 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion to Confusion: Naturalistic Adversarial Patch Generation Based on Diffusion Model for Object Detector
Jul 16, 2023

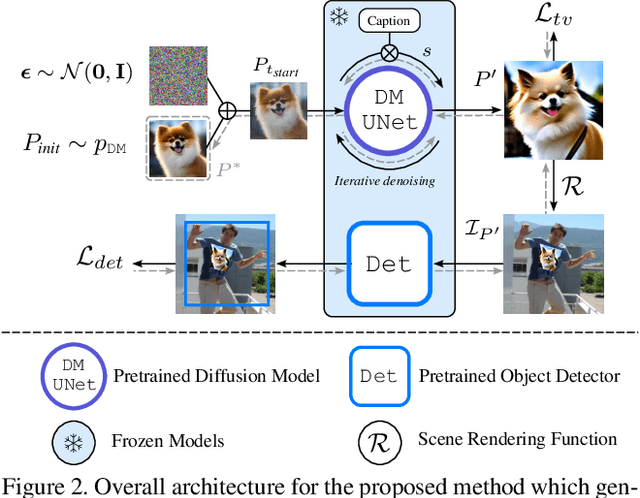

Many physical adversarial patch generation methods are widely proposed to protect personal privacy from malicious monitoring using object detectors. However, they usually fail to generate satisfactory patch images in terms of both stealthiness and attack performance without making huge efforts on careful hyperparameter tuning. To address this issue, we propose a novel naturalistic adversarial patch generation method based on the diffusion models (DM). Through sampling the optimal image from the DM model pretrained upon natural images, it allows us to stably craft high-quality and naturalistic physical adversarial patches to humans without suffering from serious mode collapse problems as other deep generative models. To the best of our knowledge, we are the first to propose DM-based naturalistic adversarial patch generation for object detectors. With extensive quantitative, qualitative, and subjective experiments, the results demonstrate the effectiveness of the proposed approach to generate better-quality and more naturalistic adversarial patches while achieving acceptable attack performance than other state-of-the-art patch generation methods. We also show various generation trade-offs under different conditions.
A Novel Self-Knowledge Distillation Approach with Siamese Representation Learning for Action Recognition
Sep 03, 2022
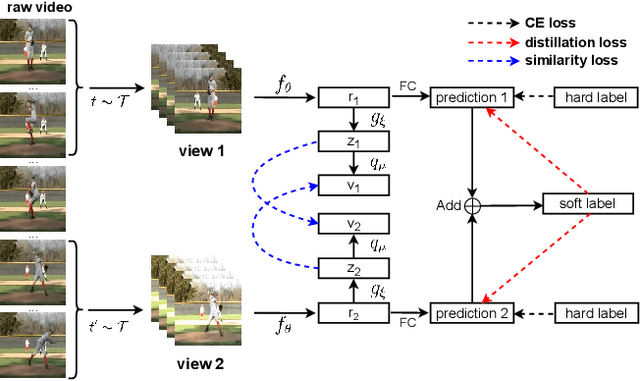


Knowledge distillation is an effective transfer of knowledge from a heavy network (teacher) to a small network (student) to boost students' performance. Self-knowledge distillation, the special case of knowledge distillation, has been proposed to remove the large teacher network training process while preserving the student's performance. This paper introduces a novel Self-knowledge distillation approach via Siamese representation learning, which minimizes the difference between two representation vectors of the two different views from a given sample. Our proposed method, SKD-SRL, utilizes both soft label distillation and the similarity of representation vectors. Therefore, SKD-SRL can generate more consistent predictions and representations in various views of the same data point. Our benchmark has been evaluated on various standard datasets. The experimental results have shown that SKD-SRL significantly improves the accuracy compared to existing supervised learning and knowledge distillation methods regardless of the networks.
Self-Supervised Learning via multi-Transformation Classification for Action Recognition
Feb 20, 2021
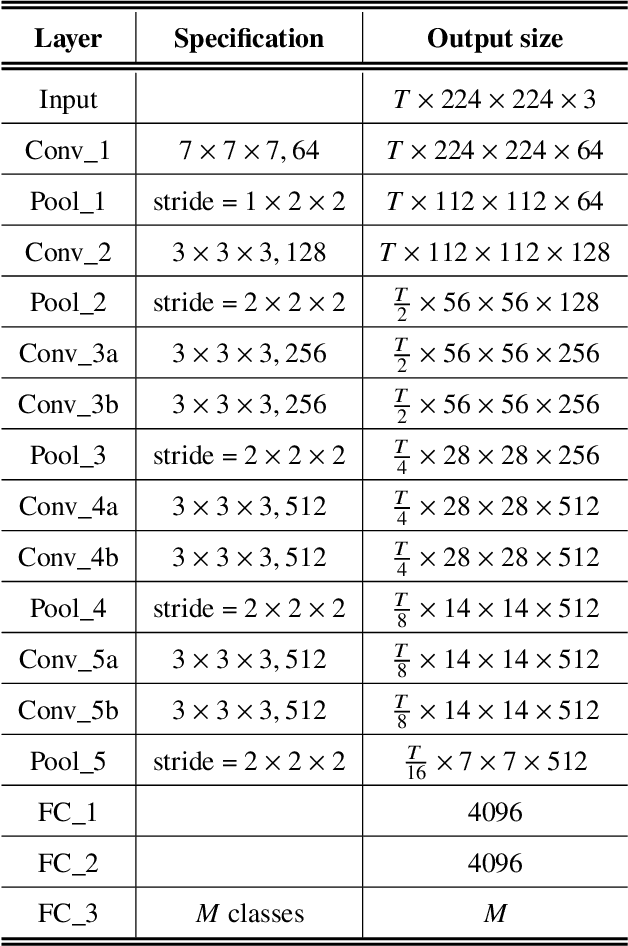

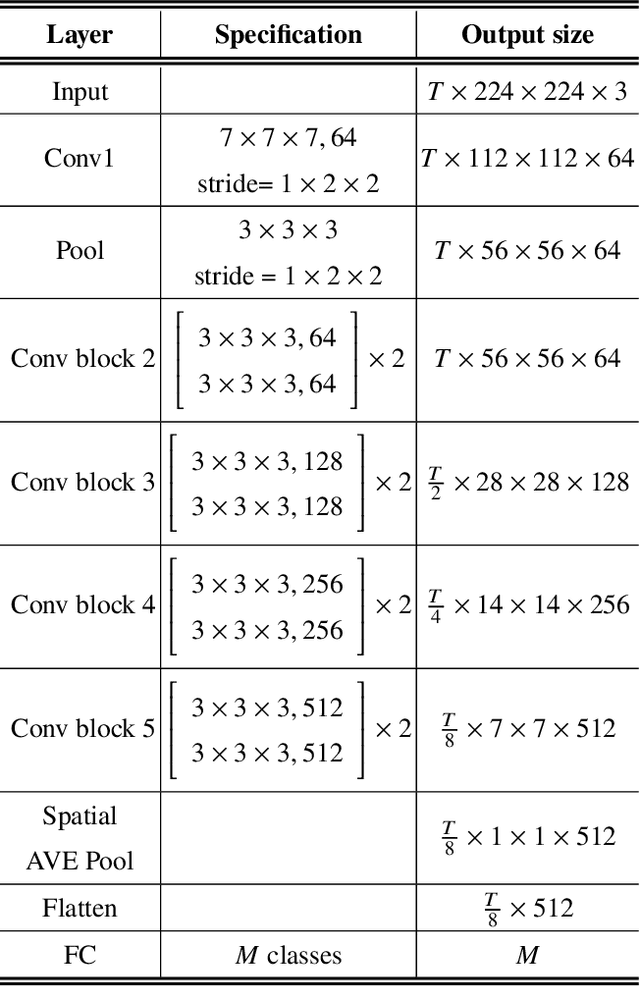
Self-supervised tasks have been utilized to build useful representations that can be used in downstream tasks when the annotation is unavailable. In this paper, we introduce a self-supervised video representation learning method based on the multi-transformation classification to efficiently classify human actions. Self-supervised learning on various transformations not only provides richer contextual information but also enables the visual representation more robust to the transforms. The spatio-temporal representation of the video is learned in a self-supervised manner by classifying seven different transformations i.e. rotation, clip inversion, permutation, split, join transformation, color switch, frame replacement, noise addition. First, seven different video transformations are applied to video clips. Then the 3D convolutional neural networks are utilized to extract features for clips and these features are processed to classify the pseudo-labels. We use the learned models in pretext tasks as the pre-trained models and fine-tune them to recognize human actions in the downstream task. We have conducted the experiments on UCF101 and HMDB51 datasets together with C3D and 3D Resnet-18 as backbone networks. The experimental results have shown that our proposed framework is outperformed other SOTA self-supervised action recognition approaches. The code will be made publicly available.
Complex Matrix Factorization for Face Recognition
Dec 08, 2016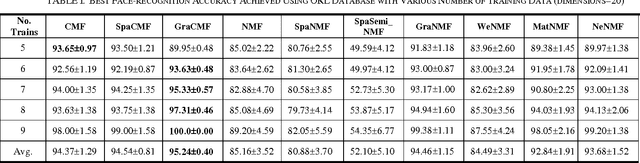
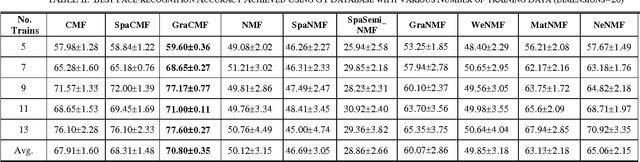
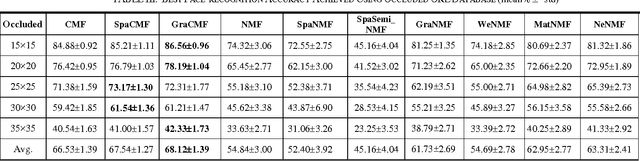
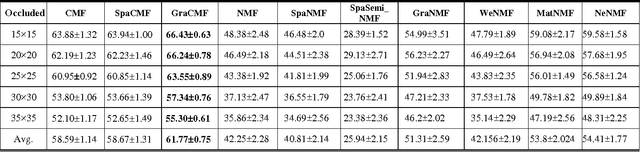
This work developed novel complex matrix factorization methods for face recognition; the methods were complex matrix factorization (CMF), sparse complex matrix factorization (SpaCMF), and graph complex matrix factorization (GraCMF). After real-valued data are transformed into a complex field, the complex-valued matrix will be decomposed into two matrices of bases and coefficients, which are derived from solutions to an optimization problem in a complex domain. The generated objective function is the real-valued function of the reconstruction error, which produces a parametric description. Factorizing the matrix of complex entries directly transformed the constrained optimization problem into an unconstrained optimization problem. Additionally, a complex vector space with N dimensions can be regarded as a 2N-dimensional real vector space. Accordingly, all real analytic properties can be exploited in the complex field. The ability to exploit these important characteristics motivated the development herein of a simpler framework that can provide better recognition results. The effectiveness of this framework will be clearly elucidated in later sections in this paper.