 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDHR: Dual Features-Driven Hierarchical Rebalancing in Inter- and Intra-Class Regions for Weakly-Supervised Semantic Segmentation
Mar 30, 2024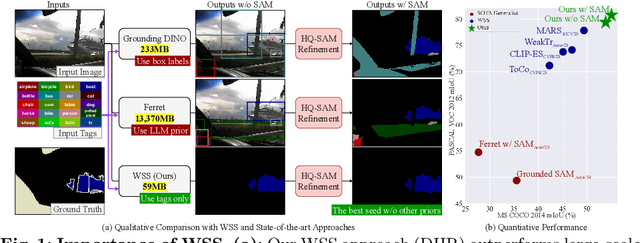


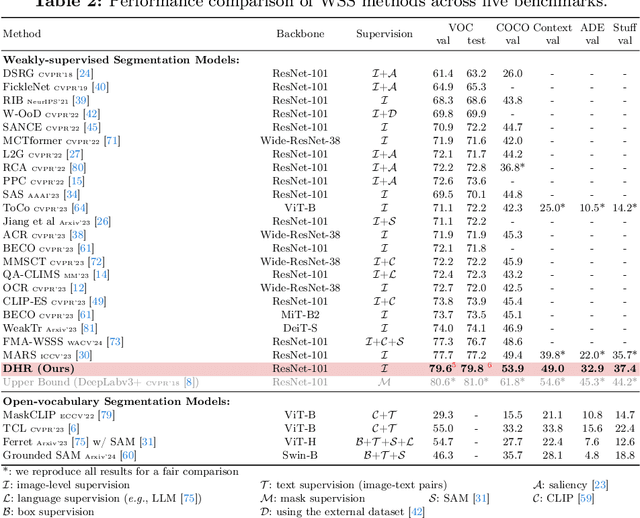
Weakly-supervised semantic segmentation (WSS) ensures high-quality segmentation with limited data and excels when employed as input seed masks for large-scale vision models such as Segment Anything. However, WSS faces challenges related to minor classes since those are overlooked in images with adjacent multiple classes, a limitation originating from the overfitting of traditional expansion methods like Random Walk. We first address this by employing unsupervised and weakly-supervised feature maps instead of conventional methodologies, allowing for hierarchical mask enhancement. This method distinctly categorizes higher-level classes and subsequently separates their associated lower-level classes, ensuring all classes are correctly restored in the mask without losing minor ones. Our approach, validated through extensive experimentation, significantly improves WSS across five benchmarks (VOC: 79.8\%, COCO: 53.9\%, Context: 49.0\%, ADE: 32.9\%, Stuff: 37.4\%), reducing the gap with fully supervised methods by over 84\% on the VOC validation set. Code is available at https://github.com/shjo-april/DHR.
MARS: Model-agnostic Biased Object Removal without Additional Supervision for Weakly-Supervised Semantic Segmentation
Apr 19, 2023Weakly-supervised semantic segmentation aims to reduce labeling costs by training semantic segmentation models using weak supervision, such as image-level class labels. However, most approaches struggle to produce accurate localization maps and suffer from false predictions in class-related backgrounds (i.e., biased objects), such as detecting a railroad with the train class. Recent methods that remove biased objects require additional supervision for manually identifying biased objects for each problematic class and collecting their datasets by reviewing predictions, limiting their applicability to the real-world dataset with multiple labels and complex relationships for biasing. Following the first observation that biased features can be separated and eliminated by matching biased objects with backgrounds in the same dataset, we propose a fully-automatic/model-agnostic biased removal framework called MARS (Model-Agnostic biased object Removal without additional Supervision), which utilizes semantically consistent features of an unsupervised technique to eliminate biased objects in pseudo labels. Surprisingly, we show that MARS achieves new state-of-the-art results on two popular benchmarks, PASCAL VOC 2012 (val: 77.7%, test: 77.2%) and MS COCO 2014 (val: 49.4%), by consistently improving the performance of various WSSS models by at least 30% without additional supervision.
Learning JPEG Compression Artifacts for Image Manipulation Detection and Localization
Aug 30, 2021
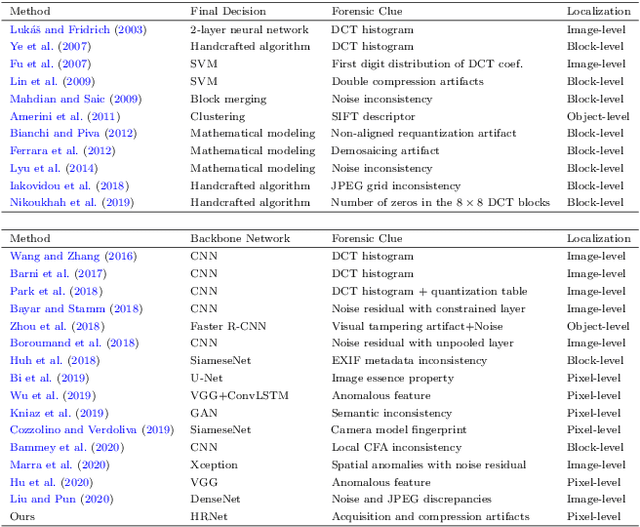
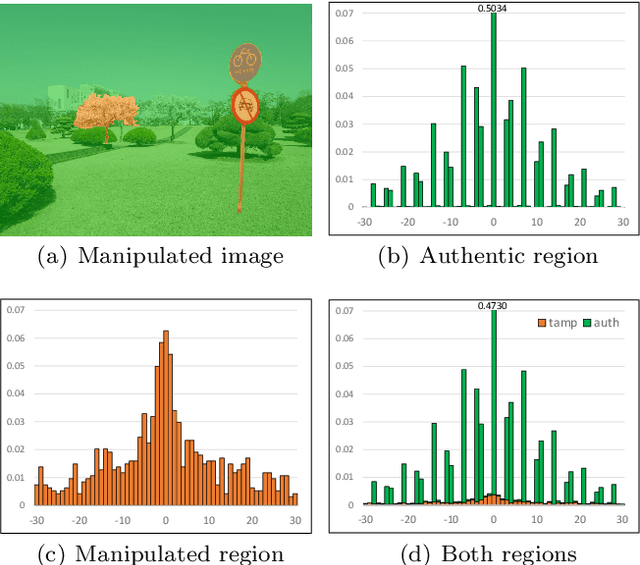
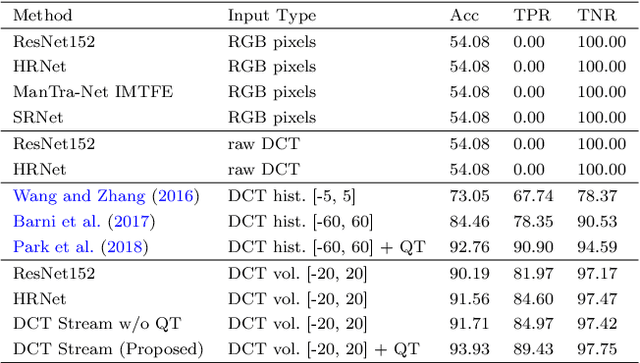
Detecting and localizing image manipulation are necessary to counter malicious use of image editing techniques. Accordingly, it is essential to distinguish between authentic and tampered regions by analyzing intrinsic statistics in an image. We focus on JPEG compression artifacts left during image acquisition and editing. We propose a convolutional neural network (CNN) that uses discrete cosine transform (DCT) coefficients, where compression artifacts remain, to localize image manipulation. Standard CNNs cannot learn the distribution of DCT coefficients because the convolution throws away the spatial coordinates, which are essential for DCT coefficients. We illustrate how to design and train a neural network that can learn the distribution of DCT coefficients. Furthermore, we introduce Compression Artifact Tracing Network (CAT-Net) that jointly uses image acquisition artifacts and compression artifacts. It significantly outperforms traditional and deep neural network-based methods in detecting and localizing tampered regions.
Detection of Double Compression in MPEG-4 Videos Using Refined Features-based CNN
Jul 19, 2021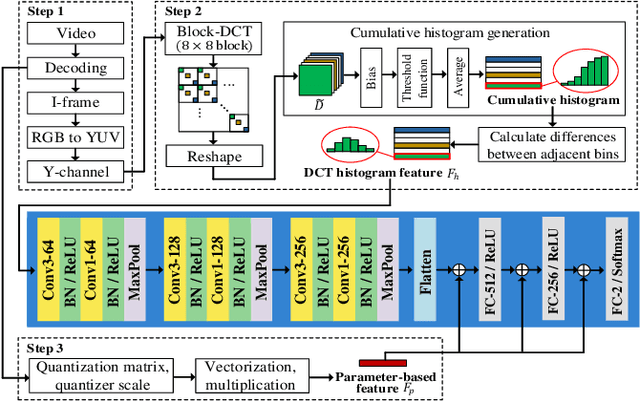
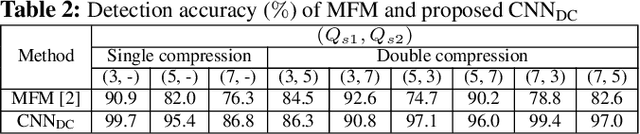
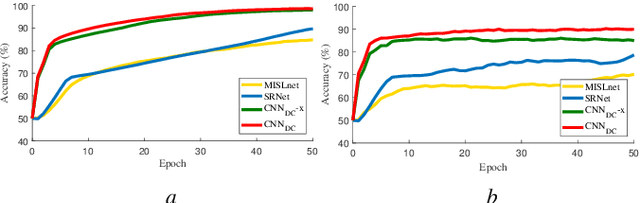
Double compression is accompanied by various types of video manipulation and its traces can be exploited to determine whether a video is a forgery. This Letter presents a convolutional neural network for detecting double compression in MPEG-4 videos. Through analysis of the intra-coding process, we utilize two refined features for capturing the subtle artifacts caused by double compression. The discrete cosine transform (DCT) histogram feature effectively detects the change of statistical characteristics in DCT coefficients and the parameter-based feature is utilized as auxiliary information to help the network learn double compression artifacts. When compared with state-of-the-art networks and forensic method, the results show that the proposed approach achieves a higher performance.
Frame-rate Up-conversion Detection Based on Convolutional Neural Network for Learning Spatiotemporal Features
Mar 25, 2021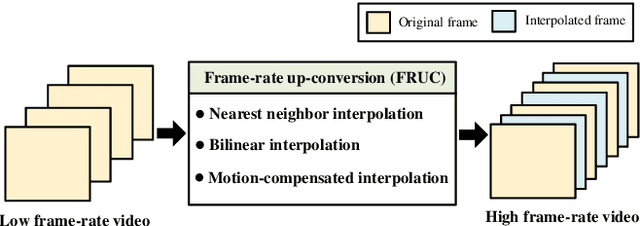
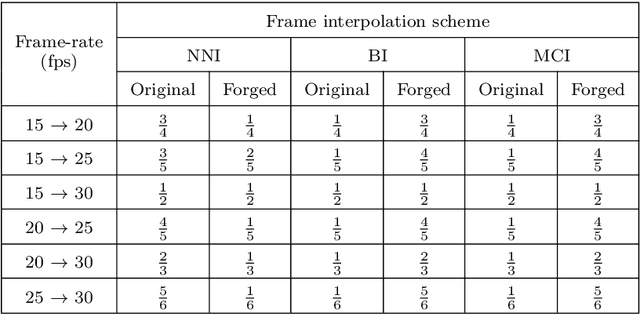
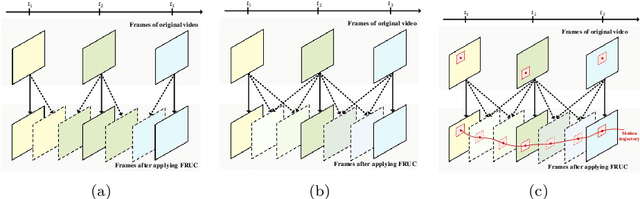
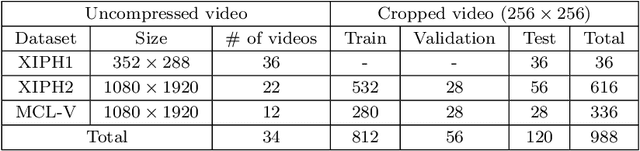
With the advance in user-friendly and powerful video editing tools, anyone can easily manipulate videos without leaving prominent visual traces. Frame-rate up-conversion (FRUC), a representative temporal-domain operation, increases the motion continuity of videos with a lower frame-rate and is used by malicious counterfeiters in video tampering such as generating fake frame-rate video without improving the quality or mixing temporally spliced videos. FRUC is based on frame interpolation schemes and subtle artifacts that remain in interpolated frames are often difficult to distinguish. Hence, detecting such forgery traces is a critical issue in video forensics. This paper proposes a frame-rate conversion detection network (FCDNet) that learns forensic features caused by FRUC in an end-to-end fashion. The proposed network uses a stack of consecutive frames as the input and effectively learns interpolation artifacts using network blocks to learn spatiotemporal features. This study is the first attempt to apply a neural network to the detection of FRUC. Moreover, it can cover the following three types of frame interpolation schemes: nearest neighbor interpolation, bilinear interpolation, and motion-compensated interpolation. In contrast to existing methods that exploit all frames to verify integrity, the proposed approach achieves a high detection speed because it observes only six frames to test its authenticity. Extensive experiments were conducted with conventional forensic methods and neural networks for video forensic tasks to validate our research. The proposed network achieved state-of-the-art performance in terms of detecting the interpolated artifacts of FRUC. The experimental results also demonstrate that our trained model is robust for an unseen dataset, unlearned frame-rate, and unlearned quality factor.
Puzzle-CAM: Improved localization via matching partial and full features
Feb 02, 2021
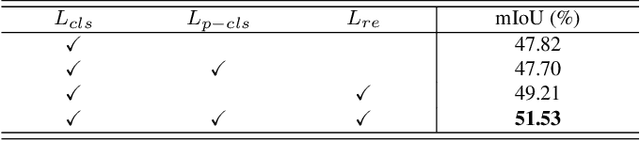
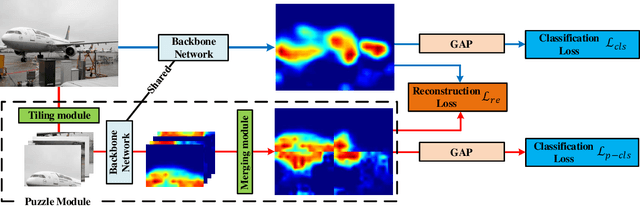
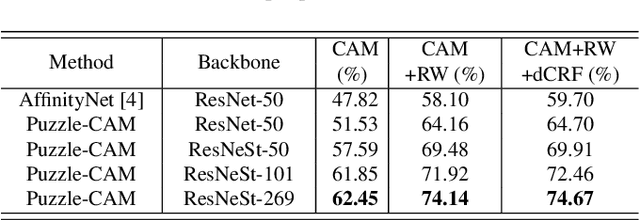
Weakly-supervised semantic segmentation (WSSS) is introduced to narrow the gap for semantic segmentation performance from pixel-level supervision to image-level supervision. Most advanced approaches are based on class activation maps (CAMs) to generate pseudo-labels to train the segmentation network. The main limitation of WSSS is that the process of generating pseudo-labels from CAMs that use an image classifier is mainly focused on the most discriminative parts of the objects. To address this issue, we propose Puzzle-CAM, a process that minimizes differences between the features from separate patches and the whole image. Our method consists of a puzzle module and two regularization terms to discover the most integrated region in an object. Puzzle-CAM can activate the overall region of an object using image-level supervision without requiring extra parameters. % In experiments, Puzzle-CAM outperformed previous state-of-the-art methods using the same labels for supervision on the PASCAL VOC 2012 test dataset. In experiments, Puzzle-CAM outperformed previous state-of-the-art methods using the same labels for supervision on the PASCAL VOC 2012 dataset. Code associated with our experiments is available at https://github.com/OFRIN/PuzzleCAM.
WAN: Watermarking Attack Network
Aug 14, 2020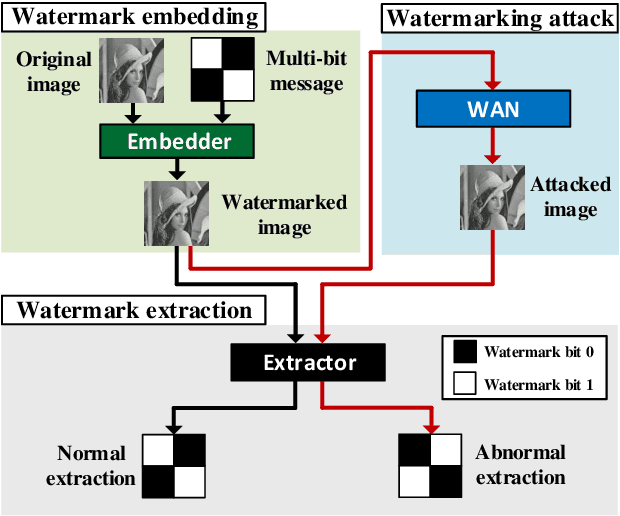

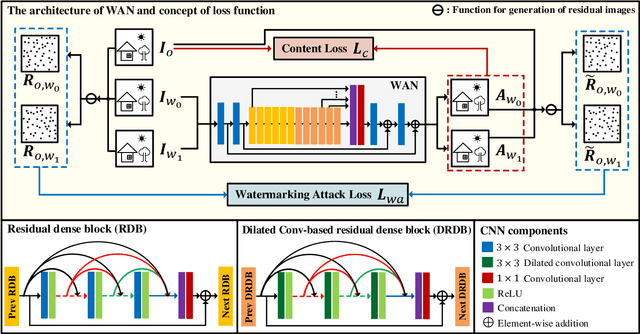

Multi-bit watermarking (MW) has been developed to improve robustness against signal processing operations and geometric distortions. To this end, several benchmark tools that simulate possible attacks on images to test robustness are available. However, limitations in these general attacks exist since they cannot exploit specific characteristics of the targeted MW. In addition, these attacks are usually devised without consideration for visual quality, which rarely occurs in the real world. To address these limitations, we propose a watermarking attack network (WAN), a fully trainable watermarking benchmark tool, that utilizes the weak points of the target MW and removes inserted watermark and inserts inverted bit information, thereby considerably reducing watermark extractability. To hinder the extraction of hidden information while ensuring high visual quality, we utilize a residual dense blocks-based architecture specialized in local and global feature learning. A novel watermarking attack loss is introduced to break the MW systems. We empirically demonstrate that the WAN can successfully fool a variety of MW systems.
Deep Convolutional Neural Network for Identifying Seam-Carving Forgery
Jul 07, 2020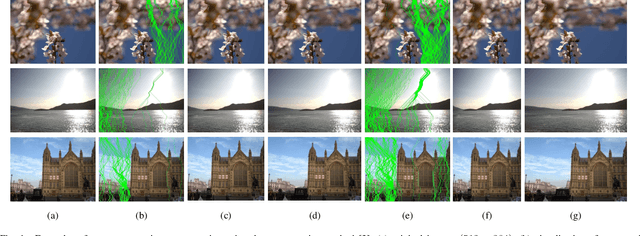
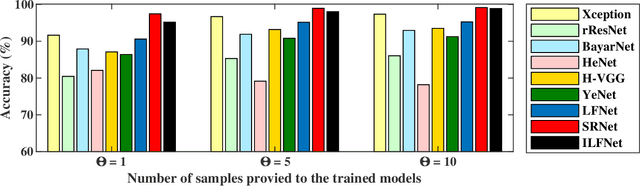

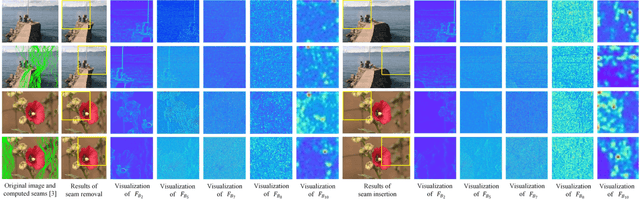
Seam carving is a representative content-aware image retargeting approach to adjust the size of an image while preserving its visually prominent content. To maintain visually important content, seam-carving algorithms first calculate the connected path of pixels, referred to as the seam, according to a defined cost function and then adjust the size of an image by removing and duplicating repeatedly calculated seams. Seam carving is actively exploited to overcome diversity in the resolution of images between applications and devices; hence, detecting the distortion caused by seam carving has become important in image forensics. In this paper, we propose a convolutional neural network (CNN)-based approach to classifying seam-carving-based image retargeting for reduction and expansion. To attain the ability to learn low-level features, we designed a CNN architecture comprising five types of network blocks specialized for capturing subtle signals. An ensemble module is further adopted to both enhance performance and comprehensively analyze the features in the local areas of the given image. To validate the effectiveness of our work, extensive experiments based on various CNN-based baselines were conducted. Compared to the baselines, our work exhibits state-of-the-art performance in terms of three-class classification (original, seam inserted, and seam removed). In addition, our model with the ensemble module is robust for various unseen cases. The experimental results also demonstrate that our method can be applied to localize both seam-removed and seam-inserted areas.
BitMix: Data Augmentation for Image Steganalysis
Jun 30, 2020
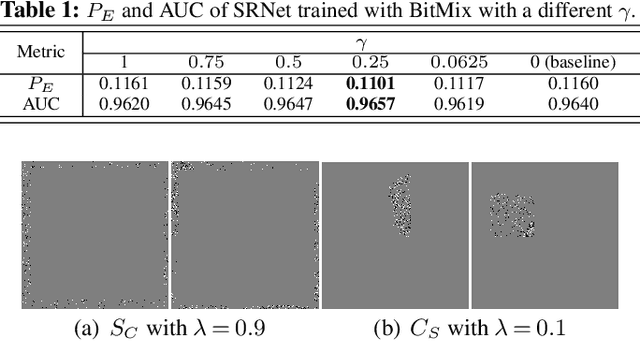
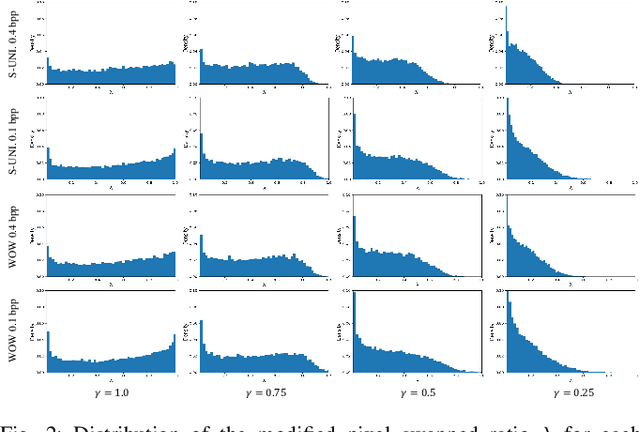
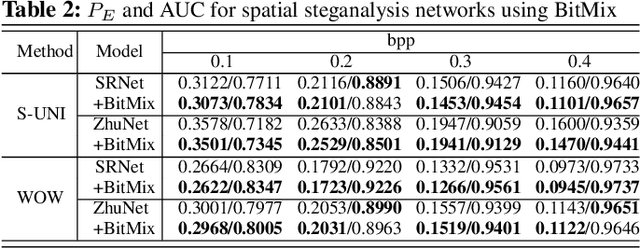
Convolutional neural networks (CNN) for image steganalysis demonstrate better performances with employing concepts from high-level vision tasks. The major employed concept is to use data augmentation to avoid overfitting due to limited data. To augment data without damaging the message embedding, only rotating multiples of 90 degrees or horizontally flipping are used in steganalysis, which generates eight fixed results from one sample. To overcome this limitation, we propose BitMix, a data augmentation method for spatial image steganalysis. BitMix mixes a cover and stego image pair by swapping the random patch and generates an embedding adaptive label with the ratio of the number of pixels modified in the swapped patch to those in the cover-stego pair. We explore optimal hyperparameters, the ratio of applying BitMix in the mini-batch, and the size of the bounding box for swapping patch. The results reveal that using BitMix improves the performance of spatial image steganalysis and better than other data augmentation methods.