sample based explanations of machine learning models, which we term generalized representers. To measure the effect of a training sample on a model's test prediction, generalized representers use two components: a global sample importance that quantifies the importance of the training point to the model and is invariant to test samples, and a local sample importance that measures similarity between the training sample and the test point with a kernel. A key contribution of the paper is to show that generalized representers are the only class of sample based explanations satisfying a natural set of axiomatic properties. We discuss approaches to extract global importances given a kernel, and also natural choices of kernels given modern non-linear models. As we show, many popular existing sample based explanations could be cast as generalized representers with particular choices of kernels and approaches to extract global importances. Additionally, we conduct empirical comparisons of different generalized representers on two image and two text classification datasets.
Representer Point Selection for Explaining Regularized High-dimensional Models
May 31, 2023



We introduce a novel class of sample-based explanations we term high-dimensional representers, that can be used to explain the predictions of a regularized high-dimensional model in terms of importance weights for each of the training samples. Our workhorse is a novel representer theorem for general regularized high-dimensional models, which decomposes the model prediction in terms of contributions from each of the training samples: with positive (negative) values corresponding to positive (negative) impact training samples to the model's prediction. We derive consequences for the canonical instances of $\ell_1$ regularized sparse models, and nuclear norm regularized low-rank models. As a case study, we further investigate the application of low-rank models in the context of collaborative filtering, where we instantiate high-dimensional representers for specific popular classes of models. Finally, we study the empirical performance of our proposed methods on three real-world binary classification datasets and two recommender system datasets. We also showcase the utility of high-dimensional representers in explaining model recommendations.
Faith-Shap: The Faithful Shapley Interaction Index
Mar 09, 2022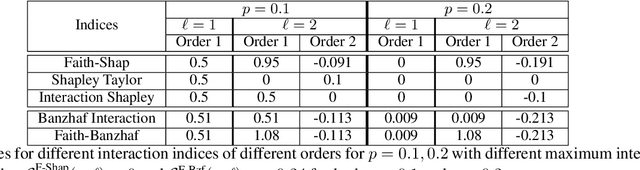
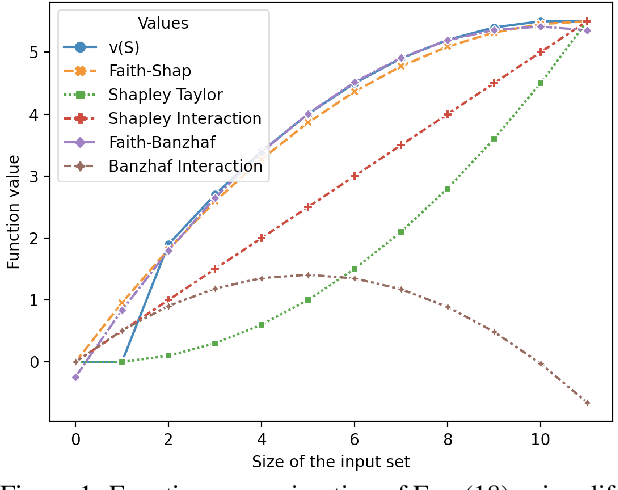
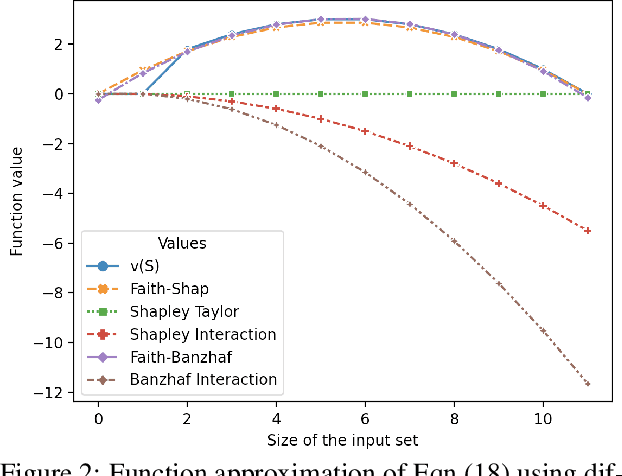
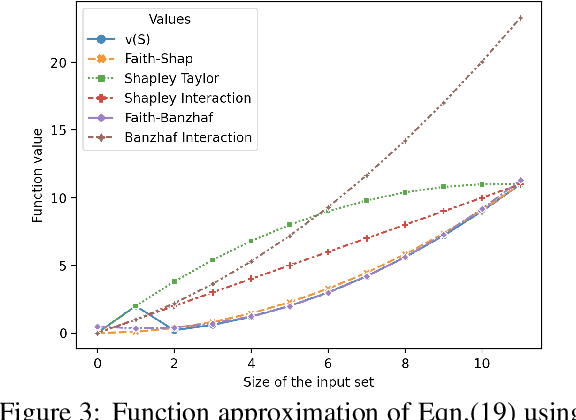
Shapley values, which were originally designed to assign attributions to individual players in coalition games, have become a commonly used approach in explainable machine learning to provide attributions to input features for black-box machine learning models. A key attraction of Shapley values is that they uniquely satisfy a very natural set of axiomatic properties. However, extending the Shapley value to assigning attributions to interactions rather than individual players, an interaction index, is non-trivial: as the natural set of axioms for the original Shapley values, extended to the context of interactions, no longer specify a unique interaction index. Many proposals thus introduce additional less "natural" axioms, while sacrificing the key axiom of efficiency, in order to obtain unique interaction indices. In this work, rather than introduce additional conflicting axioms, we adopt the viewpoint of Shapley values as coefficients of the most faithful linear approximation to the pseudo-Boolean coalition game value function. By extending linear to $\ell$-order polynomial approximations, we can then define the general family of faithful interaction indices}. We show that by additionally requiring the faithful interaction indices to satisfy interaction-extensions of the standard individual Shapley axioms (dummy, symmetry, linearity, and efficiency), we obtain a unique FaithfulShapley Interaction index, which we denote Faith-Shap, as a natural generalization of the Shapley value to interactions. We then provide some illustrative contrasts of Faith-Shap with previously proposed interaction indices, and further investigate some of its interesting algebraic properties. We further show the computational efficiency of computing Faith-Shap, together with some additional qualitative insights, via some illustrative experiments.
Heavy-tailed Streaming Statistical Estimation
Aug 25, 2021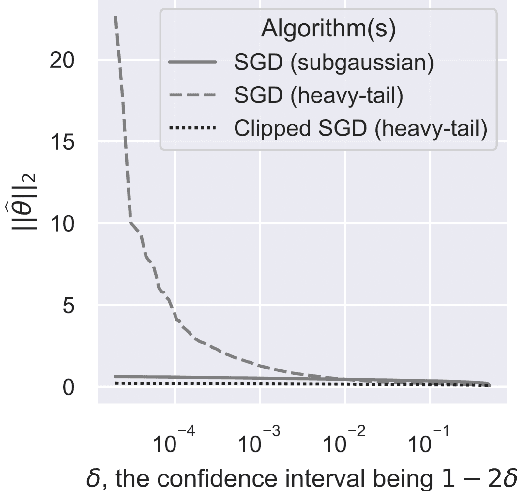
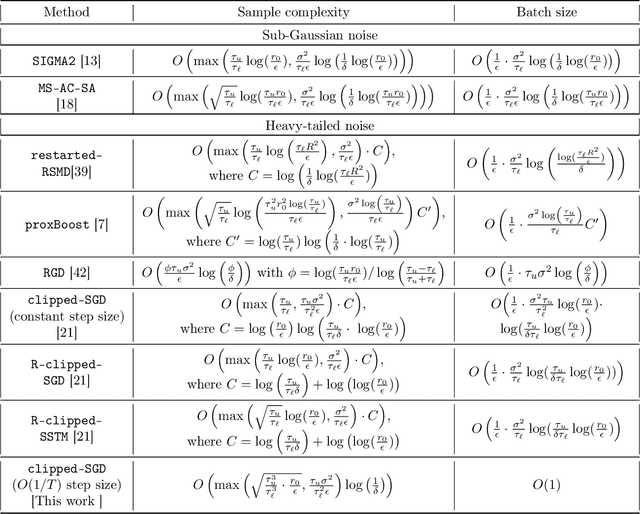
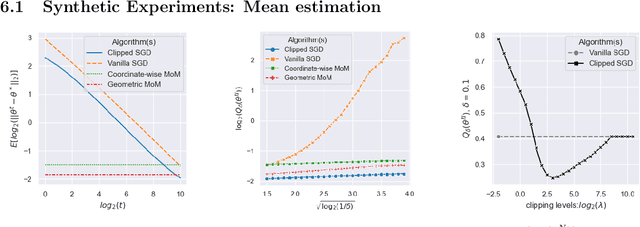
We consider the task of heavy-tailed statistical estimation given streaming $p$-dimensional samples. This could also be viewed as stochastic optimization under heavy-tailed distributions, with an additional $O(p)$ space complexity constraint. We design a clipped stochastic gradient descent algorithm and provide an improved analysis, under a more nuanced condition on the noise of the stochastic gradients, which we show is critical when analyzing stochastic optimization problems arising from general statistical estimation problems. Our results guarantee convergence not just in expectation but with exponential concentration, and moreover does so using $O(1)$ batch size. We provide consequences of our results for mean estimation and linear regression. Finally, we provide empirical corroboration of our results and algorithms via synthetic experiments for mean estimation and linear regression.
Order-free Learning Alleviating Exposure Bias in Multi-label Classification
Sep 08, 2019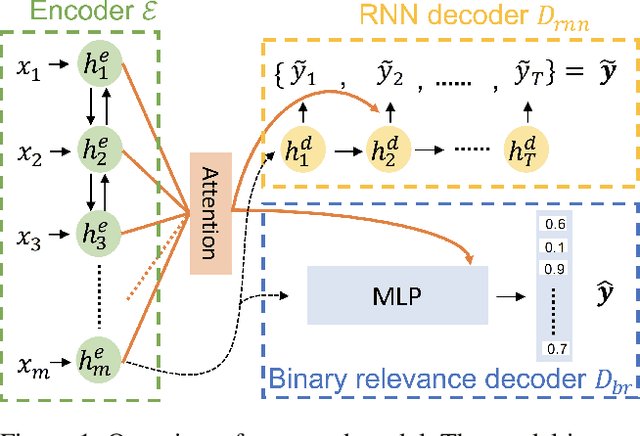
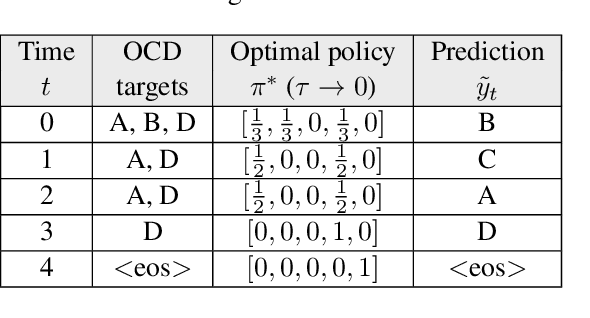
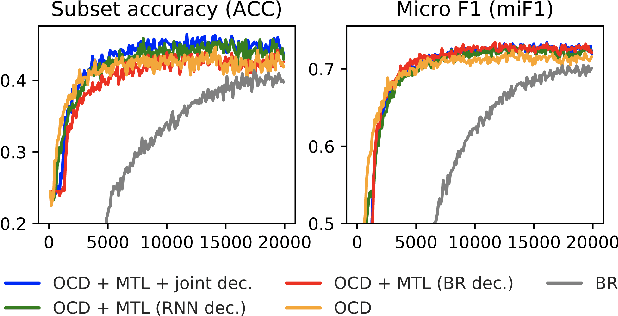
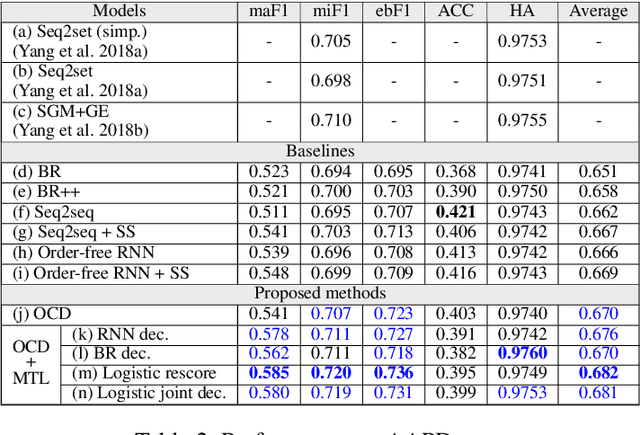
Multi-label classification (MLC) assigns multiple labels to each sample. Prior studies show that MLC can be transformed to a sequence prediction problem with a recurrent neural network (RNN) decoder to model the label dependency. However, training a RNN decoder requires a predefined order of labels, which is not directly available in the MLC specification. Besides, RNN thus trained tends to overfit the label combinations in the training set and have difficulty generating unseen label sequences. In this paper, we propose a new framework for MLC which does not rely on a predefined label order and thus alleviates exposure bias. The experimental results on three multi-label classification benchmark datasets show that our method outperforms competitive baselines by a large margin. We also find the proposed approach has a higher probability of generating label combinations not seen during training than the baseline models. The result shows that the proposed approach has better generalization capability.
Completely Unsupervised Phoneme Recognition By A Generative Adversarial Network Harmonized With Iteratively Refined Hidden Markov Models
Apr 08, 2019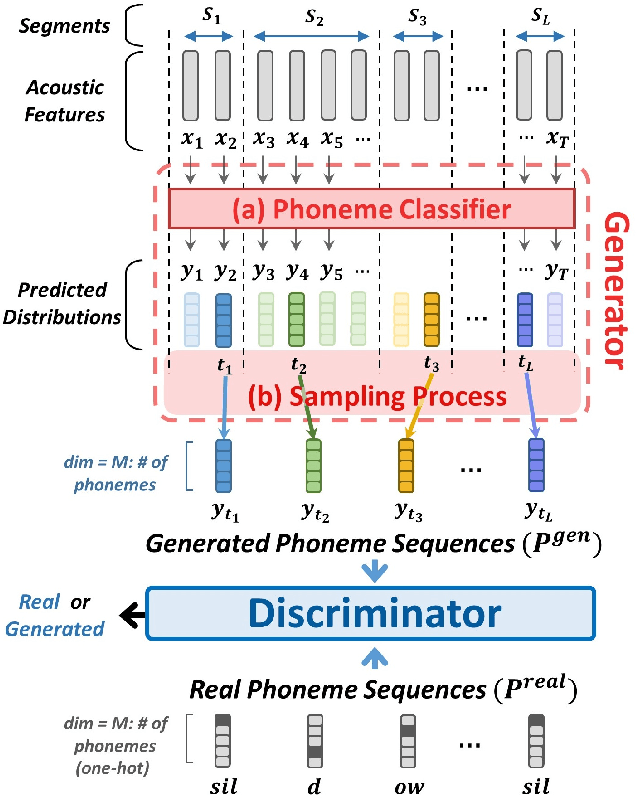
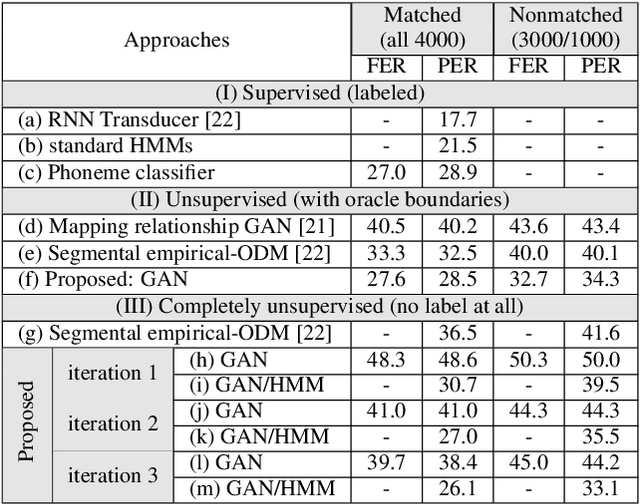
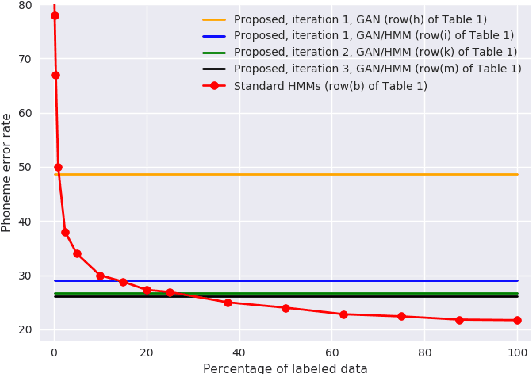
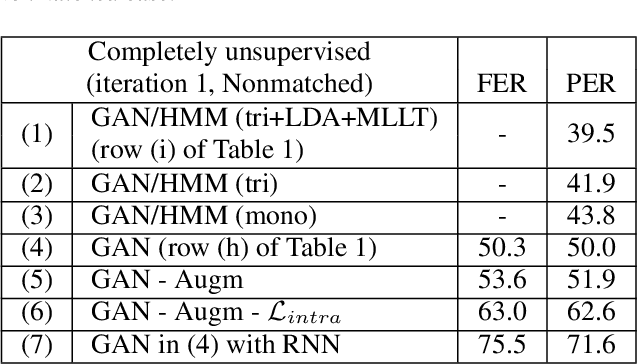
Producing a large annotated speech corpus for training ASR systems remains difficult for more than 95% of languages all over the world which are low-resourced, but collecting a relatively big unlabeled data set for such languages is more achievable. This is why some initial effort have been reported on completely unsupervised speech recognition learned from unlabeled data only, although with relatively high error rates. In this paper, we develop a Generative Adversarial Network (GAN) to achieve this purpose, in which a Generator and a Discriminator learn from each other iteratively to improve the performance. We further use a set of Hidden Markov Models (HMMs) iteratively refined from the machine generated labels to work in harmony with the GAN. The initial experiments on TIMIT data set achieve an phone error rate of 33.1%, which is 8.5% lower than the previous state-of-the-art.
Adversarial Learning of Label Dependency: A Novel Framework for Multi-class Classification
Nov 12, 2018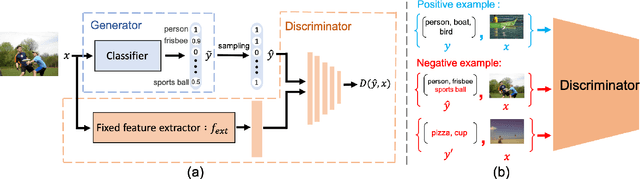



Recent work has shown that exploiting relations between labels improves the performance of multi-label classification. We propose a novel framework based on generative adversarial networks (GANs) to model label dependency. The discriminator learns to model label dependency by discriminating real and generated label sets. To fool the discriminator, the classifier, or generator, learns to generate label sets with dependencies close to real data. Extensive experiments and comparisons on two large-scale image classification benchmark datasets (MS-COCO and NUS-WIDE) show that the discriminator improves generalization ability for different kinds of models
Transcribing Lyrics From Commercial Song Audio: The First Step Towards Singing Content Processing
Apr 15, 2018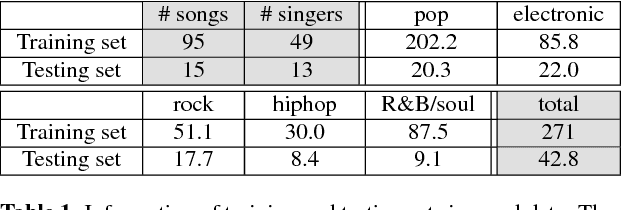
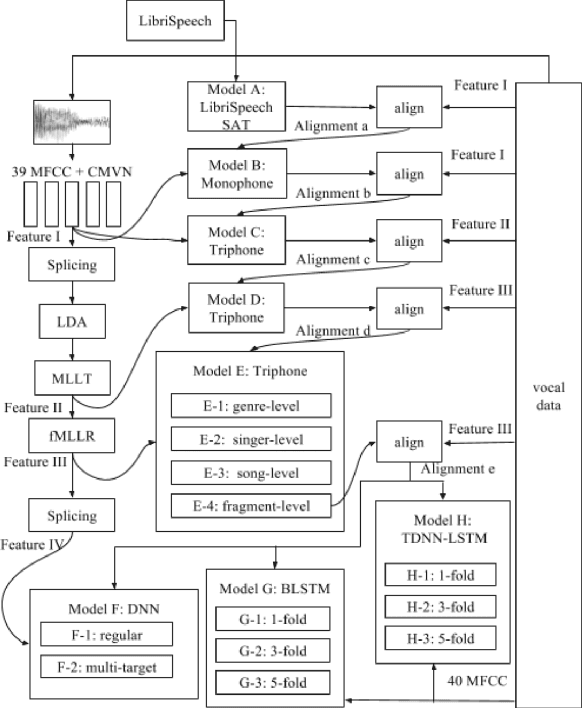
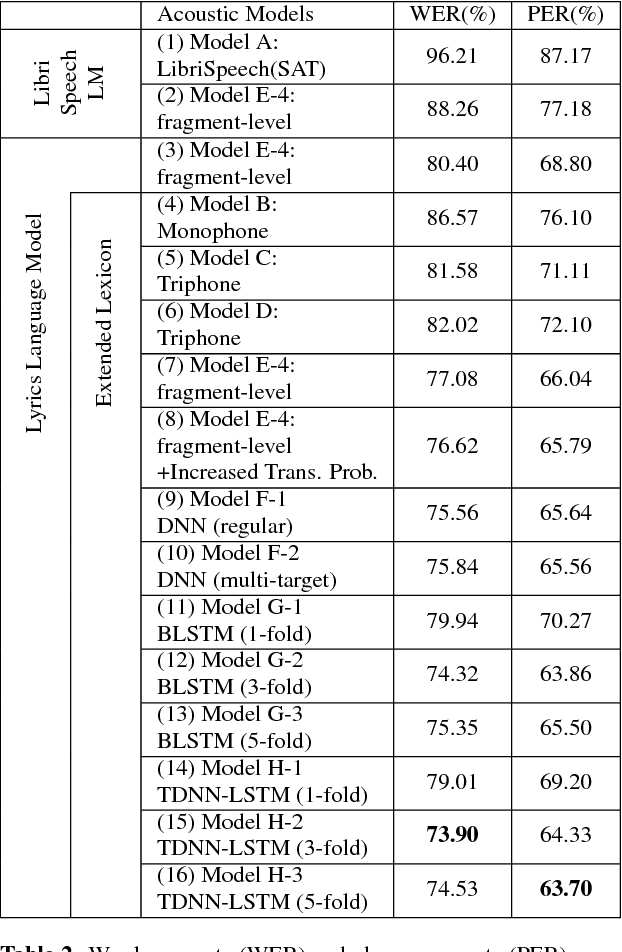
Spoken content processing (such as retrieval and browsing) is maturing, but the singing content is still almost completely left out. Songs are human voice carrying plenty of semantic information just as speech, and may be considered as a special type of speech with highly flexible prosody. The various problems in song audio, for example the significantly changing phone duration over highly flexible pitch contours, make the recognition of lyrics from song audio much more difficult. This paper reports an initial attempt towards this goal. We collected music-removed version of English songs directly from commercial singing content. The best results were obtained by TDNN-LSTM with data augmentation with 3-fold speed perturbation plus some special approaches. The WER achieved (73.90%) was significantly lower than the baseline (96.21%), but still relatively high.