 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOT-FM: Cluster-wise Optimal Transport Flow Matching
Mar 11, 2026We introduce COT-FM, a general framework that reshapes the probability path in Flow Matching (FM) to achieve faster and more reliable generation. FM models often produce curved trajectories due to random or batchwise couplings, which increase discretization error and reduce sample quality. COT-FM fixes this by clustering target samples and assigning each cluster a dedicated source distribution obtained by reversing pretrained FM models. This divide-and-conquer strategy yields more accurate local transport and significantly straighter vector fields, all without changing the model architecture. As a plug-and-play approach, COT-FM consistently accelerates sampling and improves generation quality across 2D datasets, image generation benchmarks, and robotic manipulation tasks.
M-ErasureBench: A Comprehensive Multimodal Evaluation Benchmark for Concept Erasure in Diffusion Models
Dec 28, 2025Text-to-image diffusion models may generate harmful or copyrighted content, motivating research on concept erasure. However, existing approaches primarily focus on erasing concepts from text prompts, overlooking other input modalities that are increasingly critical in real-world applications such as image editing and personalized generation. These modalities can become attack surfaces, where erased concepts re-emerge despite defenses. To bridge this gap, we introduce M-ErasureBench, a novel multimodal evaluation framework that systematically benchmarks concept erasure methods across three input modalities: text prompts, learned embeddings, and inverted latents. For the latter two, we evaluate both white-box and black-box access, yielding five evaluation scenarios. Our analysis shows that existing methods achieve strong erasure performance against text prompts but largely fail under learned embeddings and inverted latents, with Concept Reproduction Rate (CRR) exceeding 90% in the white-box setting. To address these vulnerabilities, we propose IRECE (Inference-time Robustness Enhancement for Concept Erasure), a plug-and-play module that localizes target concepts via cross-attention and perturbs the associated latents during denoising. Experiments demonstrate that IRECE consistently restores robustness, reducing CRR by up to 40% under the most challenging white-box latent inversion scenario, while preserving visual quality. To the best of our knowledge, M-ErasureBench provides the first comprehensive benchmark of concept erasure beyond text prompts. Together with IRECE, our benchmark offers practical safeguards for building more reliable protective generative models.
BEVANet: Bilateral Efficient Visual Attention Network for Real-Time Semantic Segmentation
Aug 10, 2025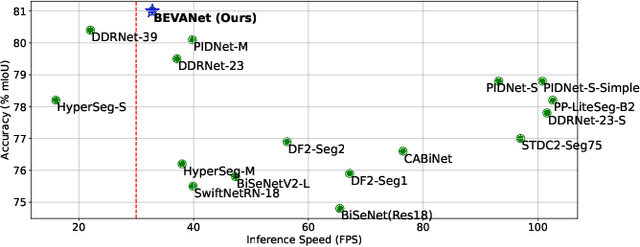



Real-time semantic segmentation presents the dual challenge of designing efficient architectures that capture large receptive fields for semantic understanding while also refining detailed contours. Vision transformers model long-range dependencies effectively but incur high computational cost. To address these challenges, we introduce the Large Kernel Attention (LKA) mechanism. Our proposed Bilateral Efficient Visual Attention Network (BEVANet) expands the receptive field to capture contextual information and extracts visual and structural features using Sparse Decomposed Large Separable Kernel Attentions (SDLSKA). The Comprehensive Kernel Selection (CKS) mechanism dynamically adapts the receptive field to further enhance performance. Furthermore, the Deep Large Kernel Pyramid Pooling Module (DLKPPM) enriches contextual features by synergistically combining dilated convolutions and large kernel attention. The bilateral architecture facilitates frequent branch communication, and the Boundary Guided Adaptive Fusion (BGAF) module enhances boundary delineation by integrating spatial and semantic features under boundary guidance. BEVANet achieves real-time segmentation at 33 FPS, yielding 79.3% mIoU without pretraining and 81.0% mIoU on Cityscapes after ImageNet pretraining, demonstrating state-of-the-art performance. The code and model is available at https://github.com/maomao0819/BEVANet.
* Copyright 2025 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
An Improved Variational Method for Image Denoising
Oct 03, 2024
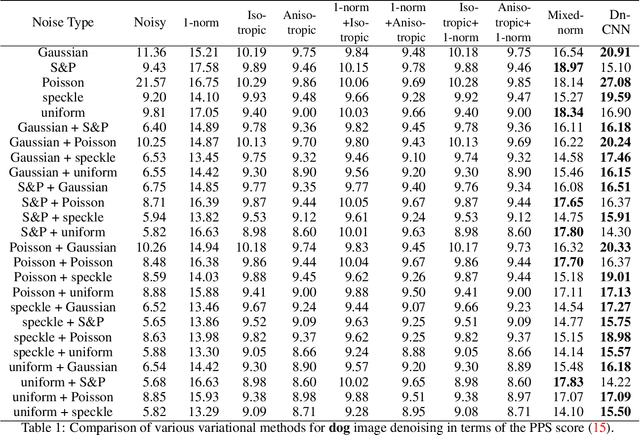
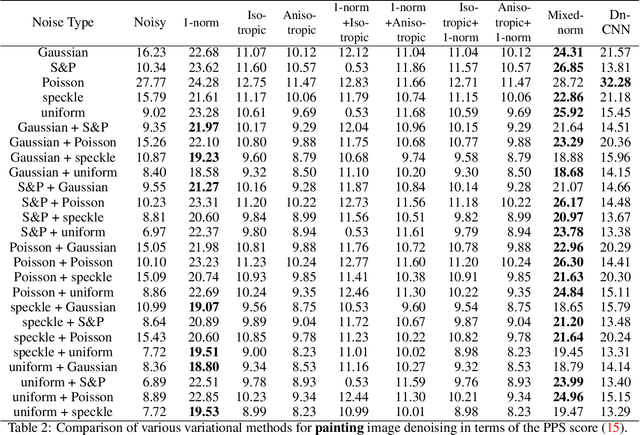

The total variation (TV) method is an image denoising technique that aims to reduce noise by minimizing the total variation of the image, which measures the variation in pixel intensities. The TV method has been widely applied in image processing and computer vision for its ability to preserve edges and enhance image quality. In this paper, we propose an improved TV model for image denoising and the associated numerical algorithm to carry out the procedure, which is particularly effective in removing several types of noises and their combinations. Our improved model admits a unique solution and the associated numerical algorithm guarantees the convergence. Numerical experiments are demonstrated to show improved effectiveness and denoising quality compared to other TV models. Such encouraging results further enhance the utility of the TV method in image processing.
Distribution Discrepancy and Feature Heterogeneity for Active 3D Object Detection
Sep 11, 2024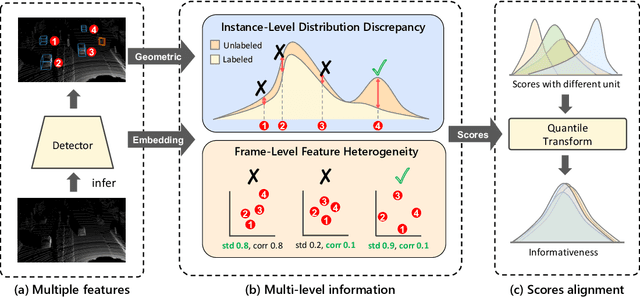

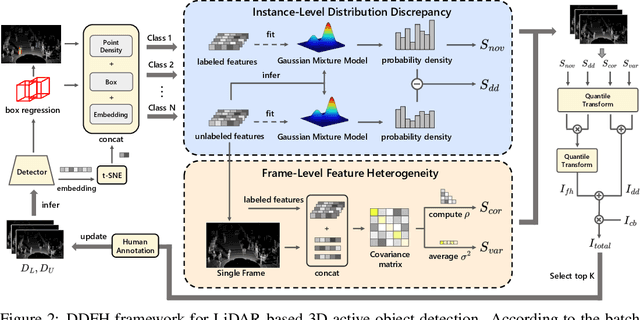
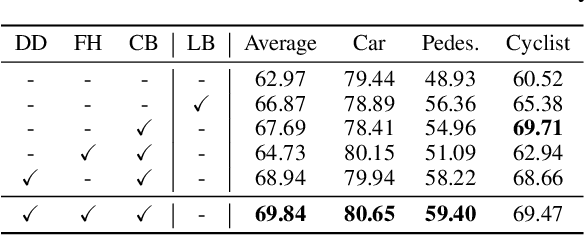
LiDAR-based 3D object detection is a critical technology for the development of autonomous driving and robotics. However, the high cost of data annotation limits its advancement. We propose a novel and effective active learning (AL) method called Distribution Discrepancy and Feature Heterogeneity (DDFH), which simultaneously considers geometric features and model embeddings, assessing information from both the instance-level and frame-level perspectives. Distribution Discrepancy evaluates the difference and novelty of instances within the unlabeled and labeled distributions, enabling the model to learn efficiently with limited data. Feature Heterogeneity ensures the heterogeneity of intra-frame instance features, maintaining feature diversity while avoiding redundant or similar instances, thus minimizing annotation costs. Finally, multiple indicators are efficiently aggregated using Quantile Transform, providing a unified measure of informativeness. Extensive experiments demonstrate that DDFH outperforms the current state-of-the-art (SOTA) methods on the KITTI and Waymo datasets, effectively reducing the bounding box annotation cost by 56.3% and showing robustness when working with both one-stage and two-stage models.
DiffQRCoder: Diffusion-based Aesthetic QR Code Generation with Scanning Robustness Guided Iterative Refinement
Sep 10, 2024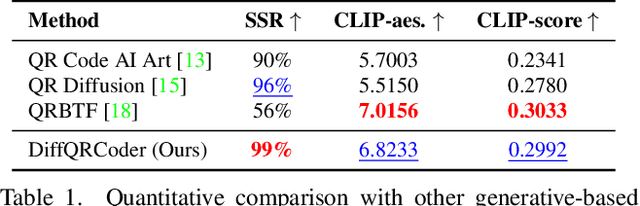


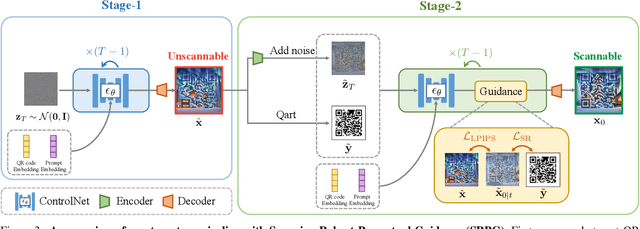
With the success of Diffusion Models for image generation, the technologies also have revolutionized the aesthetic Quick Response (QR) code generation. Despite significant improvements in visual attractiveness for the beautified codes, their scannabilities are usually sacrificed and thus hinder their practical uses in real-world scenarios. To address this issue, we propose a novel Diffusion-based QR Code generator (DiffQRCoder) to effectively craft both scannable and visually pleasing QR codes. The proposed approach introduces Scanning-Robust Perceptual Guidance (SRPG), a new diffusion guidance for Diffusion Models to guarantee the generated aesthetic codes to obey the ground-truth QR codes while maintaining their attractiveness during the denoising process. Additionally, we present another post-processing technique, Scanning Robust Manifold Projected Gradient Descent (SR-MPGD), to further enhance their scanning robustness through iterative latent space optimization. With extensive experiments, the results demonstrate that our approach not only outperforms other compared methods in Scanning Success Rate (SSR) with better or comparable CLIP aesthetic score (CLIP-aes.) but also significantly improves the SSR of the ControlNet-only approach from 60% to 99%. The subjective evaluation indicates that our approach achieves promising visual attractiveness to users as well. Finally, even with different scanning angles and the most rigorous error tolerance settings, our approach robustly achieves over 95% SSR, demonstrating its capability for real-world applications.
Pixel Is Not A Barrier: An Effective Evasion Attack for Pixel-Domain Diffusion Models
Aug 21, 2024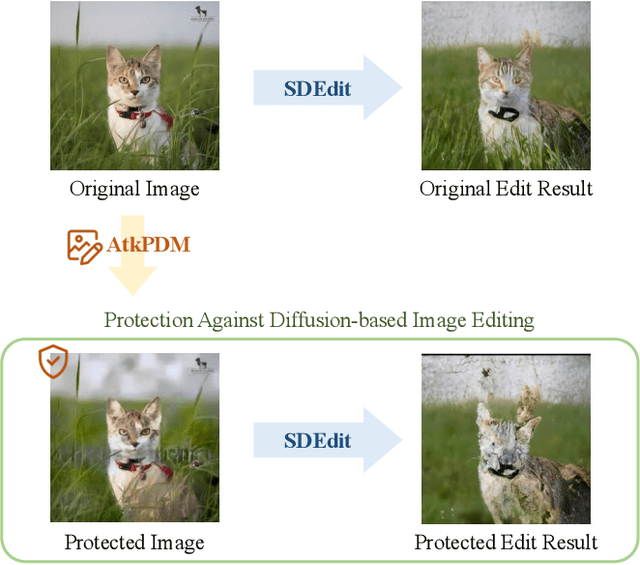
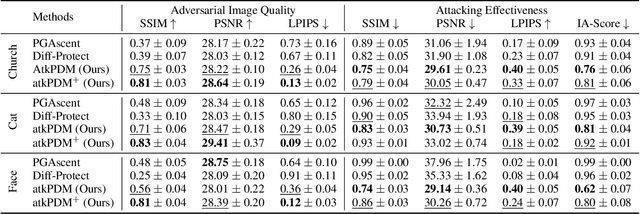
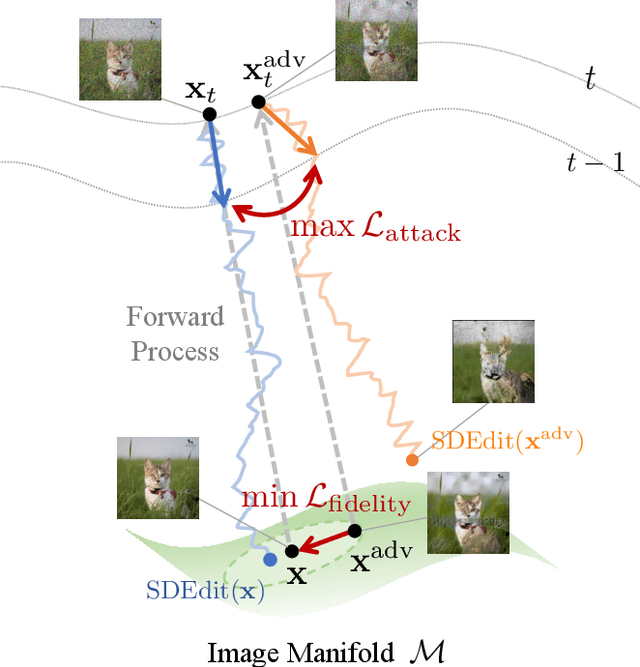
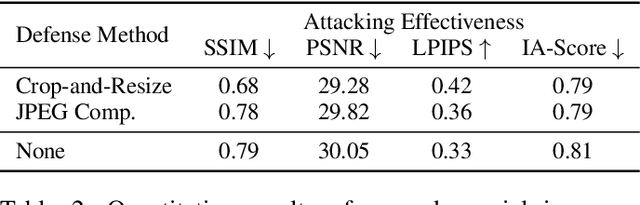
Diffusion Models have emerged as powerful generative models for high-quality image synthesis, with many subsequent image editing techniques based on them. However, the ease of text-based image editing introduces significant risks, such as malicious editing for scams or intellectual property infringement. Previous works have attempted to safeguard images from diffusion-based editing by adding imperceptible perturbations. These methods are costly and specifically target prevalent Latent Diffusion Models (LDMs), while Pixel-domain Diffusion Models (PDMs) remain largely unexplored and robust against such attacks. Our work addresses this gap by proposing a novel attacking framework with a feature representation attack loss that exploits vulnerabilities in denoising UNets and a latent optimization strategy to enhance the naturalness of protected images. Extensive experiments demonstrate the effectiveness of our approach in attacking dominant PDM-based editing methods (e.g., SDEdit) while maintaining reasonable protection fidelity and robustness against common defense methods. Additionally, our framework is extensible to LDMs, achieving comparable performance to existing approaches.
Diffusion-based Aesthetic QR Code Generation via Scanning-Robust Perceptual Guidance
Mar 23, 2024

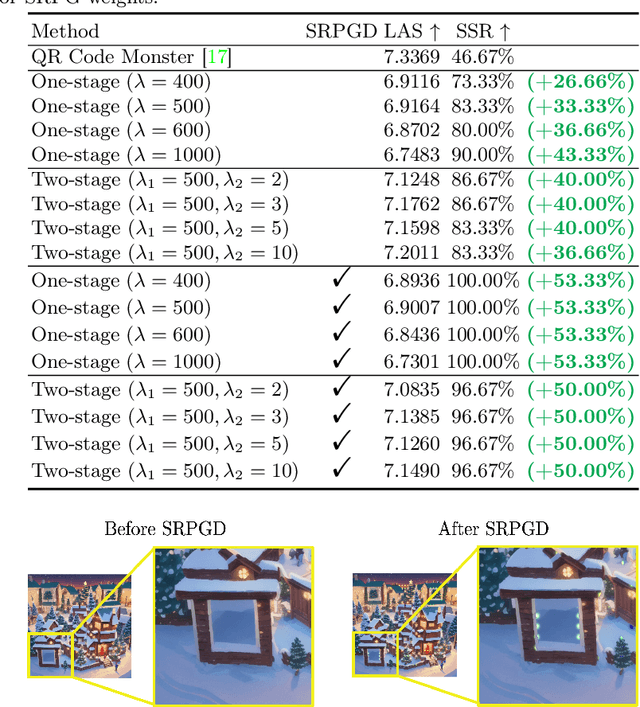
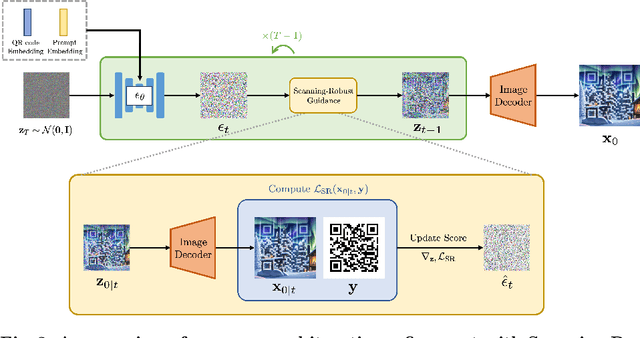
QR codes, prevalent in daily applications, lack visual appeal due to their conventional black-and-white design. Integrating aesthetics while maintaining scannability poses a challenge. In this paper, we introduce a novel diffusion-model-based aesthetic QR code generation pipeline, utilizing pre-trained ControlNet and guided iterative refinement via a novel classifier guidance (SRG) based on the proposed Scanning-Robust Loss (SRL) tailored with QR code mechanisms, which ensures both aesthetics and scannability. To further improve the scannability while preserving aesthetics, we propose a two-stage pipeline with Scanning-Robust Perceptual Guidance (SRPG). Moreover, we can further enhance the scannability of the generated QR code by post-processing it through the proposed Scanning-Robust Projected Gradient Descent (SRPGD) post-processing technique based on SRL with proven convergence. With extensive quantitative, qualitative, and subjective experiments, the results demonstrate that the proposed approach can generate diverse aesthetic QR codes with flexibility in detail. In addition, our pipelines outperforming existing models in terms of Scanning Success Rate (SSR) 86.67% (+40%) with comparable aesthetic scores. The pipeline combined with SRPGD further achieves 96.67% (+50%). Our code will be available https://github.com/jwliao1209/DiffQRCode.