 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Adaptation of Stable Diffusion via Plug-in Hierarchical Degradation Representation for Real-World Super-Resolution
Dec 11, 2025Real-World Image Super-Resolution (Real-ISR) aims to recover high-quality images from low-quality inputs degraded by unknown and complex real-world factors. Real-world scenarios involve diverse and coupled degradations, making it necessary to provide diffusion models with richer and more informative guidance. However, existing methods often assume known degradation severity and rely on CLIP text encoders that cannot capture numerical severity, limiting their generalization ability. To address this, we propose \textbf{HD-CLIP} (\textbf{H}ierarchical \textbf{D}egradation CLIP), which decomposes a low-quality image into a semantic embedding and an ordinal degradation embedding that captures ordered relationships and allows interpolation across unseen levels. Furthermore, we integrated it into diffusion models via classifier-free guidance (CFG) and proposed classifier-free projection guidance (CFPG). HD-CLIP leverages semantic cues to guide generative restoration while using degradation cues to suppress undesired hallucinations and artifacts. As a \textbf{plug-and-play module}, HD-CLIP can be seamlessly integrated into various super-resolution frameworks without training, significantly improving detail fidelity and perceptual realism across diverse real-world datasets.
StealthAttack: Robust 3D Gaussian Splatting Poisoning via Density-Guided Illusions
Oct 02, 20253D scene representation methods like Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) have significantly advanced novel view synthesis. As these methods become prevalent, addressing their vulnerabilities becomes critical. We analyze 3DGS robustness against image-level poisoning attacks and propose a novel density-guided poisoning method. Our method strategically injects Gaussian points into low-density regions identified via Kernel Density Estimation (KDE), embedding viewpoint-dependent illusory objects clearly visible from poisoned views while minimally affecting innocent views. Additionally, we introduce an adaptive noise strategy to disrupt multi-view consistency, further enhancing attack effectiveness. We propose a KDE-based evaluation protocol to assess attack difficulty systematically, enabling objective benchmarking for future research. Extensive experiments demonstrate our method's superior performance compared to state-of-the-art techniques. Project page: https://hentci.github.io/stealthattack/
RC-AutoCalib: An End-to-End Radar-Camera Automatic Calibration Network
May 28, 2025This paper presents a groundbreaking approach - the first online automatic geometric calibration method for radar and camera systems. Given the significant data sparsity and measurement uncertainty in radar height data, achieving automatic calibration during system operation has long been a challenge. To address the sparsity issue, we propose a Dual-Perspective representation that gathers features from both frontal and bird's-eye views. The frontal view contains rich but sensitive height information, whereas the bird's-eye view provides robust features against height uncertainty. We thereby propose a novel Selective Fusion Mechanism to identify and fuse reliable features from both perspectives, reducing the effect of height uncertainty. Moreover, for each view, we incorporate a Multi-Modal Cross-Attention Mechanism to explicitly find location correspondences through cross-modal matching. During the training phase, we also design a Noise-Resistant Matcher to provide better supervision and enhance the robustness of the matching mechanism against sparsity and height uncertainty. Our experimental results, tested on the nuScenes dataset, demonstrate that our method significantly outperforms previous radar-camera auto-calibration methods, as well as existing state-of-the-art LiDAR-camera calibration techniques, establishing a new benchmark for future research. The code is available at https://github.com/nycu-acm/RC-AutoCalib.
Boosting Diffusion Guidance via Learning Degradation-Aware Models for Blind Super Resolution
Jan 15, 2025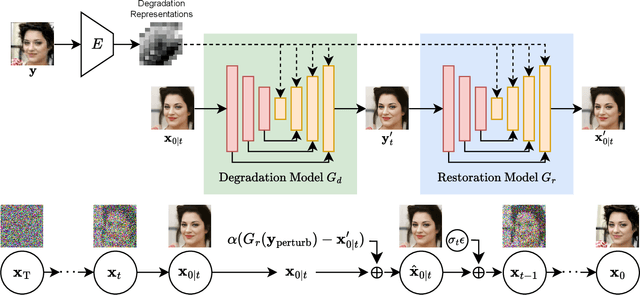


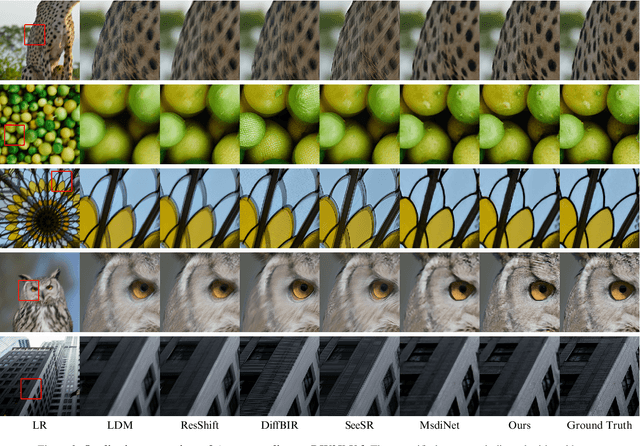
Recently, diffusion-based blind super-resolution (SR) methods have shown great ability to generate high-resolution images with abundant high-frequency detail, but the detail is often achieved at the expense of fidelity. Meanwhile, another line of research focusing on rectifying the reverse process of diffusion models (i.e., diffusion guidance), has demonstrated the power to generate high-fidelity results for non-blind SR. However, these methods rely on known degradation kernels, making them difficult to apply to blind SR. To address these issues, we introduce degradation-aware models that can be integrated into the diffusion guidance framework, eliminating the need to know degradation kernels. Additionally, we propose two novel techniques input perturbation and guidance scalar to further improve our performance. Extensive experimental results show that our proposed method has superior performance over state-of-the-art methods on blind SR benchmarks
Exemplar Masking for Multimodal Incremental Learning
Dec 12, 2024Multimodal incremental learning needs to digest the information from multiple modalities while concurrently learning new knowledge without forgetting the previously learned information. There are numerous challenges for this task, mainly including the larger storage size of multimodal data in exemplar-based methods and the computational requirement of finetuning on huge multimodal models. In this paper, we leverage the parameter-efficient tuning scheme to reduce the burden of fine-tuning and propose the exemplar masking framework to efficiently replay old knowledge. Specifically, the non-important tokens are masked based on the attention weights and the correlation across different modalities, significantly reducing the storage size of an exemplar and consequently saving more exemplars under the same memory buffer. Moreover, we design a multimodal data augmentation technique to diversify exemplars for replaying prior knowledge. In experiments, we not only evaluate our method in existing multimodal datasets but also extend the ImageNet-R dataset to a multimodal dataset as a real-world application, where captions are generated by querying multimodal large language models (e.g., InstructBLIP). Extensive experiments show that our exemplar masking framework is more efficient and robust to catastrophic forgetting under the same limited memory buffer. Code is available at https://github.com/YiLunLee/Exemplar_Masking_MCIL.
Delve into Visual Contrastive Decoding for Hallucination Mitigation of Large Vision-Language Models
Dec 09, 2024While large vision-language models (LVLMs) have shown impressive capabilities in generating plausible responses correlated with input visual contents, they still suffer from hallucinations, where the generated text inaccurately reflects visual contents. To address this, recent approaches apply contrastive decoding to calibrate the model's response via contrasting output distributions with original and visually distorted samples, demonstrating promising hallucination mitigation in a training-free manner. However, the potential of changing information in visual inputs is not well-explored, so a deeper investigation into the behaviors of visual contrastive decoding is of great interest. In this paper, we first explore various methods for contrastive decoding to change visual contents, including image downsampling and editing. Downsampling images reduces the detailed textual information while editing yields new contents in images, providing new aspects as visual contrastive samples. To further study benefits by using different contrastive samples, we analyze probability-level metrics, including entropy and distribution distance. Interestingly, the effect of these samples in mitigating hallucinations varies a lot across LVLMs and benchmarks. Based on our analysis, we propose a simple yet effective method to combine contrastive samples, offering a practical solution for applying contrastive decoding across various scenarios. Extensive experiments are conducted to validate the proposed fusion method among different benchmarks.
In-Context Experience Replay Facilitates Safety Red-Teaming of Text-to-Image Diffusion Models
Nov 25, 2024Text-to-image (T2I) models have shown remarkable progress, but their potential to generate harmful content remains a critical concern in the ML community. While various safety mechanisms have been developed, the field lacks systematic tools for evaluating their effectiveness against real-world misuse scenarios. In this work, we propose ICER, a novel red-teaming framework that leverages Large Language Models (LLMs) and a bandit optimization-based algorithm to generate interpretable and semantic meaningful problematic prompts by learning from past successful red-teaming attempts. Our ICER efficiently probes safety mechanisms across different T2I models without requiring internal access or additional training, making it broadly applicable to deployed systems. Through extensive experiments, we demonstrate that ICER significantly outperforms existing prompt attack methods in identifying model vulnerabilities while maintaining high semantic similarity with intended content. By uncovering that successful jailbreaking instances can systematically facilitate the discovery of new vulnerabilities, our work provides crucial insights for developing more robust safety mechanisms in T2I systems.
Realizing Video Summarization from the Path of Language-based Semantic Understanding
Oct 06, 2024



The recent development of Video-based Large Language Models (VideoLLMs), has significantly advanced video summarization by aligning video features and, in some cases, audio features with Large Language Models (LLMs). Each of these VideoLLMs possesses unique strengths and weaknesses. Many recent methods have required extensive fine-tuning to overcome the limitations of these models, which can be resource-intensive. In this work, we observe that the strengths of one VideoLLM can complement the weaknesses of another. Leveraging this insight, we propose a novel video summarization framework inspired by the Mixture of Experts (MoE) paradigm, which operates as an inference-time algorithm without requiring any form of fine-tuning. Our approach integrates multiple VideoLLMs to generate comprehensive and coherent textual summaries. It effectively combines visual and audio content, provides detailed background descriptions, and excels at identifying keyframes, which enables more semantically meaningful retrieval compared to traditional computer vision approaches that rely solely on visual information, all without the need for additional fine-tuning. Moreover, the resulting summaries enhance performance in downstream tasks such as summary video generation, either through keyframe selection or in combination with text-to-image models. Our language-driven approach offers a semantically rich alternative to conventional methods and provides flexibility to incorporate newer VideoLLMs, enhancing adaptability and performance in video summarization tasks.
T2Vs Meet VLMs: A Scalable Multimodal Dataset for Visual Harmfulness Recognition
Sep 29, 2024



To address the risks of encountering inappropriate or harmful content, researchers managed to incorporate several harmful contents datasets with machine learning methods to detect harmful concepts. However, existing harmful datasets are curated by the presence of a narrow range of harmful objects, and only cover real harmful content sources. This hinders the generalizability of methods based on such datasets, potentially leading to misjudgments. Therefore, we propose a comprehensive harmful dataset, Visual Harmful Dataset 11K (VHD11K), consisting of 10,000 images and 1,000 videos, crawled from the Internet and generated by 4 generative models, across a total of 10 harmful categories covering a full spectrum of harmful concepts with nontrivial definition. We also propose a novel annotation framework by formulating the annotation process as a multi-agent Visual Question Answering (VQA) task, having 3 different VLMs "debate" about whether the given image/video is harmful, and incorporating the in-context learning strategy in the debating process. Therefore, we can ensure that the VLMs consider the context of the given image/video and both sides of the arguments thoroughly before making decisions, further reducing the likelihood of misjudgments in edge cases. Evaluation and experimental results demonstrate that (1) the great alignment between the annotation from our novel annotation framework and those from human, ensuring the reliability of VHD11K; (2) our full-spectrum harmful dataset successfully identifies the inability of existing harmful content detection methods to detect extensive harmful contents and improves the performance of existing harmfulness recognition methods; (3) VHD11K outperforms the baseline dataset, SMID, as evidenced by the superior improvement in harmfulness recognition methods. The complete dataset and code can be found at https://github.com/nctu-eva-lab/VHD11K.
Identifying and Clustering Counter Relationships of Team Compositions in PvP Games for Efficient Balance Analysis
Aug 30, 2024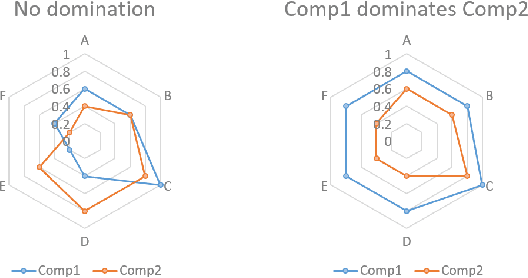
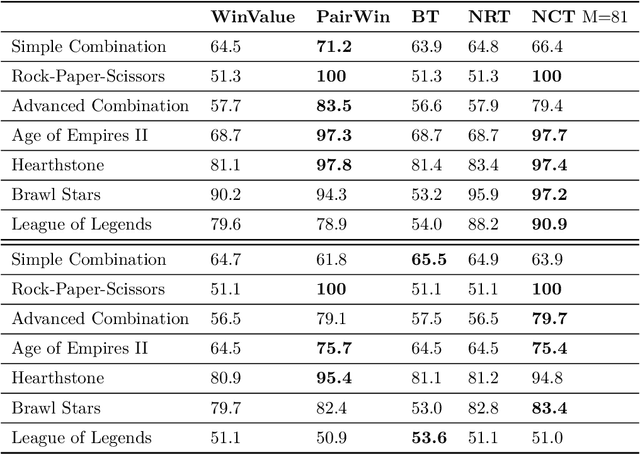
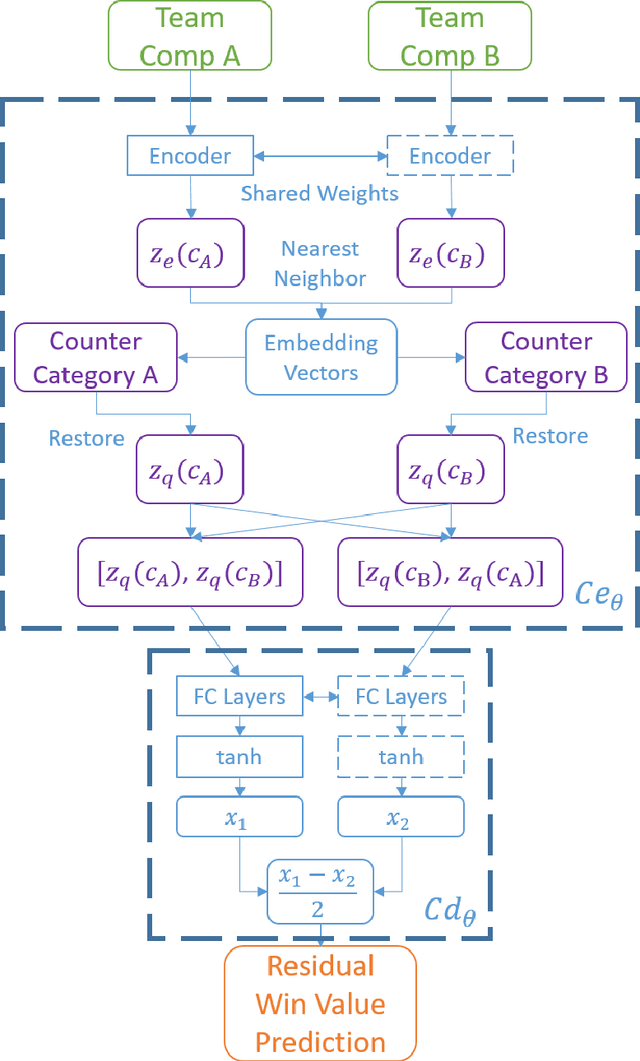
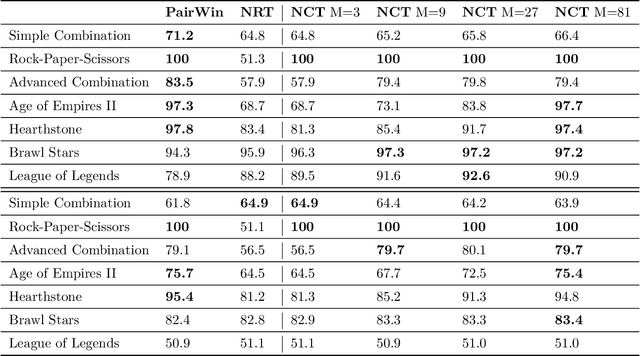
How can balance be quantified in game settings? This question is crucial for game designers, especially in player-versus-player (PvP) games, where analyzing the strength relations among predefined team compositions-such as hero combinations in multiplayer online battle arena (MOBA) games or decks in card games-is essential for enhancing gameplay and achieving balance. We have developed two advanced measures that extend beyond the simplistic win rate to quantify balance in zero-sum competitive scenarios. These measures are derived from win value estimations, which employ strength rating approximations via the Bradley-Terry model and counter relationship approximations via vector quantization, significantly reducing the computational complexity associated with traditional win value estimations. Throughout the learning process of these models, we identify useful categories of compositions and pinpoint their counter relationships, aligning with the experiences of human players without requiring specific game knowledge. Our methodology hinges on a simple technique to enhance codebook utilization in discrete representation with a deterministic vector quantization process for an extremely small state space. Our framework has been validated in popular online games, including Age of Empires II, Hearthstone, Brawl Stars, and League of Legends. The accuracy of the observed strength relations in these games is comparable to traditional pairwise win value predictions, while also offering a more manageable complexity for analysis. Ultimately, our findings contribute to a deeper understanding of PvP game dynamics and present a methodology that significantly improves game balance evaluation and design.