 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniSUPERB: Lightweight Benchmark for Self-supervised Speech Models
Paper and Code
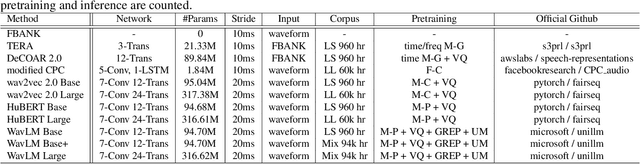
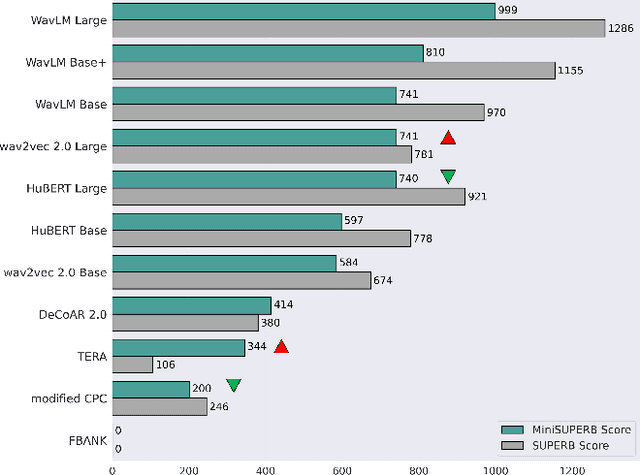


Self-supervised learning (SSL) is a popular research topic in speech processing. Successful SSL speech models must generalize well. SUPERB was proposed to evaluate the ability of SSL speech models across many speech tasks. However, due to the diversity of tasks, the evaluation process requires huge computational costs. We present MiniSUPERB, a lightweight benchmark that efficiently evaluates SSL speech models with comparable results to SUPERB while greatly reducing the computational cost. We select representative tasks and sample datasets and extract model representation offline, achieving 0.954 and 0.982 Spearman's rank correlation with SUPERB Paper and SUPERB Challenge, respectively. In the meanwhile, the computational cost is reduced by 97% in regard to MACs (number of Multiply-ACcumulate operations) in the tasks we choose. To the best of our knowledge, this is the first study to examine not only the computational cost of a model itself but the cost of evaluating it on a benchmark.