 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTHeGAU: Type-Aware Heterogeneous Graph Autoencoder and Augmentation
Dec 11, 2025Heterogeneous Graph Neural Networks (HGNNs) are effective for modeling Heterogeneous Information Networks (HINs), which encode complex multi-typed entities and relations. However, HGNNs often suffer from type information loss and structural noise, limiting their representational fidelity and generalization. We propose THeGAU, a model-agnostic framework that combines a type-aware graph autoencoder with guided graph augmentation to improve node classification. THeGAU reconstructs schema-valid edges as an auxiliary task to preserve node-type semantics and introduces a decoder-driven augmentation mechanism to selectively refine noisy structures. This joint design enhances robustness, accuracy, and efficiency while significantly reducing computational overhead. Extensive experiments on three benchmark HIN datasets (IMDB, ACM, and DBLP) demonstrate that THeGAU consistently outperforms existing HGNN methods, achieving state-of-the-art performance across multiple backbones.
DMol: A Schedule-Driven Diffusion Model for Highly Efficient and Versatile Molecule Generation
Apr 08, 2025We introduce a new graph diffusion model for small molecule generation, \emph{DMol}, which outperforms the state-of-the-art DiGress model in terms of validity by roughly $1.5\%$ across all benchmarking datasets while reducing the number of diffusion steps by at least $10$-fold, and the running time to roughly one half. The performance improvements are a result of a careful change in the objective function and a ``graph noise" scheduling approach which, at each diffusion step, allows one to only change a subset of nodes of varying size in the molecule graph. Another relevant property of the method is that it can be easily combined with junction-tree-like graph representations that arise by compressing a collection of relevant ring structures into supernodes. Unlike classical junction-tree techniques that involve VAEs and require complicated reconstruction steps, compressed DMol directly performs graph diffusion on a graph that compresses only a carefully selected set of frequent carbon rings into supernodes, which results in straightforward sample generation. This compressed DMol method offers additional validity improvements over generic DMol of roughly $2\%$, increases the novelty of the method, and further improves the running time due to reductions in the graph size.
CLUE: Concept-Level Uncertainty Estimation for Large Language Models
Sep 04, 2024Large Language Models (LLMs) have demonstrated remarkable proficiency in various natural language generation (NLG) tasks. Previous studies suggest that LLMs' generation process involves uncertainty. However, existing approaches to uncertainty estimation mainly focus on sequence-level uncertainty, overlooking individual pieces of information within sequences. These methods fall short in separately assessing the uncertainty of each component in a sequence. In response, we propose a novel framework for Concept-Level Uncertainty Estimation (CLUE) for LLMs. We leverage LLMs to convert output sequences into concept-level representations, breaking down sequences into individual concepts and measuring the uncertainty of each concept separately. We conduct experiments to demonstrate that CLUE can provide more interpretable uncertainty estimation results compared with sentence-level uncertainty, and could be a useful tool for various tasks such as hallucination detection and story generation.
Let's Fuse Step by Step: A Generative Fusion Decoding Algorithm with LLMs for Multi-modal Text Recognition
May 23, 2024We introduce ``Generative Fusion Decoding'' (GFD), a novel shallow fusion framework, utilized to integrate Large Language Models (LLMs) into multi-modal text recognition systems such as automatic speech recognition (ASR) and optical character recognition (OCR). We derive the formulas necessary to enable GFD to operate across mismatched token spaces of different models by mapping text token space to byte token space, enabling seamless fusion during the decoding process. The framework is plug-and-play, compatible with various auto-regressive models, and does not require re-training for feature alignment, thus overcoming limitations of previous fusion techniques. We highlight three main advantages of GFD: First, by simplifying the complexity of aligning different model sample spaces, GFD allows LLMs to correct errors in tandem with the recognition model, reducing computation latencies. Second, the in-context learning ability of LLMs is fully capitalized by GFD, increasing robustness in long-form speech recognition and instruction aware speech recognition. Third, GFD enables fusing recognition models deficient in Chinese text recognition with LLMs extensively trained on Chinese. Our evaluation demonstrates that GFD significantly improves performance in ASR and OCR tasks, with ASR reaching state-of-the-art in the NTUML2021 benchmark. GFD provides a significant step forward in model integration, offering a unified solution that could be widely applicable to leveraging existing pre-trained models through step by step fusion.
MiniSUPERB: Lightweight Benchmark for Self-supervised Speech Models
May 30, 2023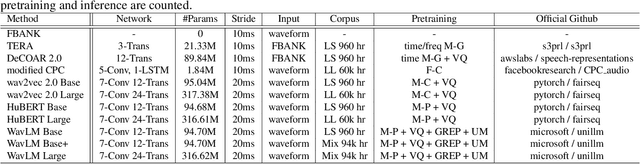
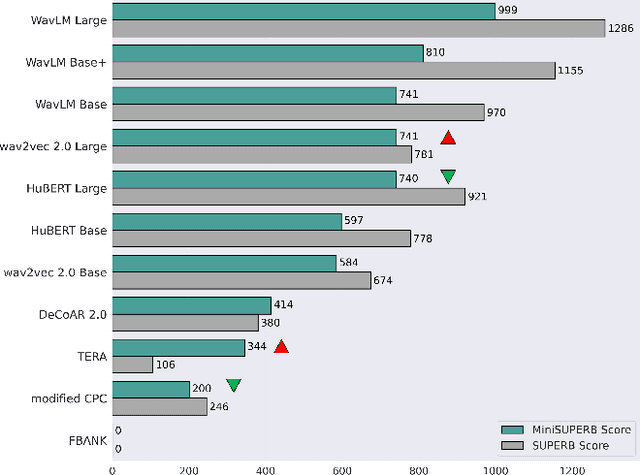


Self-supervised learning (SSL) is a popular research topic in speech processing. Successful SSL speech models must generalize well. SUPERB was proposed to evaluate the ability of SSL speech models across many speech tasks. However, due to the diversity of tasks, the evaluation process requires huge computational costs. We present MiniSUPERB, a lightweight benchmark that efficiently evaluates SSL speech models with comparable results to SUPERB while greatly reducing the computational cost. We select representative tasks and sample datasets and extract model representation offline, achieving 0.954 and 0.982 Spearman's rank correlation with SUPERB Paper and SUPERB Challenge, respectively. In the meanwhile, the computational cost is reduced by 97% in regard to MACs (number of Multiply-ACcumulate operations) in the tasks we choose. To the best of our knowledge, this is the first study to examine not only the computational cost of a model itself but the cost of evaluating it on a benchmark.
SMILEtrack: SiMIlarity LEarning for Multiple Object Tracking
Nov 17, 2022



Multiple Object Tracking (MOT) is widely investigated in computer vision with many applications. Tracking-By-Detection (TBD) is a popular multiple-object tracking paradigm. TBD consists of the first step of object detection and the subsequent of data association, tracklet generation, and update. We propose a Similarity Learning Module (SLM) motivated from the Siamese network to extract important object appearance features and a procedure to combine object motion and appearance features effectively. This design strengthens the modeling of object motion and appearance features for data association. We design a Similarity Matching Cascade (SMC) for the data association of our SMILEtrack tracker. SMILEtrack achieves 81.06 MOTA and 80.5 IDF1 on the MOTChallenge and the MOT17 test set, respectively.