 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning via multi-Transformation Classification for Action Recognition
Paper and Code
Feb 20, 2021
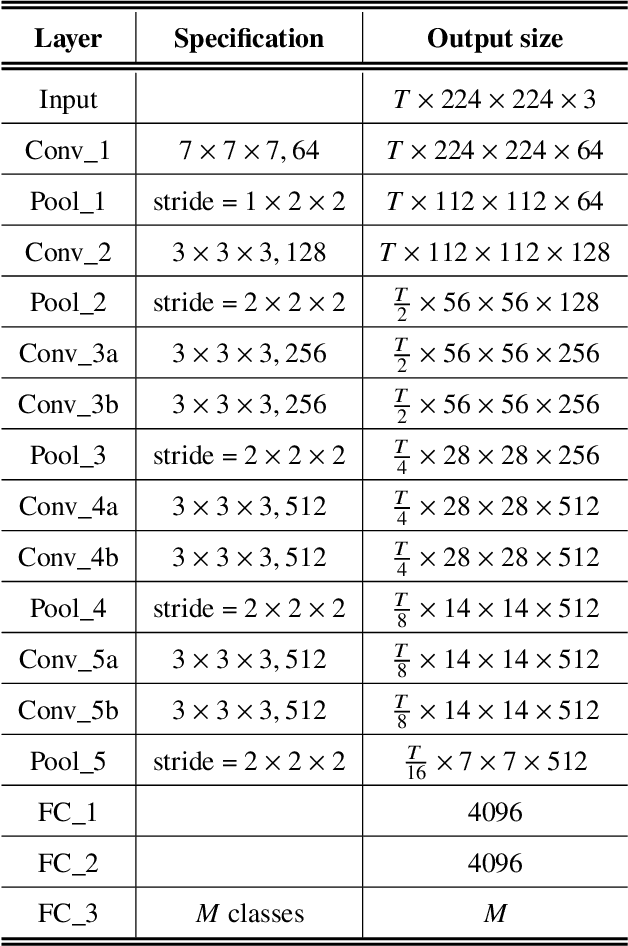

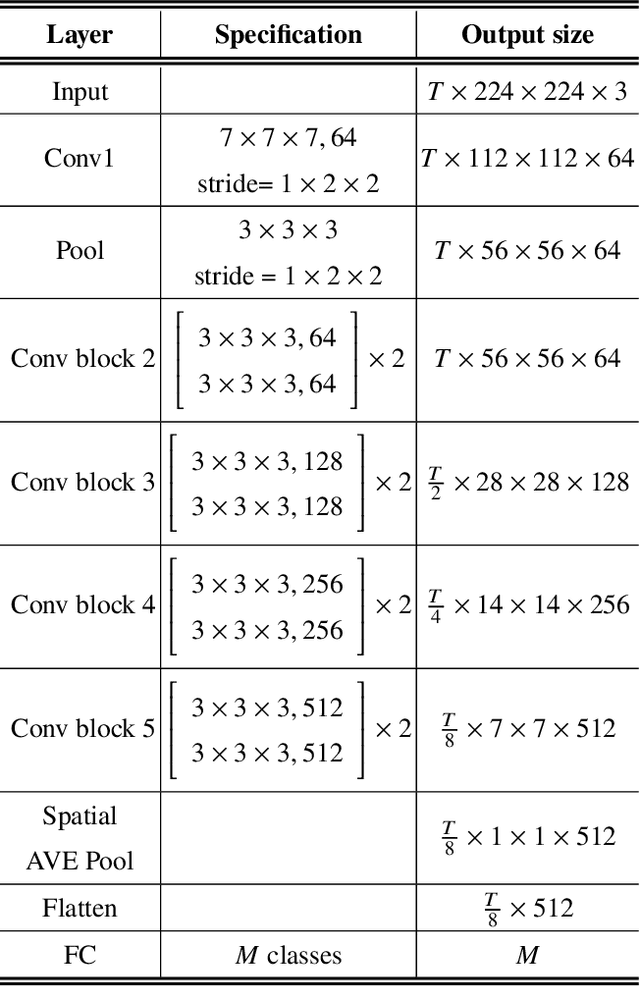
Self-supervised tasks have been utilized to build useful representations that can be used in downstream tasks when the annotation is unavailable. In this paper, we introduce a self-supervised video representation learning method based on the multi-transformation classification to efficiently classify human actions. Self-supervised learning on various transformations not only provides richer contextual information but also enables the visual representation more robust to the transforms. The spatio-temporal representation of the video is learned in a self-supervised manner by classifying seven different transformations i.e. rotation, clip inversion, permutation, split, join transformation, color switch, frame replacement, noise addition. First, seven different video transformations are applied to video clips. Then the 3D convolutional neural networks are utilized to extract features for clips and these features are processed to classify the pseudo-labels. We use the learned models in pretext tasks as the pre-trained models and fine-tune them to recognize human actions in the downstream task. We have conducted the experiments on UCF101 and HMDB51 datasets together with C3D and 3D Resnet-18 as backbone networks. The experimental results have shown that our proposed framework is outperformed other SOTA self-supervised action recognition approaches. The code will be made publicly available.