 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefusal-Feature-guided Teacher for Safe Finetuning via Data Filtering and Alignment Distillation
Jun 09, 2025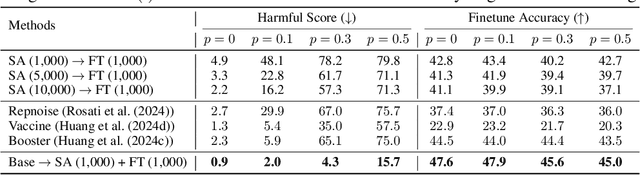
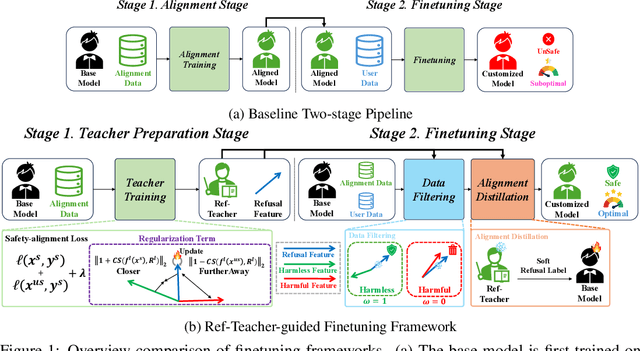
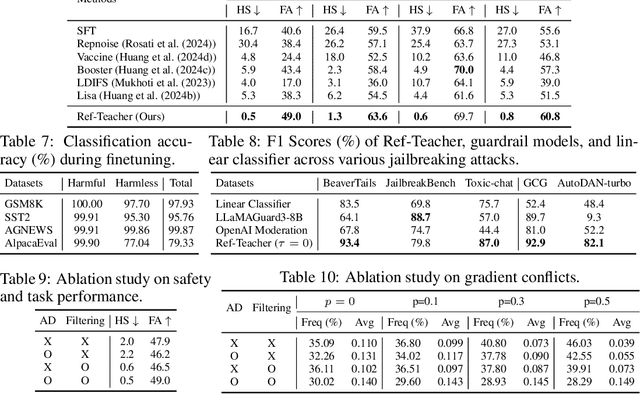

Recently, major AI service providers such as Google and OpenAI have introduced Finetuning-as-a-Service, which enables users to customize Large Language Models (LLMs) for specific downstream tasks using their own data. However, this service is vulnerable to degradation of LLM safety-alignment when user data contains harmful prompts. While some prior works address this issue, fundamentally filtering harmful data from user data remains unexplored. Motivated by our observation that a directional representation reflecting refusal behavior (called the refusal feature) obtained from safety-aligned LLMs can inherently distinguish between harmful and harmless prompts, we propose the Refusal-Feature-guided Teacher (ReFT). Our ReFT model is trained to identify harmful prompts based on the similarity between input prompt features and its refusal feature. During finetuning, the ReFT model serves as a teacher that filters harmful prompts from user data and distills alignment knowledge into the base model. Extensive experiments demonstrate that our ReFT-based finetuning strategy effectively minimizes harmful outputs and enhances finetuning accuracy for user-specific tasks, offering a practical solution for secure and reliable deployment of LLMs in Finetuning-as-a-Service.
RITUAL: Random Image Transformations as a Universal Anti-hallucination Lever in LVLMs
May 28, 2024



Recent advancements in Large Vision Language Models (LVLMs) have revolutionized how machines understand and generate textual responses based on visual inputs. Despite their impressive capabilities, they often produce "hallucinatory" outputs that do not accurately reflect the visual information, posing challenges in reliability and trustworthiness. Current methods such as contrastive decoding have made strides in addressing these issues by contrasting the original probability distribution of generated tokens with distorted counterparts; yet, generating visually-faithful outputs remains a challenge. In this work, we shift our focus to the opposite: What could serve as a complementary enhancement to the original probability distribution? We propose a simple, training-free method termed RITUAL to enhance robustness against hallucinations in LVLMs. Our approach employs random image transformations as complements to the original probability distribution, aiming to mitigate the likelihood of hallucinatory visual explanations by enriching the model's exposure to varied visual scenarios. Our empirical results show that while the isolated use of transformed images initially degrades performance, strategic implementation of these transformations can indeed serve as effective complements. Notably, our method is compatible with current contrastive decoding methods and does not require external models or costly self-feedback mechanisms, making it a practical addition. In experiments, RITUAL significantly outperforms existing contrastive decoding methods across several object hallucination benchmarks, including POPE, CHAIR, and MME.
Don't Miss the Forest for the Trees: Attentional Vision Calibration for Large Vision Language Models
May 28, 2024This study addresses the issue observed in Large Vision Language Models (LVLMs), where excessive attention on a few image tokens, referred to as blind tokens, leads to hallucinatory responses in tasks requiring fine-grained understanding of visual objects. We found that tokens receiving lower attention weights often hold essential information for identifying nuanced object details -- ranging from merely recognizing object existence to identifying their attributes (color, position, etc.) and understanding their relationships. To counteract the over-emphasis on blind tokens and to accurately respond to user queries, we introduce a technique called Attentional Vision Calibration (AVC). During the decoding phase, AVC identifies blind tokens by analyzing the image-related attention distribution. It then dynamically adjusts the logits for the next token prediction by contrasting the logits conditioned on the original visual tokens with those conditioned on the blind tokens. This effectively lowers the dependency on blind tokens and promotes a more balanced consideration of all tokens. We validate AVC on benchmarks such as POPE, MME, and AMBER, where it consistently outperforms existing decoding techniques in mitigating object hallucinations in LVLMs.