 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Spatiotemporal Reasoning in LLMs and Reasoning Models: Capabilities and Challenges
May 16, 2025Spatiotemporal reasoning plays a key role in Cyber-Physical Systems (CPS). Despite advances in Large Language Models (LLMs) and Large Reasoning Models (LRMs), their capacity to reason about complex spatiotemporal signals remains underexplored. This paper proposes a hierarchical SpatioTemporal reAsoning benchmaRK, STARK, to systematically evaluate LLMs across three levels of reasoning complexity: state estimation (e.g., predicting field variables, localizing and tracking events in space and time), spatiotemporal reasoning over states (e.g., inferring spatial-temporal relationships), and world-knowledge-aware reasoning that integrates contextual and domain knowledge (e.g., intent prediction, landmark-aware navigation). We curate 26 distinct spatiotemporal tasks with diverse sensor modalities, comprising 14,552 challenges where models answer directly or by Python Code Interpreter. Evaluating 3 LRMs and 8 LLMs, we find LLMs achieve limited success in tasks requiring geometric reasoning (e.g., multilateration or triangulation), particularly as complexity increases. Surprisingly, LRMs show robust performance across tasks with various levels of difficulty, often competing or surpassing traditional first-principle-based methods. Our results show that in reasoning tasks requiring world knowledge, the performance gap between LLMs and LRMs narrows, with some LLMs even surpassing LRMs. However, the LRM o3 model continues to achieve leading performance across all evaluated tasks, a result attributed primarily to the larger size of the reasoning models. STARK motivates future innovations in model architectures and reasoning paradigms for intelligent CPS by providing a structured framework to identify limitations in the spatiotemporal reasoning of LLMs and LRMs.
A Recipe for CAC: Mosaic-based Generalized Loss for Improved Class-Agnostic Counting
Apr 15, 2024Class agnostic counting (CAC) is a vision task that can be used to count the total occurrence number of any given reference objects in the query image. The task is usually formulated as a density map estimation problem through similarity computation among a few image samples of the reference object and the query image. In this paper, we point out a severe issue of the existing CAC framework: Given a multi-class setting, models don't consider reference images and instead blindly match all dominant objects in the query image. Moreover, the current evaluation metrics and dataset cannot be used to faithfully assess the model's generalization performance and robustness. To this end, we discover that the combination of mosaic augmentation with generalized loss is essential for addressing the aforementioned issue of CAC models to count objects of majority (i.e. dominant objects) regardless of the references. Furthermore, we introduce a new evaluation protocol and metrics for resolving the problem behind the existing CAC evaluation scheme and better benchmarking CAC models in a more fair manner. Besides, extensive evaluation results demonstrate that our proposed recipe can consistently improve the performance of different CAC models. The code will be released upon acceptance.
Zero-shot Building Attribute Extraction from Large-Scale Vision and Language Models
Dec 19, 2023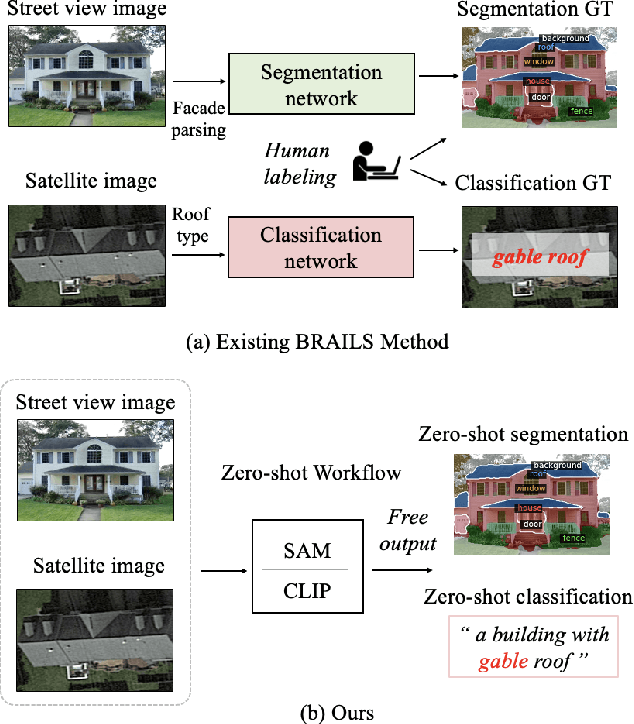
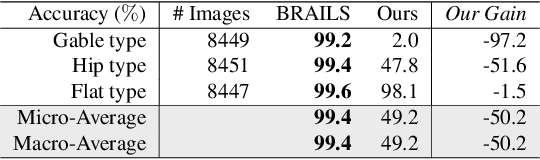
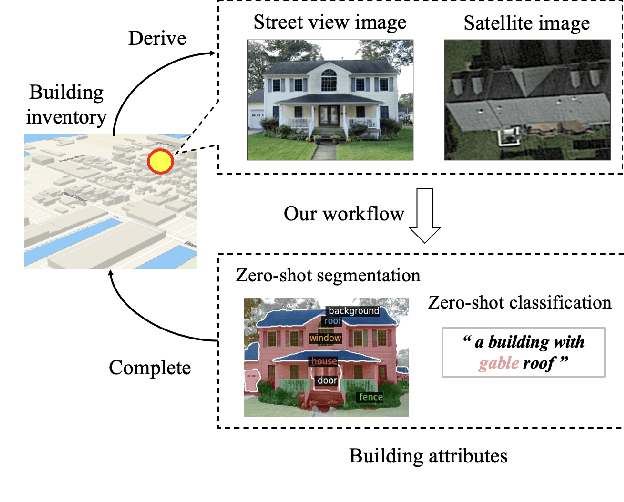
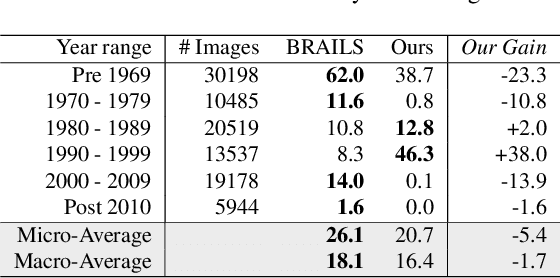
Existing building recognition methods, exemplified by BRAILS, utilize supervised learning to extract information from satellite and street-view images for classification and segmentation. However, each task module requires human-annotated data, hindering the scalability and robustness to regional variations and annotation imbalances. In response, we propose a new zero-shot workflow for building attribute extraction that utilizes large-scale vision and language models to mitigate reliance on external annotations. The proposed workflow contains two key components: image-level captioning and segment-level captioning for the building images based on the vocabularies pertinent to structural and civil engineering. These two components generate descriptive captions by computing feature representations of the image and the vocabularies, and facilitating a semantic match between the visual and textual representations. Consequently, our framework offers a promising avenue to enhance AI-driven captioning for building attribute extraction in the structural and civil engineering domains, ultimately reducing reliance on human annotations while bolstering performance and adaptability.