 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcoustic Prompting via Stage-wise Modulation for Few-Shot Learning in Audio Language Models
Jun 14, 2026Audio-Language Models (ALMs) have shown remarkable success in zero-shot audio classification by aligning audio waveforms with text. Recent efforts to improve downstream performance focus on learning optimal text prompts. However, previous approaches focus on the text encoder, leaving the potential of learnable prompts within the audio encoder unexplored. In this paper, we propose a novel framework that introduces trainable prompts into the audio encoder to capture task-specific acoustic features. We demonstrate that integrating audio-side prompt learning with existing text-side approaches enhances few-shot adaptation. Through extensive experiments across 11 datasets show that integrating our method as a plug-and-play module alongside existing text prompt tuning generally leads to performance improvements. These findings suggest that explicitly modulating the audio representation space effectively complements text-only prompting approaches. The code is available at https://github.com/hyebin-c/aspl.
Jailbreak to Protect: Buffering and Reinforcing via Temporary Jailbreaking for Safe Fine-Tuning in Large Language Models
May 23, 2026Fine-tuning-as-a-Service (FaaS) enables personalization of large language models (LLMs), but it can weaken safety-alignment under harmful fine-tuning attacks. Recent work has shown that activating harmful-behavior modules during fine-tuning can prevent models from learning undesired behaviors, but its mechanism remains unclear. In this paper, we revisit temporary jailbreaking as a defense against harmful fine-tuning and provide a gradient-level analysis showing that it saturates safety-degrading gradients while preserving benign task-relevant gradients. Based on this insight, we propose a Buffer-and-Reinforce fine-tuning framework that buffers harmful updates during user fine-tuning and reinforces safety after adaptation. Specifically, BufferLoRA induces temporary jailbreaking as a removable adapter to reduce harmful updates during user fine-tuning. After adaptation, ReinforceLoRA, trained to recover refusal behavior under the temporarily jailbroken state, is integrated with UserLoRA via QR decomposition-based merging to reinforce safety while preserving user-task performance. Extensive experiments show that our framework achieves superior safety and utility with no additional safety data during user fine-tuning and minimal computational cost.
Query-Conditioned Test-Time Self-Training for Large Language Models
May 14, 2026Large language models (LLMs) are typically deployed with fixed parameters, and their performance is often improved by allocating more computation at inference time. While such test-time scaling can be effective, it cannot correct model misconceptions or adapt the model to the specific structure of an individual query. Test-time optimization addresses this limitation by enabling parameter updates during inference, but existing approaches either rely on external data or optimize generic self-supervised objectives that lack query-specific alignment. In this work, we propose Query-Conditioned Test-Time Self-Training (QueST), a framework that adapts model parameters during inference using supervision derived directly from the input query. Our key insight is that the input query itself encodes latent signals sufficient for constructing structurally related problem--solution pairs. Based on this, QueST generates such query-conditioned pairs and uses them as supervision for parameter-efficient fine-tuning at test time. The adapted model is then used to produce the final answer, enabling query-specific adaptation without any external data. Across seven mathematical reasoning benchmarks and the GPQA-Diamond scientific reasoning benchmark, QueST consistently outperforms strong test-time optimization baselines. These results demonstrate that query-conditioned self-training is an effective and practical paradigm for test-time adaptation in LLMs. Code is available at https://chssong.github.io/Query-Conditioned-TTST/.
Detecting AI-Generated Videos with Spiking Neural Networks
May 07, 2026Modern AI-generated videos are photorealistic at the single-frame level, leaving inter-frame dynamics as the main remaining axis for detection. Existing detectors typically handle this temporal evidence in three ways: feeding the full frame sequence to a generic temporal backbone, reducing one dominant temporal cue to fixed video-level descriptors, or comparing temporal features to real-video statistics through a detection metric. These strategies degrade sharply under cross-generator evaluation, where artifact type and timescale vary across generators. On caption-paired benchmark, GenVidBench, we identify two signatures that prior detectors do not jointly exploit: AI-generated videos exhibit smoother frame-to-frame temporal residuals at the pixel level, and more compact trajectories in the semantic feature space, indicating a temporal smoothness gap at both levels. We further observe that, when raw video is fed into a Spiking Neural Networks (SNNs), fake clips elicit firing predominantly at object and motion boundaries, unlike real clips, suggesting that the SNN responds to temporal artifacts localized at edges. These cues are sparse, asynchronous, and concentrated at moments of change, which makes SNNs a natural choice for this task: their event-driven, sparsely-activated dynamics align with the structure of the residual signal in a way that dense ANN backbones do not. Building on this observation, we propose MAST, a detector that processes multi-channel temporal residuals with a spike-driven temporal branch alongside a frozen semantic encoder for cross-generator generalization. On the GenVideo benchmark, MAST achieves 93.14\% mean accuracy across 10 unseen generators under strict cross-generator evaluation, matching or surpassing the strongest ANN-based detectors and demonstrating the practical applicability of SNNs to AI-generated video detection.
Multimodal Self-Attention Network with Temporal Alignment for Audio-Visual Emotion Recognition
Mar 11, 2026Audio-visual emotion recognition (AVER) methods typically fuse utterance-level features, and even frame-level attention models seldom address the frame-rate mismatch across modalities. In this paper, we propose a Transformer-based framework focusing on the temporal alignment of multimodal features. Our design employs a multimodal self-attention encoder that simultaneously captures intra- and inter-modal dependencies within a shared feature space. To address heterogeneous sampling rates, we incorporate Temporally-aligned Rotary Position Embeddings (TaRoPE), which implicitly synchronize audio and video tokens. Furthermore, we introduce a Cross-Temporal Matching (CTM) loss that enforces consistency among temporally proximate pairs, guiding the encoder toward better alignment. Experiments on CREMA-D and RAVDESS datasets demonstrate consistent improvements over recent baselines, suggesting that explicitly addressing frame-rate mismatch helps preserve temporal cues and enhances cross-modal fusion.
Efficient Test-Time Optimization for Depth Completion via Low-Rank Decoder Adaptation
Mar 03, 2026Zero-shot depth completion has gained attention for its ability to generalize across environments without sensor-specific datasets or retraining. However, most existing approaches rely on diffusion-based test-time optimization, which is computationally expensive due to iterative denoising. Recent visual-prompt-based methods reduce training cost but still require repeated forward--backward passes through the full frozen network to optimize input-level prompts, resulting in slow inference. In this work, we show that adapting only the decoder is sufficient for effective test-time optimization, as depth foundation models concentrate depth-relevant information within a low-dimensional decoder subspace. Based on this insight, we propose a lightweight test-time adaptation method that updates only this low-dimensional subspace using sparse depth supervision. Our approach achieves state-of-the-art performance, establishing a new Pareto frontier between accuracy and efficiency for test-time adaptation. Extensive experiments on five indoor and outdoor datasets demonstrate consistent improvements over prior methods, highlighting the practicality of fast zero-shot depth completion.
Station2Radar: query conditioned gaussian splatting for precipitation field
Feb 28, 2026Precipitation forecasting relies on heterogeneous data. Weather radar is accurate, but coverage is geographically limited and costly to maintain. Weather stations provide accurate but sparse point measurements, while satellites offer dense, high-resolution coverage without direct rainfall retrieval. To overcome these limitations, we propose Query-Conditioned Gaussian Splatting (QCGS), the first framework to fuse automatic weather station (AWS) observations with satellite imagery for generating precipitation fields. Unlike conventional 2D Gaussian splatting, which renders the entire image plane, QCGS selectively renders only queried precipitation regions, avoiding unnecessary computation in non-precipitating areas while preserving sharp precipitation structures. The framework combines a radar point proposal network that identifies rainfall-support locations with an implicit neural representation (INR) network that predicts Gaussian parameters for each point. QCGS enables efficient, resolution-flexible precipitation field generation in real time. Through extensive evaluation with benchmark precipitation products, QCGS demonstrates over 50\% improvement in RMSE compared to conventional gridded precipitation products, and consistently maintains high performance across multiple spatiotemporal scales.
CINEMAE: Leveraging Frozen Masked Autoencoders for Cross-Generator AI Image Detection
Nov 09, 2025While context-based detectors have achieved strong generalization for AI-generated text by measuring distributional inconsistencies, image-based detectors still struggle with overfitting to generator-specific artifacts. We introduce CINEMAE, a novel paradigm for AIGC image detection that adapts the core principles of text detection methods to the visual domain. Our key insight is that Masked AutoEncoder (MAE), trained to reconstruct masked patches conditioned on visible context, naturally encodes semantic consistency expectations. We formalize this reconstruction process probabilistically, computing conditional Negative Log-Likelihood (NLL, p(masked | visible)) to quantify local semantic anomalies. By aggregating these patch-level statistics with global MAE features through learned fusion, CINEMAE achieves strong cross-generator generalization. Trained exclusively on Stable Diffusion v1.4, our method achieves over 95% accuracy on all eight unseen generators in the GenImage benchmark, substantially outperforming state-of-the-art detectors. This demonstrates that context-conditional reconstruction uncertainty provides a robust, transferable signal for AIGC detection.
Refusal-Feature-guided Teacher for Safe Finetuning via Data Filtering and Alignment Distillation
Jun 09, 2025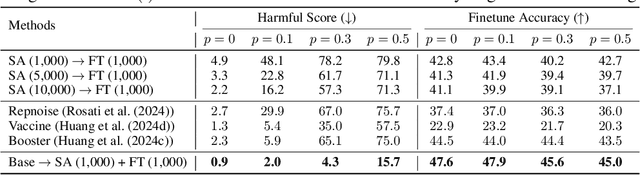
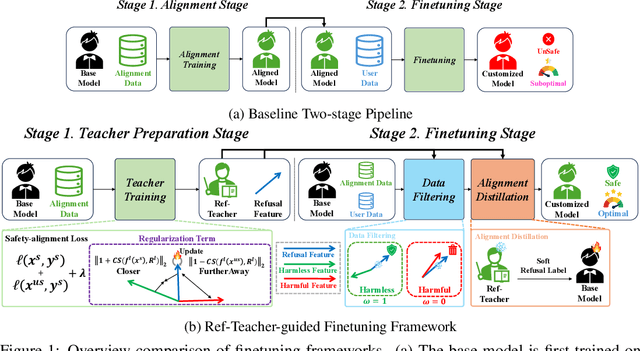
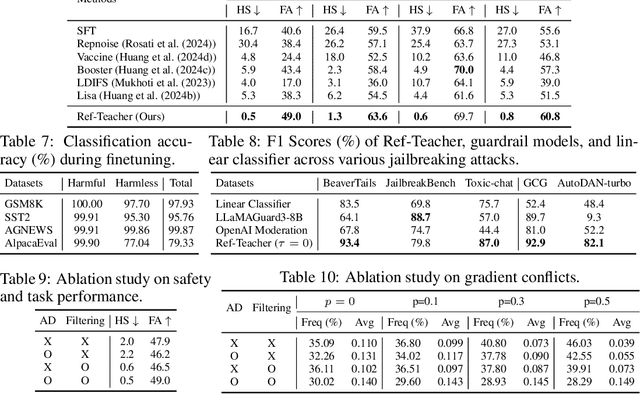

Recently, major AI service providers such as Google and OpenAI have introduced Finetuning-as-a-Service, which enables users to customize Large Language Models (LLMs) for specific downstream tasks using their own data. However, this service is vulnerable to degradation of LLM safety-alignment when user data contains harmful prompts. While some prior works address this issue, fundamentally filtering harmful data from user data remains unexplored. Motivated by our observation that a directional representation reflecting refusal behavior (called the refusal feature) obtained from safety-aligned LLMs can inherently distinguish between harmful and harmless prompts, we propose the Refusal-Feature-guided Teacher (ReFT). Our ReFT model is trained to identify harmful prompts based on the similarity between input prompt features and its refusal feature. During finetuning, the ReFT model serves as a teacher that filters harmful prompts from user data and distills alignment knowledge into the base model. Extensive experiments demonstrate that our ReFT-based finetuning strategy effectively minimizes harmful outputs and enhances finetuning accuracy for user-specific tasks, offering a practical solution for secure and reliable deployment of LLMs in Finetuning-as-a-Service.
Benign-to-Toxic Jailbreaking: Inducing Harmful Responses from Harmless Prompts
May 26, 2025Optimization-based jailbreaks typically adopt the Toxic-Continuation setting in large vision-language models (LVLMs), following the standard next-token prediction objective. In this setting, an adversarial image is optimized to make the model predict the next token of a toxic prompt. However, we find that the Toxic-Continuation paradigm is effective at continuing already-toxic inputs, but struggles to induce safety misalignment when explicit toxic signals are absent. We propose a new paradigm: Benign-to-Toxic (B2T) jailbreak. Unlike prior work, we optimize adversarial images to induce toxic outputs from benign conditioning. Since benign conditioning contains no safety violations, the image alone must break the model's safety mechanisms. Our method outperforms prior approaches, transfers in black-box settings, and complements text-based jailbreaks. These results reveal an underexplored vulnerability in multimodal alignment and introduce a fundamentally new direction for jailbreak approaches.