 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Knowledge-Assisted Federated Dual Knowledge Distillation Approach Towards Remote Sensing Satellite Imagery
Mar 08, 2026Federated learning (FL) has recently become a promising solution for analyzing remote sensing satellite imagery (RSSI). However, the large scale and inherent data heterogeneity of images collected from multiple satellites, where the local data distribution of each satellite differs from the global one, present significant challenges to effective model training. To address this issue, we propose a Geometric Knowledge-Guided Federated Dual Knowledge Distillation (GK-FedDKD) framework for RSSI analysis. In our approach, each local client first distills a teacher encoder (TE) from multiple student encoders (SEs) trained with unlabeled augmented data. The TE is then connected with a shared classifier to form a teacher network (TN) that supervises the training of a new student network (SN). The intermediate representations of the TN are used to compute local covariance matrices, which are aggregated at the server to generate global geometric knowledge (GGK). This GGK is subsequently employed for local embedding augmentation to further guide SN training. We also design a novel loss function and a multi-prototype generation pipeline to stabilize the training process. Evaluation over multiple datasets showcases that the proposed GK-FedDKD approach is superior to the considered state-of-the-art baselines, e.g., the proposed approach with the Swin-T backbone surpasses previous SOTA approaches by an average 68.89% on the EuroSAT dataset.
LBM: Hierarchical Large Auto-Bidding Model via Reasoning and Acting
Mar 05, 2026The growing scale of ad auctions on online advertising platforms has intensified competition, making manual bidding impractical and necessitating auto-bidding to help advertisers achieve their economic goals. Current auto-bidding methods have evolved to use offline reinforcement learning or generative methods to optimize bidding strategies, but they can sometimes behave counterintuitively due to the black-box training manner and limited mode coverage of datasets, leading to challenges in understanding task status and generalization in dynamic ad environments. Large language models (LLMs) offer a promising solution by leveraging prior human knowledge and reasoning abilities to improve auto-bidding performance. However, directly applying LLMs to auto-bidding faces difficulties due to the need for precise actions in competitive auctions and the lack of specialized auto-bidding knowledge, which can lead to hallucinations and suboptimal decisions. To address these challenges, we propose a hierarchical Large autoBidding Model (LBM) to leverage the reasoning capabilities of LLMs for developing a superior auto-bidding strategy. This includes a high-level LBM-Think model for reasoning and a low-level LBM-Act model for action generation. Specifically, we propose a dual embedding mechanism to efficiently fuse two modalities, including language and numerical inputs, for language-guided training of the LBM-Act; then, we propose an offline reinforcement fine-tuning technique termed GQPO for mitigating the LLM-Think's hallucinations and enhancing decision-making performance without simulation or real-world rollout like previous multi-turn LLM-based methods. Experiments demonstrate the superiority of a generative backbone based on our LBM, especially in an efficient training manner and generalization ability.
Generative Auto-Bidding in Large-Scale Competitive Auctions via Diffusion Completer-Aligner
Sep 03, 2025Auto-bidding is central to computational advertising, achieving notable commercial success by optimizing advertisers' bids within economic constraints. Recently, large generative models show potential to revolutionize auto-bidding by generating bids that could flexibly adapt to complex, competitive environments. Among them, diffusers stand out for their ability to address sparse-reward challenges by focusing on trajectory-level accumulated rewards, as well as their explainable capability, i.e., planning a future trajectory of states and executing bids accordingly. However, diffusers struggle with generation uncertainty, particularly regarding dynamic legitimacy between adjacent states, which can lead to poor bids and further cause significant loss of ad impression opportunities when competing with other advertisers in a highly competitive auction environment. To address it, we propose a Causal auto-Bidding method based on a Diffusion completer-aligner framework, termed CBD. Firstly, we augment the diffusion training process with an extra random variable t, where the model observes t-length historical sequences with the goal of completing the remaining sequence, thereby enhancing the generated sequences' dynamic legitimacy. Then, we employ a trajectory-level return model to refine the generated trajectories, aligning more closely with advertisers' objectives. Experimental results across diverse settings demonstrate that our approach not only achieves superior performance on large-scale auto-bidding benchmarks, such as a 29.9% improvement in conversion value in the challenging sparse-reward auction setting, but also delivers significant improvements on the Kuaishou online advertising platform, including a 2.0% increase in target cost.
Generative Auto-Bidding with Value-Guided Explorations
Apr 20, 2025Auto-bidding, with its strong capability to optimize bidding decisions within dynamic and competitive online environments, has become a pivotal strategy for advertising platforms. Existing approaches typically employ rule-based strategies or Reinforcement Learning (RL) techniques. However, rule-based strategies lack the flexibility to adapt to time-varying market conditions, and RL-based methods struggle to capture essential historical dependencies and observations within Markov Decision Process (MDP) frameworks. Furthermore, these approaches often face challenges in ensuring strategy adaptability across diverse advertising objectives. Additionally, as offline training methods are increasingly adopted to facilitate the deployment and maintenance of stable online strategies, the issues of documented behavioral patterns and behavioral collapse resulting from training on fixed offline datasets become increasingly significant. To address these limitations, this paper introduces a novel offline Generative Auto-bidding framework with Value-Guided Explorations (GAVE). GAVE accommodates various advertising objectives through a score-based Return-To-Go (RTG) module. Moreover, GAVE integrates an action exploration mechanism with an RTG-based evaluation method to explore novel actions while ensuring stability-preserving updates. A learnable value function is also designed to guide the direction of action exploration and mitigate Out-of-Distribution (OOD) problems. Experimental results on two offline datasets and real-world deployments demonstrate that GAVE outperforms state-of-the-art baselines in both offline evaluations and online A/B tests. The implementation code is publicly available to facilitate reproducibility and further research.
GAS: Generative Auto-bidding with Post-training Search
Dec 22, 2024



Auto-bidding is essential in facilitating online advertising by automatically placing bids on behalf of advertisers. Generative auto-bidding, which generates bids based on an adjustable condition using models like transformers and diffusers, has recently emerged as a new trend due to its potential to learn optimal strategies directly from data and adjust flexibly to preferences. However, generative models suffer from low-quality data leading to a mismatch between condition, return to go, and true action value, especially in long sequential decision-making. Besides, the majority preference in the dataset may hinder models' generalization ability on minority advertisers' preferences. While it is possible to collect high-quality data and retrain multiple models for different preferences, the high cost makes it unaffordable, hindering the advancement of auto-bidding into the era of large foundation models. To address this, we propose a flexible and practical Generative Auto-bidding scheme using post-training Search, termed GAS, to refine a base policy model's output and adapt to various preferences. We use weak-to-strong search alignment by training small critics for different preferences and an MCTS-inspired search to refine the model's output. Specifically, a novel voting mechanism with transformer-based critics trained with policy indications could enhance search alignment performance. Additionally, utilizing the search, we provide a fine-tuning method for high-frequency preference scenarios considering computational efficiency. Extensive experiments conducted on the real-world dataset and online A/B test on the Kuaishou advertising platform demonstrate the effectiveness of GAS, achieving significant improvements, e.g., 1.554% increment of target cost.
ACQ: A Unified Framework for Automated Programmatic Creativity in Online Advertising
Dec 09, 2024


In online advertising, the demand-side platform (a.k.a. DSP) enables advertisers to create different ad creatives for real-time bidding. Intuitively, advertisers tend to create more ad creatives for a single photo to increase the probability of participating in bidding, further enhancing their ad cost. From the perspective of DSP, the following are two overlooked issues. On the one hand, the number of ad creatives cannot grow indefinitely. On the other hand, the marginal effects of ad cost diminish as the number of ad creatives increases. To this end, this paper proposes a two-stage framework named Automated Creatives Quota (ACQ) to achieve the automatic creation and deactivation of ad creatives. ACQ dynamically allocates the creative quota across multiple advertisers to maximize the revenue of the ad platform. ACQ comprises two components: a prediction module to estimate the cost of a photo under different numbers of ad creatives, and an allocation module to decide the quota for photos considering their estimated costs in the prediction module. Specifically, in the prediction module, we develop a multi-task learning model based on an unbalanced binary tree to effectively mitigate the target variable imbalance problem. In the allocation module, we formulate the quota allocation problem as a multiple-choice knapsack problem (MCKP) and develop an efficient solver to solve such large-scale problems involving tens of millions of ads. We performed extensive offline and online experiments to validate the superiority of our proposed framework, which increased cost by 9.34%.
LDACP: Long-Delayed Ad Conversions Prediction Model for Bidding Strategy
Nov 25, 2024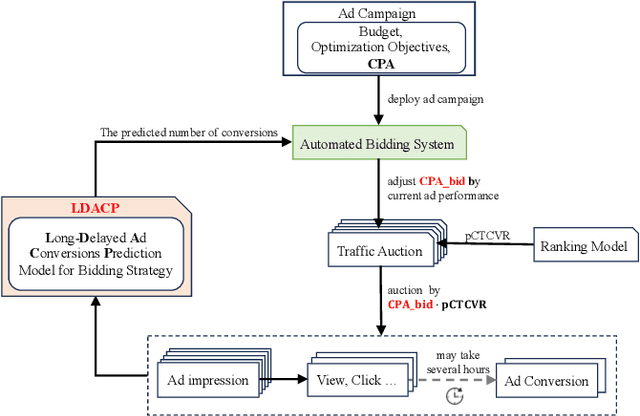

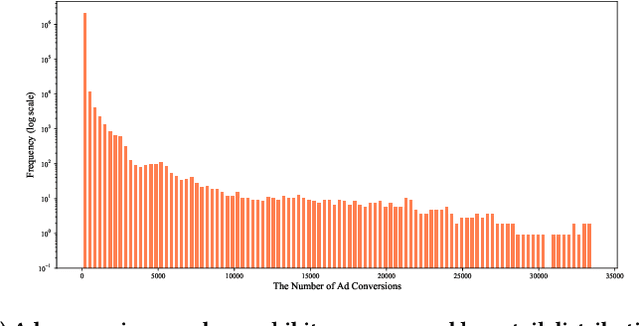

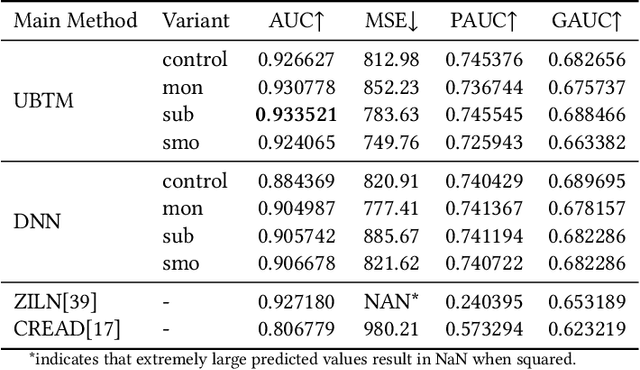
In online advertising, once an ad campaign is deployed, the automated bidding system dynamically adjusts the bidding strategy to optimize Cost Per Action (CPA) based on the number of ad conversions. For ads with a long conversion delay, relying solely on the real-time tracked conversion number as a signal for bidding strategy can significantly overestimate the current CPA, leading to conservative bidding strategies. Therefore, it is crucial to predict the number of long-delayed conversions. Nonetheless, it is challenging to predict ad conversion numbers through traditional regression methods due to the wide range of ad conversion numbers. Previous regression works have addressed this challenge by transforming regression problems into bucket classification problems, achieving success in various scenarios. However, specific challenges arise when predicting the number of ad conversions: 1) The integer nature of ad conversion numbers exacerbates the discontinuity issue in one-hot hard labels; 2) The long-tail distribution of ad conversion numbers complicates tail data prediction. In this paper, we propose the Long-Delayed Ad Conversions Prediction model for bidding strategy (LDACP), which consists of two sub-modules. To alleviate the issue of discontinuity in one-hot hard labels, the Bucket Classification Module with label Smoothing method (BCMS) converts one-hot hard labels into non-normalized soft labels, then fits these soft labels by minimizing classification loss and regression loss. To address the challenge of predicting tail data, the Value Regression Module with Proxy labels (VRMP) uses the prediction bias of aggregated pCTCVR as proxy labels. Finally, a Mixture of Experts (MoE) structure integrates the predictions from BCMS and VRMP to obtain the final predicted ad conversion number.
Robotic transcatheter tricuspid valve replacement with hybrid enhanced intelligence: a new paradigm and first-in-vivo study
Nov 19, 2024



Transcatheter tricuspid valve replacement (TTVR) is the latest treatment for tricuspid regurgitation and is in the early stages of clinical adoption. Intelligent robotic approaches are expected to overcome the challenges of surgical manipulation and widespread dissemination, but systems and protocols with high clinical utility have not yet been reported. In this study, we propose a complete solution that includes a passive stabilizer, robotic drive, detachable delivery catheter and valve manipulation mechanism. Working towards autonomy, a hybrid augmented intelligence approach based on reinforcement learning, Monte Carlo probabilistic maps and human-robot co-piloted control was introduced. Systematic tests in phantom and first-in-vivo animal experiments were performed to verify that the system design met the clinical requirement. Furthermore, the experimental results confirmed the advantages of co-piloted control over conventional master-slave control in terms of time efficiency, control efficiency, autonomy and stability of operation. In conclusion, this study provides a comprehensive pathway for robotic TTVR and, to our knowledge, completes the first animal study that not only successfully demonstrates the application of hybrid enhanced intelligence in interventional robotics, but also provides a solution with high application value for a cutting-edge procedure.
OpenSlot: Mixed Open-set Recognition with Object-centric Learning
Jul 02, 2024



Existing open-set recognition (OSR) studies typically assume that each image contains only one class label, and the unknown test set (negative) has a disjoint label space from the known test set (positive), a scenario termed full-label shift. This paper introduces the mixed OSR problem, where test images contain multiple class semantics, with known and unknown classes co-occurring in negatives, leading to a more challenging super-label shift. Addressing the mixed OSR requires classification models to accurately distinguish different class semantics within images and measure their "knowness". In this study, we propose the OpenSlot framework, built upon object-centric learning. OpenSlot utilizes slot features to represent diverse class semantics and produce class predictions. Through our proposed anti-noise-slot (ANS) technique, we mitigate the impact of noise (invalid and background) slots during classification training, effectively addressing the semantic misalignment between class predictions and the ground truth. We conduct extensive experiments with OpenSlot on mixed & conventional OSR benchmarks. Without elaborate designs, OpenSlot not only exceeds existing OSR studies in detecting super-label shifts across single & multi-label mixed OSR tasks but also achieves state-of-the-art performance on conventional benchmarks. Remarkably, our method can localize class objects without using bounding boxes during training. The competitive performance in open-set object detection demonstrates OpenSlot's ability to explicitly explain label shifts and benefits in computational efficiency and generalization.
Fine-grained Background Representation for Weakly Supervised Semantic Segmentation
Jun 22, 2024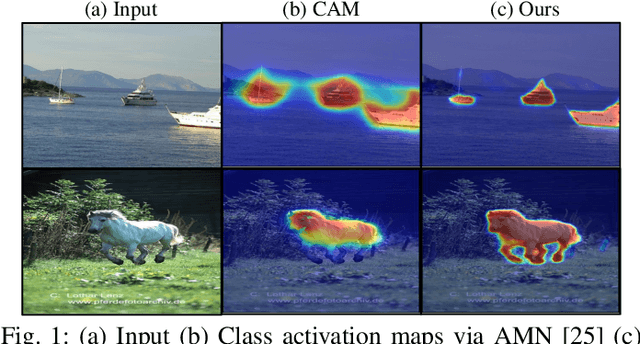
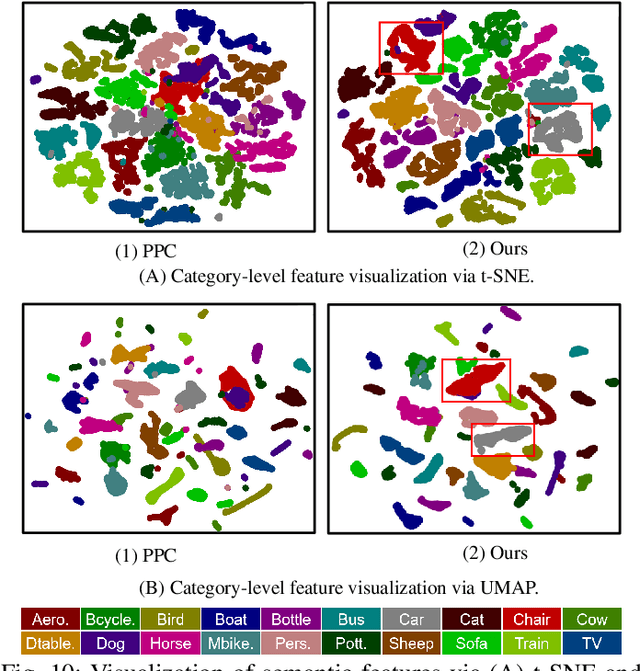

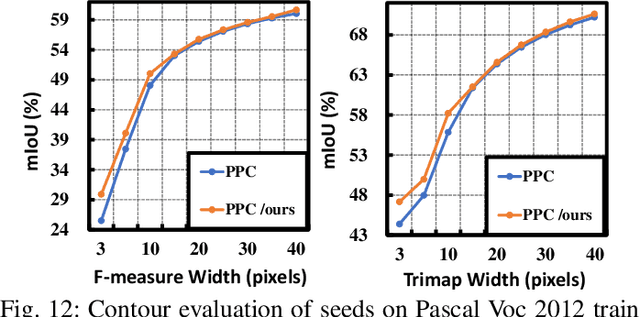
Generating reliable pseudo masks from image-level labels is challenging in the weakly supervised semantic segmentation (WSSS) task due to the lack of spatial information. Prevalent class activation map (CAM)-based solutions are challenged to discriminate the foreground (FG) objects from the suspicious background (BG) pixels (a.k.a. co-occurring) and learn the integral object regions. This paper proposes a simple fine-grained background representation (FBR) method to discover and represent diverse BG semantics and address the co-occurring problems. We abandon using the class prototype or pixel-level features for BG representation. Instead, we develop a novel primitive, negative region of interest (NROI), to capture the fine-grained BG semantic information and conduct the pixel-to-NROI contrast to distinguish the confusing BG pixels. We also present an active sampling strategy to mine the FG negatives on-the-fly, enabling efficient pixel-to-pixel intra-foreground contrastive learning to activate the entire object region. Thanks to the simplicity of design and convenience in use, our proposed method can be seamlessly plugged into various models, yielding new state-of-the-art results under various WSSS settings across benchmarks. Leveraging solely image-level (I) labels as supervision, our method achieves 73.2 mIoU and 45.6 mIoU segmentation results on Pascal Voc and MS COCO test sets, respectively. Furthermore, by incorporating saliency maps as an additional supervision signal (I+S), we attain 74.9 mIoU on Pascal Voc test set. Concurrently, our FBR approach demonstrates meaningful performance gains in weakly-supervised instance segmentation (WSIS) tasks, showcasing its robustness and strong generalization capabilities across diverse domains.