 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Diffusion Guidance via Learning Degradation-Aware Models for Blind Super Resolution
Jan 15, 2025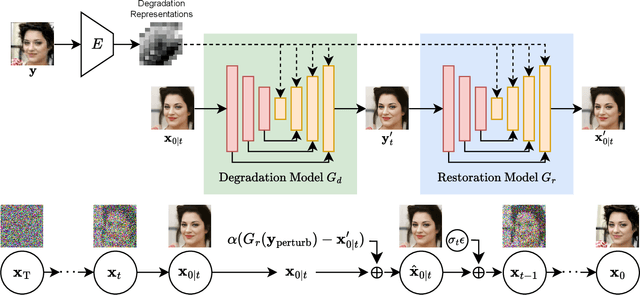


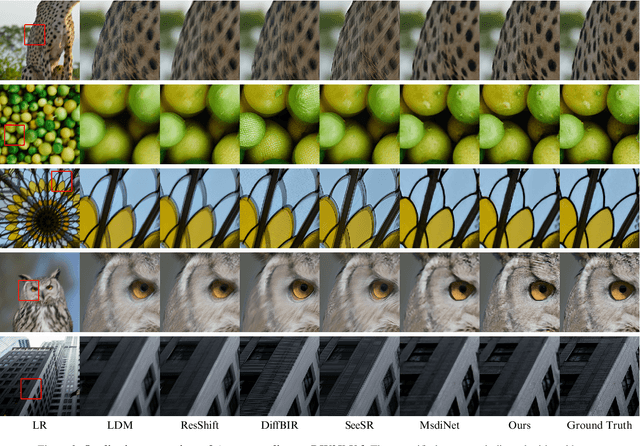
Recently, diffusion-based blind super-resolution (SR) methods have shown great ability to generate high-resolution images with abundant high-frequency detail, but the detail is often achieved at the expense of fidelity. Meanwhile, another line of research focusing on rectifying the reverse process of diffusion models (i.e., diffusion guidance), has demonstrated the power to generate high-fidelity results for non-blind SR. However, these methods rely on known degradation kernels, making them difficult to apply to blind SR. To address these issues, we introduce degradation-aware models that can be integrated into the diffusion guidance framework, eliminating the need to know degradation kernels. Additionally, we propose two novel techniques input perturbation and guidance scalar to further improve our performance. Extensive experimental results show that our proposed method has superior performance over state-of-the-art methods on blind SR benchmarks
Bias-Aware Heapified Policy for Active Learning
Nov 18, 2019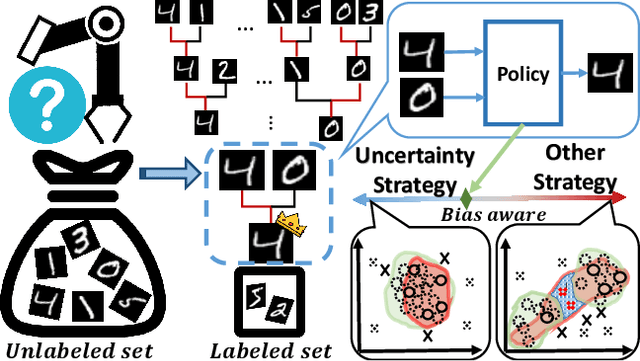
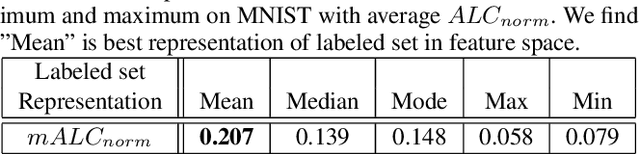
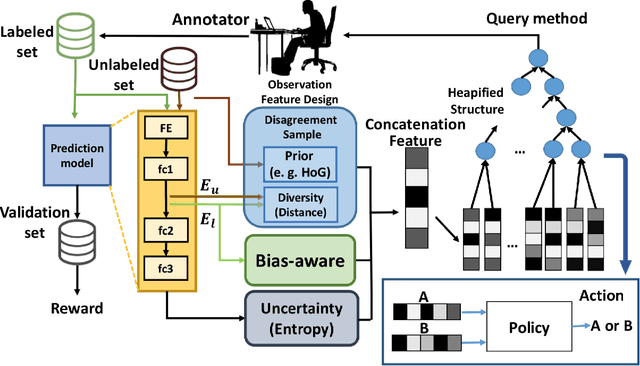
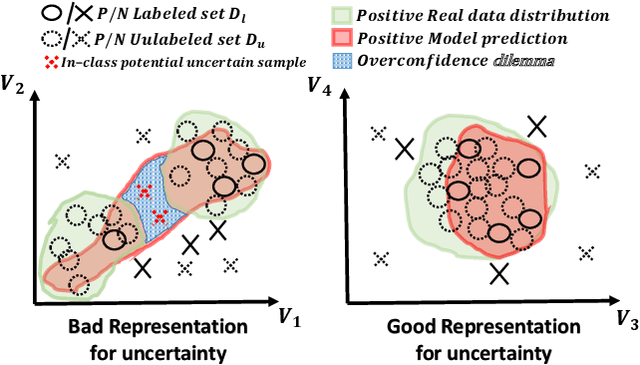
The data efficiency of learning-based algorithms is more and more important since high-quality and clean data is expensive as well as hard to collect. In order to achieve high model performance with the least number of samples, active learning is a technique that queries the most important subset of data from the original dataset. In active learning domain, one of the mainstream research is the heuristic uncertainty-based method which is useful for the learning-based system. Recently, a few works propose to apply policy reinforcement learning (PRL) for querying important data. It seems more general than heuristic uncertainty-based method owing that PRL method depends on data feature which is reliable than human prior. However, there have two problems - sample inefficiency of policy learning and overconfidence, when applying PRL on active learning. To be more precise, sample inefficiency of policy learning occurs when sampling within a large action space, in the meanwhile, class imbalance can lead to the overconfidence. In this paper, we propose a bias-aware policy network called Heapified Active Learning (HAL), which prevents overconfidence, and improves sample efficiency of policy learning by heapified structure without ignoring global inforamtion(overview of the whole unlabeled set). In our experiment, HAL outperforms other baseline methods on MNIST dataset and duplicated MNIST. Last but not least, we investigate the generalization of the HAL policy learned on MNIST dataset by directly applying it on MNIST-M. We show that the agent can generalize and outperform directly-learned policy under constrained labeled sets.