 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIPER: Generalizable Factorized Fields for Joint Image Compression and Super-Resolution
Oct 23, 2024In this work, we propose a unified representation for Super-Resolution (SR) and Image Compression, termed **Factorized Fields**, motivated by the shared principles between these two tasks. Both SISR and Image Compression require recovering and preserving fine image details--whether by enhancing resolution or reconstructing compressed data. Unlike previous methods that mainly focus on network architecture, our proposed approach utilizes a basis-coefficient decomposition to explicitly capture multi-scale visual features and structural components in images, addressing the core challenges of both tasks. We first derive our SR model, which includes a Coefficient Backbone and Basis Swin Transformer for generalizable Factorized Fields. Then, to further unify these two tasks, we leverage the strong information-recovery capabilities of the trained SR modules as priors in the compression pipeline, improving both compression efficiency and detail reconstruction. Additionally, we introduce a merged-basis compression branch that consolidates shared structures, further optimizing the compression process. Extensive experiments show that our unified representation delivers state-of-the-art performance, achieving an average relative improvement of 204.4% in PSNR over the baseline in Super-Resolution (SR) and 9.35% BD-rate reduction in Image Compression compared to the previous SOTA.
Pixel Is Not A Barrier: An Effective Evasion Attack for Pixel-Domain Diffusion Models
Aug 21, 2024Diffusion Models have emerged as powerful generative models for high-quality image synthesis, with many subsequent image editing techniques based on them. However, the ease of text-based image editing introduces significant risks, such as malicious editing for scams or intellectual property infringement. Previous works have attempted to safeguard images from diffusion-based editing by adding imperceptible perturbations. These methods are costly and specifically target prevalent Latent Diffusion Models (LDMs), while Pixel-domain Diffusion Models (PDMs) remain largely unexplored and robust against such attacks. Our work addresses this gap by proposing a novel attacking framework with a feature representation attack loss that exploits vulnerabilities in denoising UNets and a latent optimization strategy to enhance the naturalness of protected images. Extensive experiments demonstrate the effectiveness of our approach in attacking dominant PDM-based editing methods (e.g., SDEdit) while maintaining reasonable protection fidelity and robustness against common defense methods. Additionally, our framework is extensible to LDMs, achieving comparable performance to existing approaches.
Deep Complex U-Net with Conformer for Audio-Visual Speech Enhancement
Sep 20, 2023Recent studies have increasingly acknowledged the advantages of incorporating visual data into speech enhancement (SE) systems. In this paper, we introduce a novel audio-visual SE approach, termed DCUC-Net (deep complex U-Net with conformer network). The proposed DCUC-Net leverages complex domain features and a stack of conformer blocks. The encoder and decoder of DCUC-Net are designed using a complex U-Net-based framework. The audio and visual signals are processed using a complex encoder and a ResNet-18 model, respectively. These processed signals are then fused using the conformer blocks and transformed into enhanced speech waveforms via a complex decoder. The conformer blocks consist of a combination of self-attention mechanisms and convolutional operations, enabling DCUC-Net to effectively capture both global and local audio-visual dependencies. Our experimental results demonstrate the effectiveness of DCUC-Net, as it outperforms the baseline model from the COG-MHEAR AVSE Challenge 2023 by a notable margin of 0.14 in terms of PESQ. Additionally, the proposed DCUC-Net performs comparably to a state-of-the-art model and outperforms all other compared models on the Taiwan Mandarin speech with video (TMSV) dataset.
MeDM: Mediating Image Diffusion Models for Video-to-Video Translation with Temporal Correspondence Guidance
Sep 01, 2023
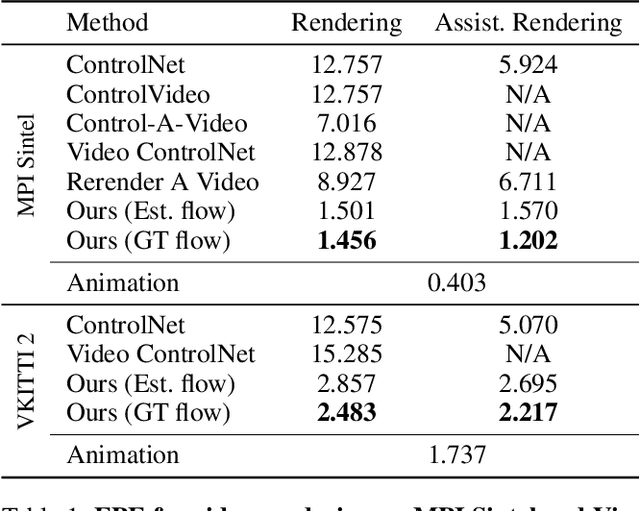
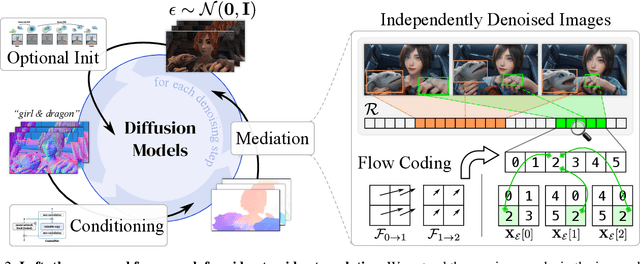
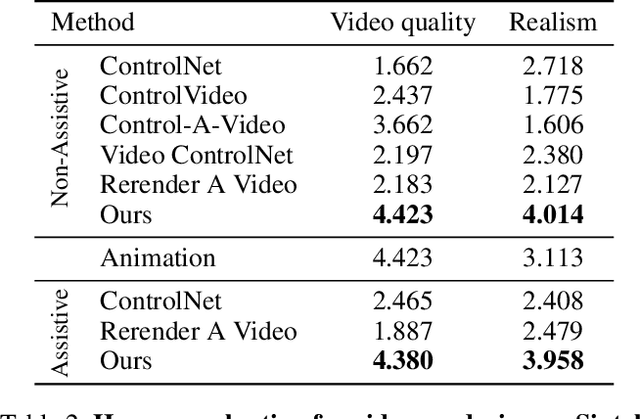
This study introduces an efficient and effective method, MeDM, that utilizes pre-trained image Diffusion Models for video-to-video translation with consistent temporal flow. The proposed framework can render videos from scene position information, such as a normal G-buffer, or perform text-guided editing on videos captured in real-world scenarios. We employ explicit optical flows to construct a practical coding that enforces physical constraints on generated frames and mediates independent frame-wise scores. By leveraging this coding, maintaining temporal consistency in the generated videos can be framed as an optimization problem with a closed-form solution. To ensure compatibility with Stable Diffusion, we also suggest a workaround for modifying observed-space scores in latent-space Diffusion Models. Notably, MeDM does not require fine-tuning or test-time optimization of the Diffusion Models. Through extensive qualitative, quantitative, and subjective experiments on various benchmarks, the study demonstrates the effectiveness and superiority of the proposed approach. Project page can be found at https://medm2023.github.io
Diffusion to Confusion: Naturalistic Adversarial Patch Generation Based on Diffusion Model for Object Detector
Jul 16, 2023

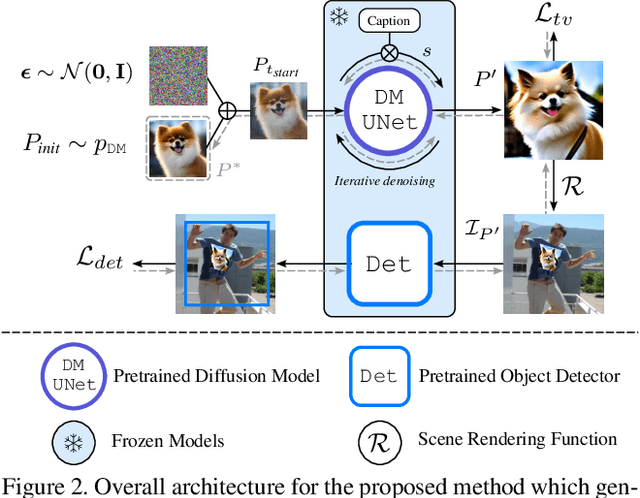

Many physical adversarial patch generation methods are widely proposed to protect personal privacy from malicious monitoring using object detectors. However, they usually fail to generate satisfactory patch images in terms of both stealthiness and attack performance without making huge efforts on careful hyperparameter tuning. To address this issue, we propose a novel naturalistic adversarial patch generation method based on the diffusion models (DM). Through sampling the optimal image from the DM model pretrained upon natural images, it allows us to stably craft high-quality and naturalistic physical adversarial patches to humans without suffering from serious mode collapse problems as other deep generative models. To the best of our knowledge, we are the first to propose DM-based naturalistic adversarial patch generation for object detectors. With extensive quantitative, qualitative, and subjective experiments, the results demonstrate the effectiveness of the proposed approach to generate better-quality and more naturalistic adversarial patches while achieving acceptable attack performance than other state-of-the-art patch generation methods. We also show various generation trade-offs under different conditions.
Video ControlNet: Towards Temporally Consistent Synthetic-to-Real Video Translation Using Conditional Image Diffusion Models
May 30, 2023
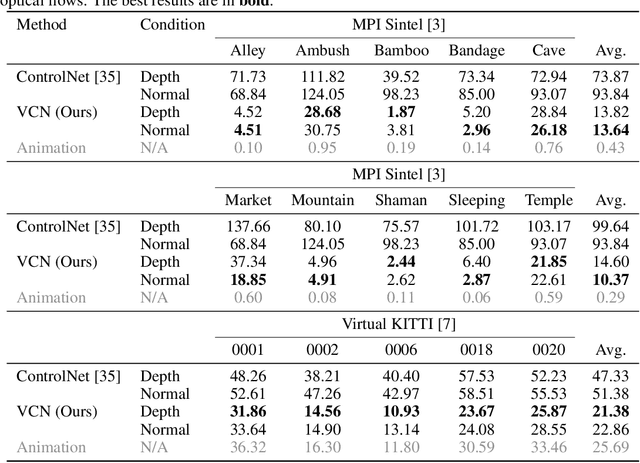
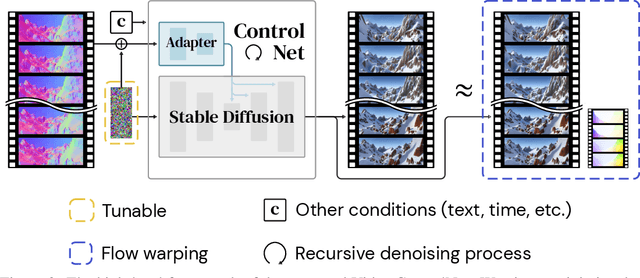

In this study, we present an efficient and effective approach for achieving temporally consistent synthetic-to-real video translation in videos of varying lengths. Our method leverages off-the-shelf conditional image diffusion models, allowing us to perform multiple synthetic-to-real image generations in parallel. By utilizing the available optical flow information from the synthetic videos, our approach seamlessly enforces temporal consistency among corresponding pixels across frames. This is achieved through joint noise optimization, effectively minimizing spatial and temporal discrepancies. To the best of our knowledge, our proposed method is the first to accomplish diverse and temporally consistent synthetic-to-real video translation using conditional image diffusion models. Furthermore, our approach does not require any training or fine-tuning of the diffusion models. Extensive experiments conducted on various benchmarks for synthetic-to-real video translation demonstrate the effectiveness of our approach, both quantitatively and qualitatively. Finally, we show that our method outperforms other baseline methods in terms of both temporal consistency and visual quality.
Audio Time-Scale Modification with Temporal Compressing Networks
Oct 31, 2022



We proposed a novel approach in the field of time-scale modification on audio signals. While traditional methods use the framing technique, spectral approach uses the short-time Fourier transform to preserve the frequency during temporal stretching. TSM-Net, our neural-network model encodes the raw audio into a high-level latent representation. We call it Neuralgram, in which one vector represents 1024 audio samples. It is inspired by the framing technique but addresses the clipping artifacts. The Neuralgram is a two-dimensional matrix with real values, we can apply some existing image resizing techniques on the Neuralgram and decode it using our neural decoder to obtain the time-scaled audio. Both the encoder and decoder are trained with GANs, which shows fair generalization ability on the scaled Neuralgrams. Our method yields little artifacts and opens a new possibility in the research of modern time-scale modification. The audio samples can be found on https://ernestchu.github.io/tsm-net-demo/