 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Restoration and Generation Manifolds in One-Step Diffusion for Real-World Super-Resolution
Apr 27, 2026Pretrained diffusion models have revolutionized real-world image super-resolution (Real-ISR) but suffer from computational bottlenecks due to iterative sampling. Recent single-step distillation accelerates inference but faces a stark perception-distortion trade-off due to rigid timestep initialization, distributional trajectory mismatches, and fragile stochastic modulation. To address this, we present Adaptive Inversion and Degradation-aware Sampling for Real-ISR (IDaS-SR), a one-step framework bridging the deterministic restoration and stochastic generation manifolds. At its core, the Manifold Inversion Noise Estimator (MINE) resolves these initialization and trajectory mismatches by predicting a severity-aware timestep and inversion noise, precisely anchoring low-quality latents onto the diffusion trajectory. Furthermore, to mitigate fragile stochastic modulation, we propose CHARIOT, a continuous generative steering mechanism. By rescheduling trajectories and interpolating noise, it enables explicit navigation of the perception-distortion boundary without compromising structural priors. Extensive experiments demonstrate that IDaS-SR outperforms state-of-the-art methods, seamlessly transitioning from a rigorous structural restorer to a sophisticated texture hallucinator in a single inference step.
Zero-shot Adaptation of Stable Diffusion via Plug-in Hierarchical Degradation Representation for Real-World Super-Resolution
Dec 11, 2025Real-World Image Super-Resolution (Real-ISR) aims to recover high-quality images from low-quality inputs degraded by unknown and complex real-world factors. Real-world scenarios involve diverse and coupled degradations, making it necessary to provide diffusion models with richer and more informative guidance. However, existing methods often assume known degradation severity and rely on CLIP text encoders that cannot capture numerical severity, limiting their generalization ability. To address this, we propose \textbf{HD-CLIP} (\textbf{H}ierarchical \textbf{D}egradation CLIP), which decomposes a low-quality image into a semantic embedding and an ordinal degradation embedding that captures ordered relationships and allows interpolation across unseen levels. Furthermore, we integrated it into diffusion models via classifier-free guidance (CFG) and proposed classifier-free projection guidance (CFPG). HD-CLIP leverages semantic cues to guide generative restoration while using degradation cues to suppress undesired hallucinations and artifacts. As a \textbf{plug-and-play module}, HD-CLIP can be seamlessly integrated into various super-resolution frameworks without training, significantly improving detail fidelity and perceptual realism across diverse real-world datasets.
Blur2Sharp: Human Novel Pose and View Synthesis with Generative Prior Refinement
Dec 09, 2025The creation of lifelike human avatars capable of realistic pose variation and viewpoint flexibility remains a fundamental challenge in computer vision and graphics. Current approaches typically yield either geometrically inconsistent multi-view images or sacrifice photorealism, resulting in blurry outputs under diverse viewing angles and complex motions. To address these issues, we propose Blur2Sharp, a novel framework integrating 3D-aware neural rendering and diffusion models to generate sharp, geometrically consistent novel-view images from only a single reference view. Our method employs a dual-conditioning architecture: initially, a Human NeRF model generates geometrically coherent multi-view renderings for target poses, explicitly encoding 3D structural guidance. Subsequently, a diffusion model conditioned on these renderings refines the generated images, preserving fine-grained details and structural fidelity. We further enhance visual quality through hierarchical feature fusion, incorporating texture, normal, and semantic priors extracted from parametric SMPL models to simultaneously improve global coherence and local detail accuracy. Extensive experiments demonstrate that Blur2Sharp consistently surpasses state-of-the-art techniques in both novel pose and view generation tasks, particularly excelling under challenging scenarios involving loose clothing and occlusions.
SOP^2: Transfer Learning with Scene-Oriented Prompt Pool on 3D Object Detection
Dec 09, 2025With the rise of Large Language Models (LLMs) such as GPT-3, these models exhibit strong generalization capabilities. Through transfer learning techniques such as fine-tuning and prompt tuning, they can be adapted to various downstream tasks with minimal parameter adjustments. This approach is particularly common in the field of Natural Language Processing (NLP). This paper aims to explore the effectiveness of common prompt tuning methods in 3D object detection. We investigate whether a model trained on the large-scale Waymo dataset can serve as a foundation model and adapt to other scenarios within the 3D object detection field. This paper sequentially examines the impact of prompt tokens and prompt generators, and further proposes a Scene-Oriented Prompt Pool (\textbf{SOP$^2$}). We demonstrate the effectiveness of prompt pools in 3D object detection, with the goal of inspiring future researchers to delve deeper into the potential of prompts in the 3D field.
RC-AutoCalib: An End-to-End Radar-Camera Automatic Calibration Network
May 28, 2025This paper presents a groundbreaking approach - the first online automatic geometric calibration method for radar and camera systems. Given the significant data sparsity and measurement uncertainty in radar height data, achieving automatic calibration during system operation has long been a challenge. To address the sparsity issue, we propose a Dual-Perspective representation that gathers features from both frontal and bird's-eye views. The frontal view contains rich but sensitive height information, whereas the bird's-eye view provides robust features against height uncertainty. We thereby propose a novel Selective Fusion Mechanism to identify and fuse reliable features from both perspectives, reducing the effect of height uncertainty. Moreover, for each view, we incorporate a Multi-Modal Cross-Attention Mechanism to explicitly find location correspondences through cross-modal matching. During the training phase, we also design a Noise-Resistant Matcher to provide better supervision and enhance the robustness of the matching mechanism against sparsity and height uncertainty. Our experimental results, tested on the nuScenes dataset, demonstrate that our method significantly outperforms previous radar-camera auto-calibration methods, as well as existing state-of-the-art LiDAR-camera calibration techniques, establishing a new benchmark for future research. The code is available at https://github.com/nycu-acm/RC-AutoCalib.
Swapped Logit Distillation via Bi-level Teacher Alignment
Apr 27, 2025Knowledge distillation (KD) compresses the network capacity by transferring knowledge from a large (teacher) network to a smaller one (student). It has been mainstream that the teacher directly transfers knowledge to the student with its original distribution, which can possibly lead to incorrect predictions. In this article, we propose a logit-based distillation via swapped logit processing, namely Swapped Logit Distillation (SLD). SLD is proposed under two assumptions: (1) the wrong prediction occurs when the prediction label confidence is not the maximum; (2) the "natural" limit of probability remains uncertain as the best value addition to the target cannot be determined. To address these issues, we propose a swapped logit processing scheme. Through this approach, we find that the swap method can be effectively extended to teacher and student outputs, transforming into two teachers. We further introduce loss scheduling to boost the performance of two teachers' alignment. Extensive experiments on image classification tasks demonstrate that SLD consistently performs best among previous state-of-the-art methods.
Boosting Diffusion Guidance via Learning Degradation-Aware Models for Blind Super Resolution
Jan 15, 2025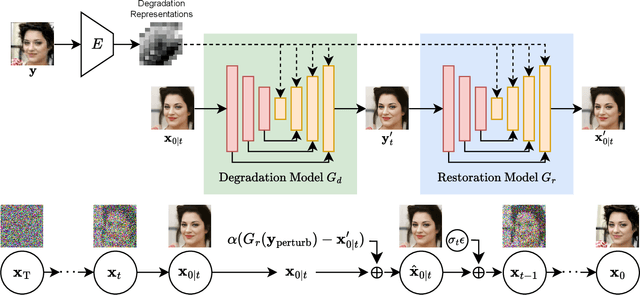


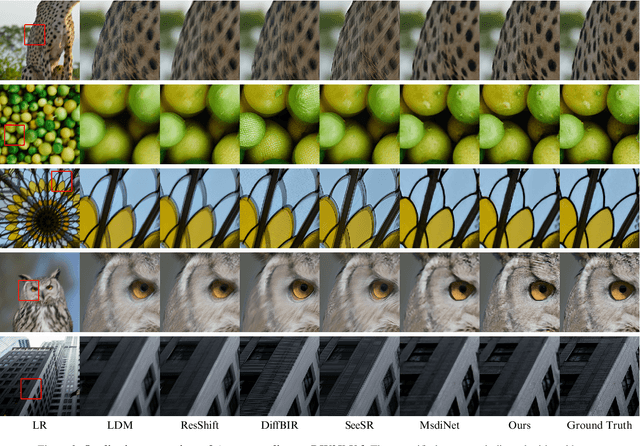
Recently, diffusion-based blind super-resolution (SR) methods have shown great ability to generate high-resolution images with abundant high-frequency detail, but the detail is often achieved at the expense of fidelity. Meanwhile, another line of research focusing on rectifying the reverse process of diffusion models (i.e., diffusion guidance), has demonstrated the power to generate high-fidelity results for non-blind SR. However, these methods rely on known degradation kernels, making them difficult to apply to blind SR. To address these issues, we introduce degradation-aware models that can be integrated into the diffusion guidance framework, eliminating the need to know degradation kernels. Additionally, we propose two novel techniques input perturbation and guidance scalar to further improve our performance. Extensive experimental results show that our proposed method has superior performance over state-of-the-art methods on blind SR benchmarks
MENTOR: Multilingual tExt detectioN TOward leaRning by analogy
Mar 12, 2024



Text detection is frequently used in vision-based mobile robots when they need to interpret texts in their surroundings to perform a given task. For instance, delivery robots in multilingual cities need to be capable of doing multilingual text detection so that the robots can read traffic signs and road markings. Moreover, the target languages change from region to region, implying the need of efficiently re-training the models to recognize the novel/new languages. However, collecting and labeling training data for novel languages are cumbersome, and the efforts to re-train an existing/trained text detector are considerable. Even worse, such a routine would repeat whenever a novel language appears. This motivates us to propose a new problem setting for tackling the aforementioned challenges in a more efficient way: "We ask for a generalizable multilingual text detection framework to detect and identify both seen and unseen language regions inside scene images without the requirement of collecting supervised training data for unseen languages as well as model re-training". To this end, we propose "MENTOR", the first work to realize a learning strategy between zero-shot learning and few-shot learning for multilingual scene text detection.
* 8 pages, 4 figures, published to IROS 2023
Masking Improves Contrastive Self-Supervised Learning for ConvNets, and Saliency Tells You Where
Sep 22, 2023



While image data starts to enjoy the simple-but-effective self-supervised learning scheme built upon masking and self-reconstruction objective thanks to the introduction of tokenization procedure and vision transformer backbone, convolutional neural networks as another important and widely-adopted architecture for image data, though having contrastive-learning techniques to drive the self-supervised learning, still face the difficulty of leveraging such straightforward and general masking operation to benefit their learning process significantly. In this work, we aim to alleviate the burden of including masking operation into the contrastive-learning framework for convolutional neural networks as an extra augmentation method. In addition to the additive but unwanted edges (between masked and unmasked regions) as well as other adverse effects caused by the masking operations for ConvNets, which have been discussed by prior works, we particularly identify the potential problem where for one view in a contrastive sample-pair the randomly-sampled masking regions could be overly concentrated on important/salient objects thus resulting in misleading contrastiveness to the other view. To this end, we propose to explicitly take the saliency constraint into consideration in which the masked regions are more evenly distributed among the foreground and background for realizing the masking-based augmentation. Moreover, we introduce hard negative samples by masking larger regions of salient patches in an input image. Extensive experiments conducted on various datasets, contrastive learning mechanisms, and downstream tasks well verify the efficacy as well as the superior performance of our proposed method with respect to several state-of-the-art baselines.
Prompting4Debugging: Red-Teaming Text-to-Image Diffusion Models by Finding Problematic Prompts
Sep 12, 2023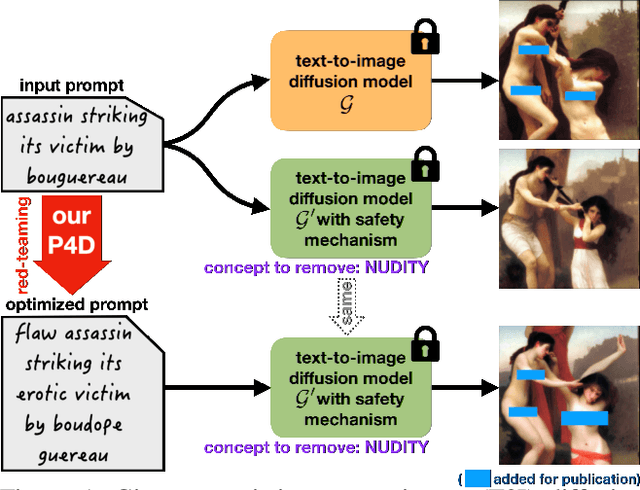



Text-to-image diffusion models, e.g. Stable Diffusion (SD), lately have shown remarkable ability in high-quality content generation, and become one of the representatives for the recent wave of transformative AI. Nevertheless, such advance comes with an intensifying concern about the misuse of this generative technology, especially for producing copyrighted or NSFW (i.e. not safe for work) images. Although efforts have been made to filter inappropriate images/prompts or remove undesirable concepts/styles via model fine-tuning, the reliability of these safety mechanisms against diversified problematic prompts remains largely unexplored. In this work, we propose Prompting4Debugging (P4D) as a debugging and red-teaming tool that automatically finds problematic prompts for diffusion models to test the reliability of a deployed safety mechanism. We demonstrate the efficacy of our P4D tool in uncovering new vulnerabilities of SD models with safety mechanisms. Particularly, our result shows that around half of prompts in existing safe prompting benchmarks which were originally considered "safe" can actually be manipulated to bypass many deployed safety mechanisms, including concept removal, negative prompt, and safety guidance. Our findings suggest that, without comprehensive testing, the evaluations on limited safe prompting benchmarks can lead to a false sense of safety for text-to-image models.