 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStream-DiffVSR: Low-Latency Streamable Video Super-Resolution via Auto-Regressive Diffusion
Dec 29, 2025Diffusion-based video super-resolution (VSR) methods achieve strong perceptual quality but remain impractical for latency-sensitive settings due to reliance on future frames and expensive multi-step denoising. We propose Stream-DiffVSR, a causally conditioned diffusion framework for efficient online VSR. Operating strictly on past frames, it combines a four-step distilled denoiser for fast inference, an Auto-regressive Temporal Guidance (ARTG) module that injects motion-aligned cues during latent denoising, and a lightweight temporal-aware decoder with a Temporal Processor Module (TPM) that enhances detail and temporal coherence. Stream-DiffVSR processes 720p frames in 0.328 seconds on an RTX4090 GPU and significantly outperforms prior diffusion-based methods. Compared with the online SOTA TMP, it boosts perceptual quality (LPIPS +0.095) while reducing latency by over 130x. Stream-DiffVSR achieves the lowest latency reported for diffusion-based VSR, reducing initial delay from over 4600 seconds to 0.328 seconds, thereby making it the first diffusion VSR method suitable for low-latency online deployment. Project page: https://jamichss.github.io/stream-diffvsr-project-page/
Zero-shot Adaptation of Stable Diffusion via Plug-in Hierarchical Degradation Representation for Real-World Super-Resolution
Dec 11, 2025Real-World Image Super-Resolution (Real-ISR) aims to recover high-quality images from low-quality inputs degraded by unknown and complex real-world factors. Real-world scenarios involve diverse and coupled degradations, making it necessary to provide diffusion models with richer and more informative guidance. However, existing methods often assume known degradation severity and rely on CLIP text encoders that cannot capture numerical severity, limiting their generalization ability. To address this, we propose \textbf{HD-CLIP} (\textbf{H}ierarchical \textbf{D}egradation CLIP), which decomposes a low-quality image into a semantic embedding and an ordinal degradation embedding that captures ordered relationships and allows interpolation across unseen levels. Furthermore, we integrated it into diffusion models via classifier-free guidance (CFG) and proposed classifier-free projection guidance (CFPG). HD-CLIP leverages semantic cues to guide generative restoration while using degradation cues to suppress undesired hallucinations and artifacts. As a \textbf{plug-and-play module}, HD-CLIP can be seamlessly integrated into various super-resolution frameworks without training, significantly improving detail fidelity and perceptual realism across diverse real-world datasets.
ReF-LDM: A Latent Diffusion Model for Reference-based Face Image Restoration
Dec 06, 2024While recent works on blind face image restoration have successfully produced impressive high-quality (HQ) images with abundant details from low-quality (LQ) input images, the generated content may not accurately reflect the real appearance of a person. To address this problem, incorporating well-shot personal images as additional reference inputs could be a promising strategy. Inspired by the recent success of the Latent Diffusion Model (LDM), we propose ReF-LDM, an adaptation of LDM designed to generate HQ face images conditioned on one LQ image and multiple HQ reference images. Our model integrates an effective and efficient mechanism, CacheKV, to leverage the reference images during the generation process. Additionally, we design a timestep-scaled identity loss, enabling our LDM-based model to focus on learning the discriminating features of human faces. Lastly, we construct FFHQ-Ref, a dataset consisting of 20,405 high-quality (HQ) face images with corresponding reference images, which can serve as both training and evaluation data for reference-based face restoration models.
DiffIR2VR-Zero: Zero-Shot Video Restoration with Diffusion-based Image Restoration Models
Jul 01, 2024This paper introduces a method for zero-shot video restoration using pre-trained image restoration diffusion models. Traditional video restoration methods often need retraining for different settings and struggle with limited generalization across various degradation types and datasets. Our approach uses a hierarchical token merging strategy for keyframes and local frames, combined with a hybrid correspondence mechanism that blends optical flow and feature-based nearest neighbor matching (latent merging). We show that our method not only achieves top performance in zero-shot video restoration but also significantly surpasses trained models in generalization across diverse datasets and extreme degradations (8$\times$ super-resolution and high-standard deviation video denoising). We present evidence through quantitative metrics and visual comparisons on various challenging datasets. Additionally, our technique works with any 2D restoration diffusion model, offering a versatile and powerful tool for video enhancement tasks without extensive retraining. This research leads to more efficient and widely applicable video restoration technologies, supporting advancements in fields that require high-quality video output. See our project page for video results at https://jimmycv07.github.io/DiffIR2VR_web/.
Specialize and Fuse: Pyramidal Output Representation for Semantic Segmentation
Aug 19, 2021

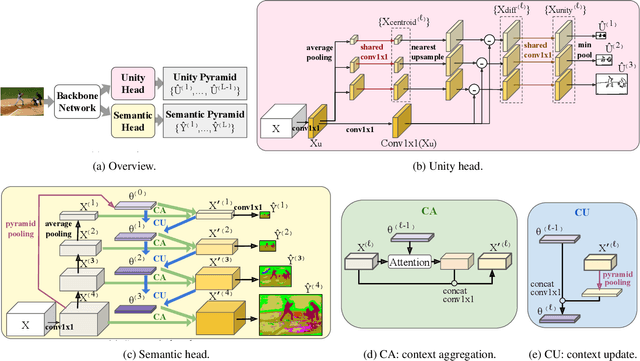

We present a novel pyramidal output representation to ensure parsimony with our "specialize and fuse" process for semantic segmentation. A pyramidal "output" representation consists of coarse-to-fine levels, where each level is "specialize" in a different class distribution (e.g., more stuff than things classes at coarser levels). Two types of pyramidal outputs (i.e., unity and semantic pyramid) are "fused" into the final semantic output, where the unity pyramid indicates unity-cells (i.e., all pixels in such cell share the same semantic label). The process ensures parsimony by predicting a relatively small number of labels for unity-cells (e.g., a large cell of grass) to build the final semantic output. In addition to the "output" representation, we design a coarse-to-fine contextual module to aggregate the "features" representation from different levels. We validate the effectiveness of each key module in our method through comprehensive ablation studies. Finally, our approach achieves state-of-the-art performance on three widely-used semantic segmentation datasets -- ADE20K, COCO-Stuff, and Pascal-Context.
Indoor Panorama Planar 3D Reconstruction via Divide and Conquer
Jun 27, 2021

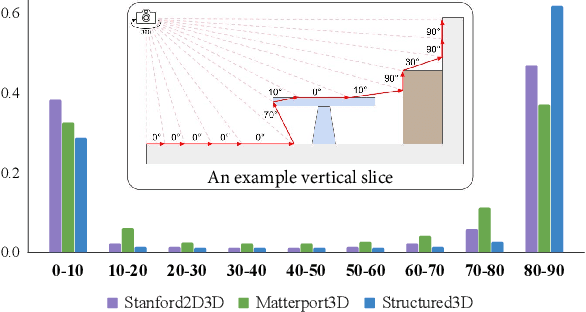
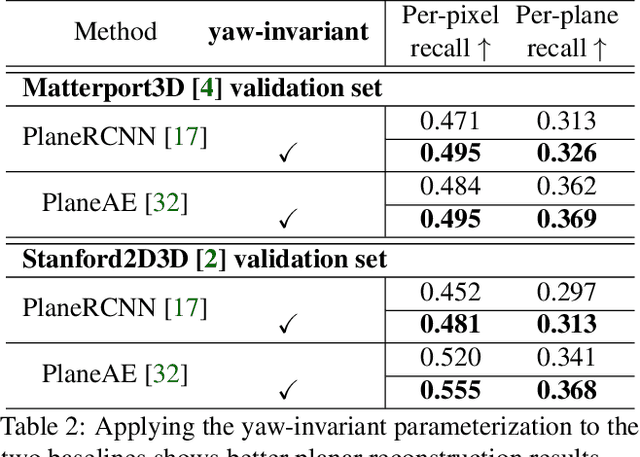
Indoor panorama typically consists of human-made structures parallel or perpendicular to gravity. We leverage this phenomenon to approximate the scene in a 360-degree image with (H)orizontal-planes and (V)ertical-planes. To this end, we propose an effective divide-and-conquer strategy that divides pixels based on their plane orientation estimation; then, the succeeding instance segmentation module conquers the task of planes clustering more easily in each plane orientation group. Besides, parameters of V-planes depend on camera yaw rotation, but translation-invariant CNNs are less aware of the yaw change. We thus propose a yaw-invariant V-planar reparameterization for CNNs to learn. We create a benchmark for indoor panorama planar reconstruction by extending existing 360 depth datasets with ground truth H\&V-planes (referred to as PanoH&V dataset) and adopt state-of-the-art planar reconstruction methods to predict H\&V-planes as our baselines. Our method outperforms the baselines by a large margin on the proposed dataset.
Flat2Layout: Flat Representation for Estimating Layout of General Room Types
May 29, 2019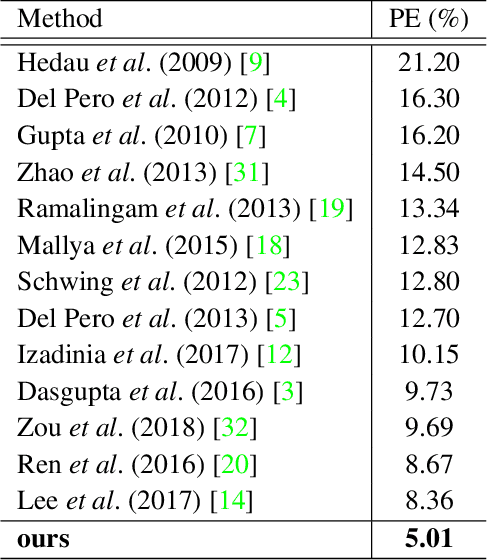

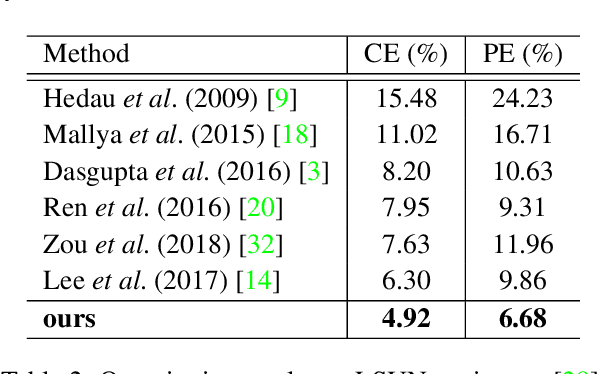

This paper proposes a new approach, Flat2Layout, for estimating general indoor room layout from a single-view RGB image whereas existing methods can only produce layout topologies captured from the box-shaped room. The proposed flat representation encodes the layout information into row vectors which are treated as the training target of the deep model. A dynamic programming based postprocessing is employed to decode the estimated flat output from the deep model into the final room layout. Flat2Layout achieves state-of-the-art performance on existing room layout benchmark. This paper also constructs a benchmark for validating the performance on general layout topologies, where Flat2Layout achieves good performance on general room types. Flat2Layout is applicable on more scenario for layout estimation and would have an impact on applications of Scene Modeling, Robotics, and Augmented Reality.
HorizonNet: Learning Room Layout with 1D Representation and Pano Stretch Data Augmentation
Jan 12, 2019
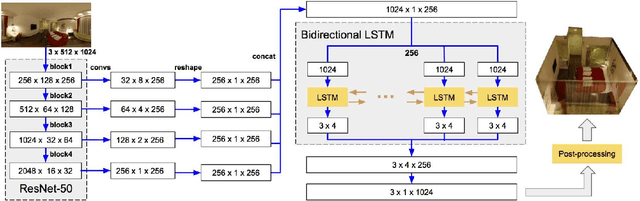


We present a new approach to the problem of estimating 3D room layout from a single panoramic image. We represent room layout as three 1D vectors that encode, at each image column, the boundary positions of floor-wall and ceiling-wall, and the existence of wall-wall boundary. The proposed network architecture, HorizonNet, trained for predicting 1D layout, outperforms previous state-of-the-art approaches. The designed post-processing procedure for recovering 3D room layouts from 1D predictions can automatically infer the room shape with low computation cost---it takes less than 20ms for a panorama image while prior works might need dozens of seconds. We also propose Pano Stretch Data Augmentation, which can diversify panorama data and be applied to other panorama-related learning tasks. Due to the limited training data available for non-cuboid layout, we re-annotate 65 general layout data from the current dataset for fine-tuning and qualitatively show the ability of our approach to estimate general layouts.