 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReF-LDM: A Latent Diffusion Model for Reference-based Face Image Restoration
Dec 06, 2024While recent works on blind face image restoration have successfully produced impressive high-quality (HQ) images with abundant details from low-quality (LQ) input images, the generated content may not accurately reflect the real appearance of a person. To address this problem, incorporating well-shot personal images as additional reference inputs could be a promising strategy. Inspired by the recent success of the Latent Diffusion Model (LDM), we propose ReF-LDM, an adaptation of LDM designed to generate HQ face images conditioned on one LQ image and multiple HQ reference images. Our model integrates an effective and efficient mechanism, CacheKV, to leverage the reference images during the generation process. Additionally, we design a timestep-scaled identity loss, enabling our LDM-based model to focus on learning the discriminating features of human faces. Lastly, we construct FFHQ-Ref, a dataset consisting of 20,405 high-quality (HQ) face images with corresponding reference images, which can serve as both training and evaluation data for reference-based face restoration models.
Audio Time-Scale Modification with Temporal Compressing Networks
Oct 31, 2022



We proposed a novel approach in the field of time-scale modification on audio signals. While traditional methods use the framing technique, spectral approach uses the short-time Fourier transform to preserve the frequency during temporal stretching. TSM-Net, our neural-network model encodes the raw audio into a high-level latent representation. We call it Neuralgram, in which one vector represents 1024 audio samples. It is inspired by the framing technique but addresses the clipping artifacts. The Neuralgram is a two-dimensional matrix with real values, we can apply some existing image resizing techniques on the Neuralgram and decode it using our neural decoder to obtain the time-scaled audio. Both the encoder and decoder are trained with GANs, which shows fair generalization ability on the scaled Neuralgrams. Our method yields little artifacts and opens a new possibility in the research of modern time-scale modification. The audio samples can be found on https://ernestchu.github.io/tsm-net-demo/
Denoising Likelihood Score Matching for Conditional Score-based Data Generation
Mar 27, 2022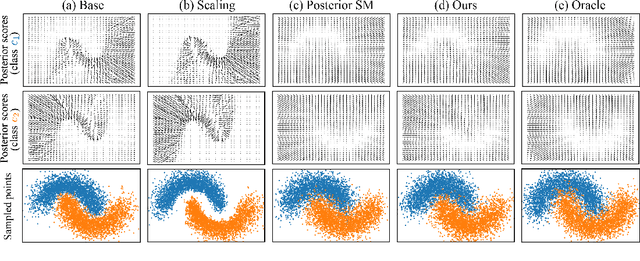
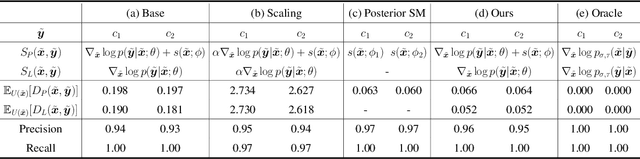

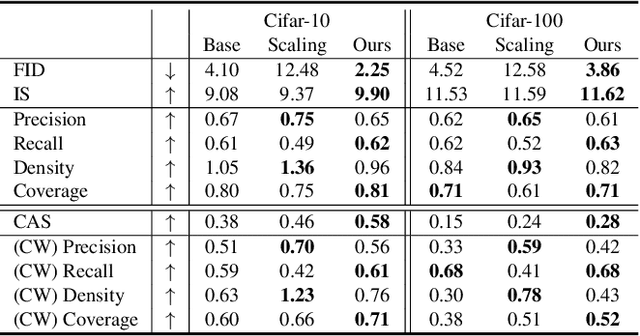
Many existing conditional score-based data generation methods utilize Bayes' theorem to decompose the gradients of a log posterior density into a mixture of scores. These methods facilitate the training procedure of conditional score models, as a mixture of scores can be separately estimated using a score model and a classifier. However, our analysis indicates that the training objectives for the classifier in these methods may lead to a serious score mismatch issue, which corresponds to the situation that the estimated scores deviate from the true ones. Such an issue causes the samples to be misled by the deviated scores during the diffusion process, resulting in a degraded sampling quality. To resolve it, we formulate a novel training objective, called Denoising Likelihood Score Matching (DLSM) loss, for the classifier to match the gradients of the true log likelihood density. Our experimental evidence shows that the proposed method outperforms the previous methods on both Cifar-10 and Cifar-100 benchmarks noticeably in terms of several key evaluation metrics. We thus conclude that, by adopting DLSM, the conditional scores can be accurately modeled, and the effect of the score mismatch issue is alleviated.
Bridging Unsupervised and Supervised Depth from Focus via All-in-Focus Supervision
Aug 24, 2021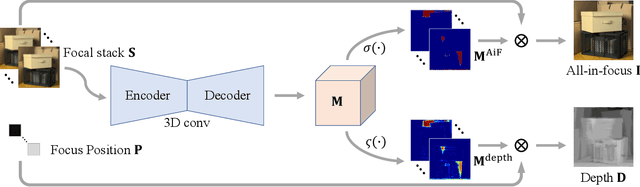

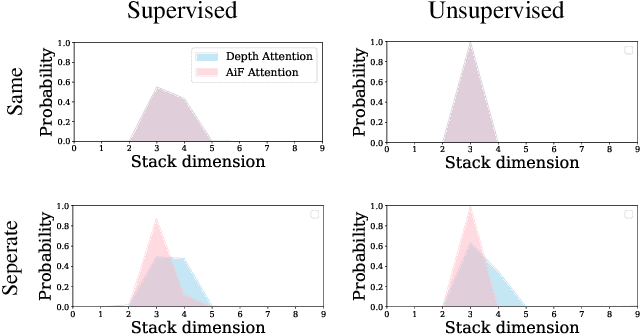
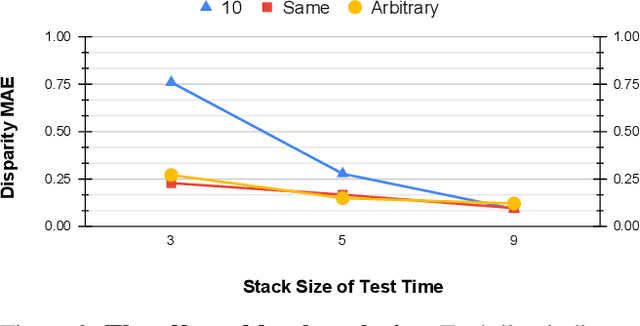
Depth estimation is a long-lasting yet important task in computer vision. Most of the previous works try to estimate depth from input images and assume images are all-in-focus (AiF), which is less common in real-world applications. On the other hand, a few works take defocus blur into account and consider it as another cue for depth estimation. In this paper, we propose a method to estimate not only a depth map but an AiF image from a set of images with different focus positions (known as a focal stack). We design a shared architecture to exploit the relationship between depth and AiF estimation. As a result, the proposed method can be trained either supervisedly with ground truth depth, or \emph{unsupervisedly} with AiF images as supervisory signals. We show in various experiments that our method outperforms the state-of-the-art methods both quantitatively and qualitatively, and also has higher efficiency in inference time.
CLCC: Contrastive Learning for Color Constancy
Jun 09, 2021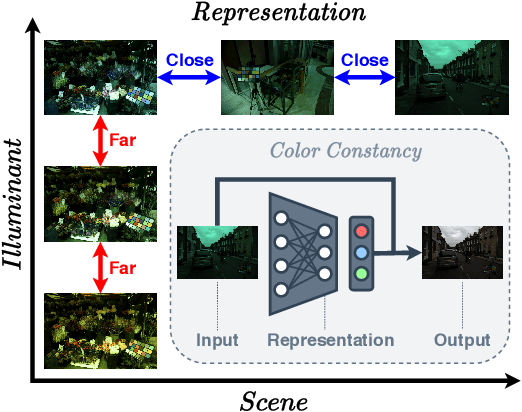
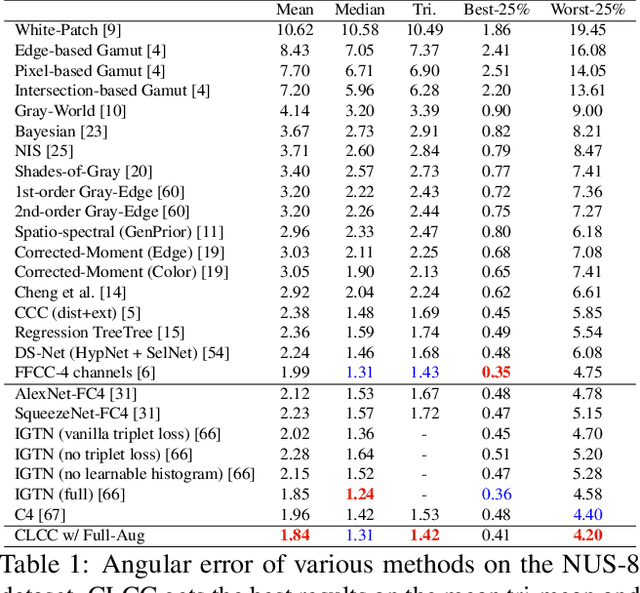
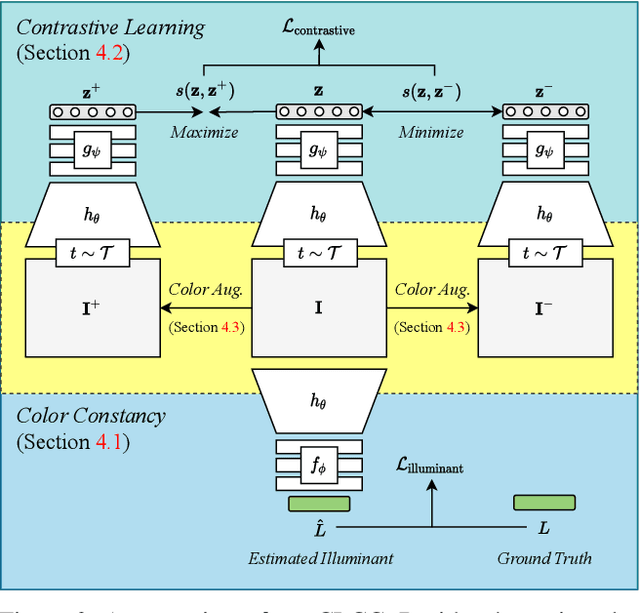
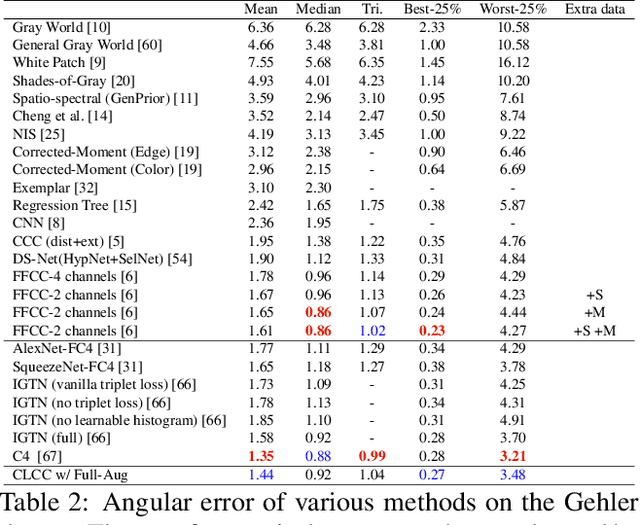
In this paper, we present CLCC, a novel contrastive learning framework for color constancy. Contrastive learning has been applied for learning high-quality visual representations for image classification. One key aspect to yield useful representations for image classification is to design illuminant invariant augmentations. However, the illuminant invariant assumption conflicts with the nature of the color constancy task, which aims to estimate the illuminant given a raw image. Therefore, we construct effective contrastive pairs for learning better illuminant-dependent features via a novel raw-domain color augmentation. On the NUS-8 dataset, our method provides $17.5\%$ relative improvements over a strong baseline, reaching state-of-the-art performance without increasing model complexity. Furthermore, our method achieves competitive performance on the Gehler dataset with $3\times$ fewer parameters compared to top-ranking deep learning methods. More importantly, we show that our model is more robust to different scenes under close proximity of illuminants, significantly reducing $28.7\%$ worst-case error in data-sparse regions.
Explorable Tone Mapping Operators
Oct 20, 2020
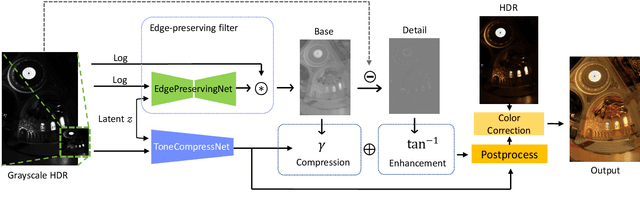


Tone-mapping plays an essential role in high dynamic range (HDR) imaging. It aims to preserve visual information of HDR images in a medium with a limited dynamic range. Although many works have been proposed to provide tone-mapped results from HDR images, most of them can only perform tone-mapping in a single pre-designed way. However, the subjectivity of tone-mapping quality varies from person to person, and the preference of tone-mapping style also differs from application to application. In this paper, a learning-based multimodal tone-mapping method is proposed, which not only achieves excellent visual quality but also explores the style diversity. Based on the framework of BicycleGAN, the proposed method can provide a variety of expert-level tone-mapped results by manipulating different latent codes. Finally, we show that the proposed method performs favorably against state-of-the-art tone-mapping algorithms both quantitatively and qualitatively.
Learning Camera-Aware Noise Models
Aug 21, 2020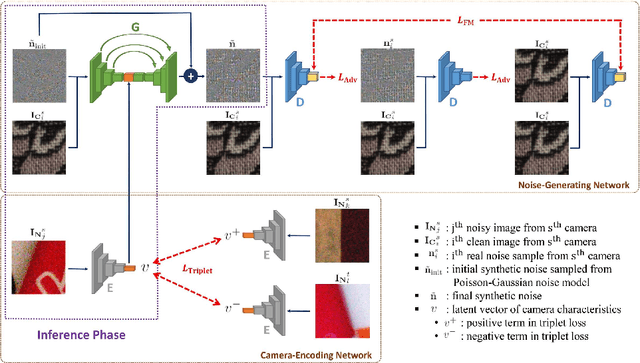

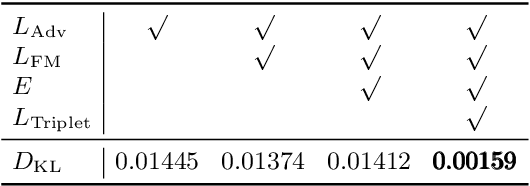

Modeling imaging sensor noise is a fundamental problem for image processing and computer vision applications. While most previous works adopt statistical noise models, real-world noise is far more complicated and beyond what these models can describe. To tackle this issue, we propose a data-driven approach, where a generative noise model is learned from real-world noise. The proposed noise model is camera-aware, that is, different noise characteristics of different camera sensors can be learned simultaneously, and a single learned noise model can generate different noise for different camera sensors. Experimental results show that our method quantitatively and qualitatively outperforms existing statistical noise models and learning-based methods.