 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution Discrepancy and Feature Heterogeneity for Active 3D Object Detection
Sep 11, 2024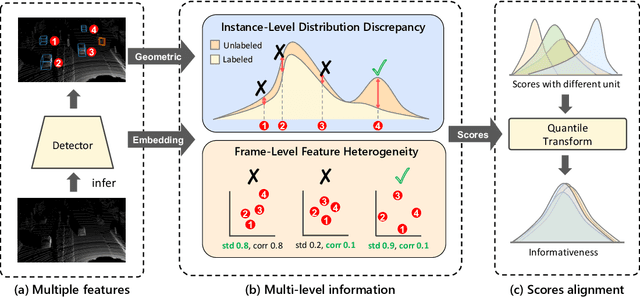

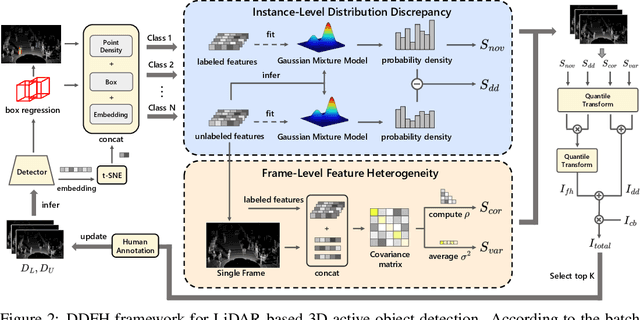
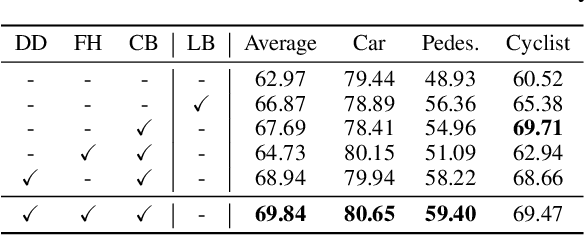
LiDAR-based 3D object detection is a critical technology for the development of autonomous driving and robotics. However, the high cost of data annotation limits its advancement. We propose a novel and effective active learning (AL) method called Distribution Discrepancy and Feature Heterogeneity (DDFH), which simultaneously considers geometric features and model embeddings, assessing information from both the instance-level and frame-level perspectives. Distribution Discrepancy evaluates the difference and novelty of instances within the unlabeled and labeled distributions, enabling the model to learn efficiently with limited data. Feature Heterogeneity ensures the heterogeneity of intra-frame instance features, maintaining feature diversity while avoiding redundant or similar instances, thus minimizing annotation costs. Finally, multiple indicators are efficiently aggregated using Quantile Transform, providing a unified measure of informativeness. Extensive experiments demonstrate that DDFH outperforms the current state-of-the-art (SOTA) methods on the KITTI and Waymo datasets, effectively reducing the bounding box annotation cost by 56.3% and showing robustness when working with both one-stage and two-stage models.
MiniSUPERB: Lightweight Benchmark for Self-supervised Speech Models
May 30, 2023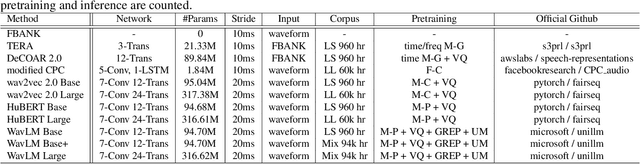
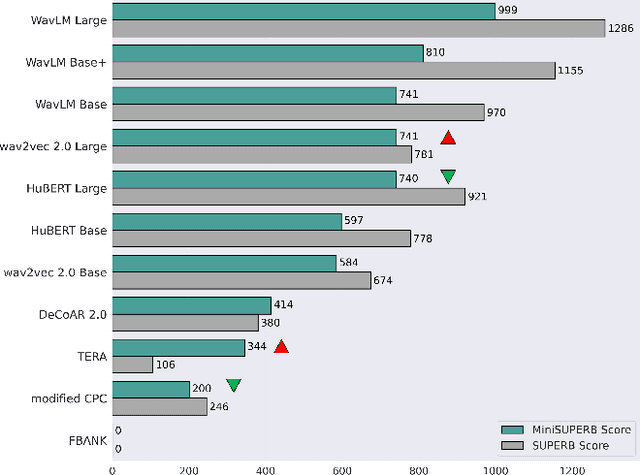


Self-supervised learning (SSL) is a popular research topic in speech processing. Successful SSL speech models must generalize well. SUPERB was proposed to evaluate the ability of SSL speech models across many speech tasks. However, due to the diversity of tasks, the evaluation process requires huge computational costs. We present MiniSUPERB, a lightweight benchmark that efficiently evaluates SSL speech models with comparable results to SUPERB while greatly reducing the computational cost. We select representative tasks and sample datasets and extract model representation offline, achieving 0.954 and 0.982 Spearman's rank correlation with SUPERB Paper and SUPERB Challenge, respectively. In the meanwhile, the computational cost is reduced by 97% in regard to MACs (number of Multiply-ACcumulate operations) in the tasks we choose. To the best of our knowledge, this is the first study to examine not only the computational cost of a model itself but the cost of evaluating it on a benchmark.