 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeDM: Mediating Image Diffusion Models for Video-to-Video Translation with Temporal Correspondence Guidance
Sep 01, 2023
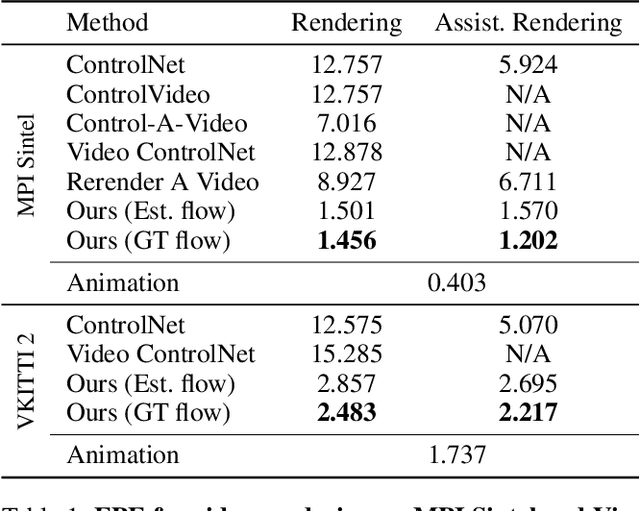
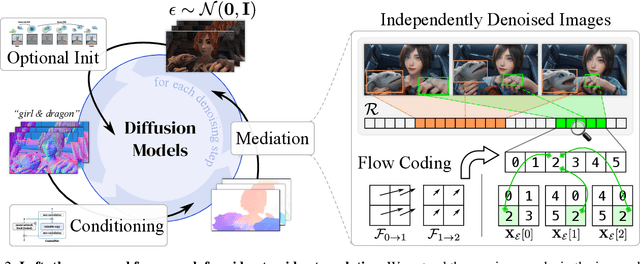
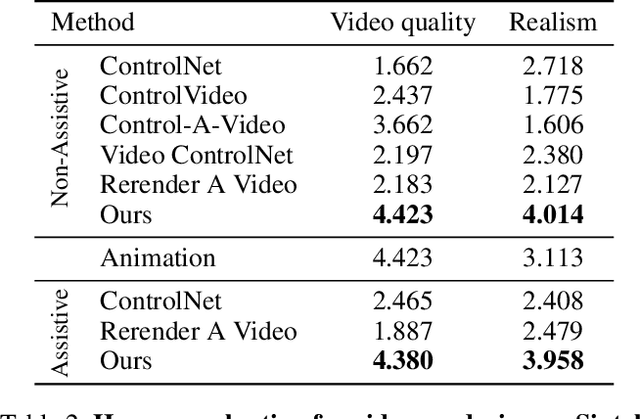
This study introduces an efficient and effective method, MeDM, that utilizes pre-trained image Diffusion Models for video-to-video translation with consistent temporal flow. The proposed framework can render videos from scene position information, such as a normal G-buffer, or perform text-guided editing on videos captured in real-world scenarios. We employ explicit optical flows to construct a practical coding that enforces physical constraints on generated frames and mediates independent frame-wise scores. By leveraging this coding, maintaining temporal consistency in the generated videos can be framed as an optimization problem with a closed-form solution. To ensure compatibility with Stable Diffusion, we also suggest a workaround for modifying observed-space scores in latent-space Diffusion Models. Notably, MeDM does not require fine-tuning or test-time optimization of the Diffusion Models. Through extensive qualitative, quantitative, and subjective experiments on various benchmarks, the study demonstrates the effectiveness and superiority of the proposed approach. Project page can be found at https://medm2023.github.io
Diffusion to Confusion: Naturalistic Adversarial Patch Generation Based on Diffusion Model for Object Detector
Jul 16, 2023

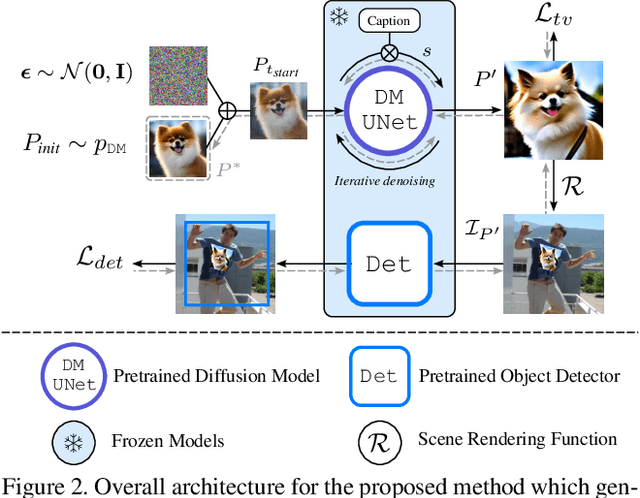

Many physical adversarial patch generation methods are widely proposed to protect personal privacy from malicious monitoring using object detectors. However, they usually fail to generate satisfactory patch images in terms of both stealthiness and attack performance without making huge efforts on careful hyperparameter tuning. To address this issue, we propose a novel naturalistic adversarial patch generation method based on the diffusion models (DM). Through sampling the optimal image from the DM model pretrained upon natural images, it allows us to stably craft high-quality and naturalistic physical adversarial patches to humans without suffering from serious mode collapse problems as other deep generative models. To the best of our knowledge, we are the first to propose DM-based naturalistic adversarial patch generation for object detectors. With extensive quantitative, qualitative, and subjective experiments, the results demonstrate the effectiveness of the proposed approach to generate better-quality and more naturalistic adversarial patches while achieving acceptable attack performance than other state-of-the-art patch generation methods. We also show various generation trade-offs under different conditions.
Video ControlNet: Towards Temporally Consistent Synthetic-to-Real Video Translation Using Conditional Image Diffusion Models
May 30, 2023
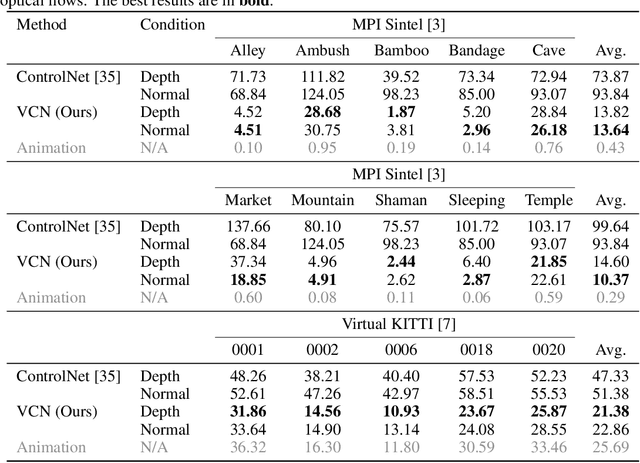
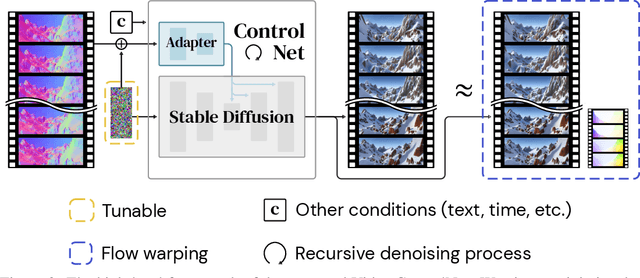

In this study, we present an efficient and effective approach for achieving temporally consistent synthetic-to-real video translation in videos of varying lengths. Our method leverages off-the-shelf conditional image diffusion models, allowing us to perform multiple synthetic-to-real image generations in parallel. By utilizing the available optical flow information from the synthetic videos, our approach seamlessly enforces temporal consistency among corresponding pixels across frames. This is achieved through joint noise optimization, effectively minimizing spatial and temporal discrepancies. To the best of our knowledge, our proposed method is the first to accomplish diverse and temporally consistent synthetic-to-real video translation using conditional image diffusion models. Furthermore, our approach does not require any training or fine-tuning of the diffusion models. Extensive experiments conducted on various benchmarks for synthetic-to-real video translation demonstrate the effectiveness of our approach, both quantitatively and qualitatively. Finally, we show that our method outperforms other baseline methods in terms of both temporal consistency and visual quality.