 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefusal-Feature-guided Teacher for Safe Finetuning via Data Filtering and Alignment Distillation
Jun 09, 2025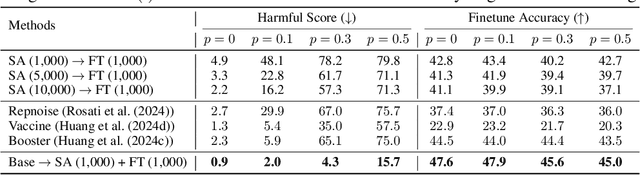
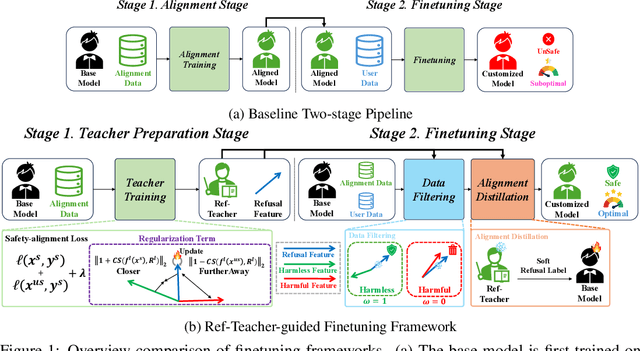
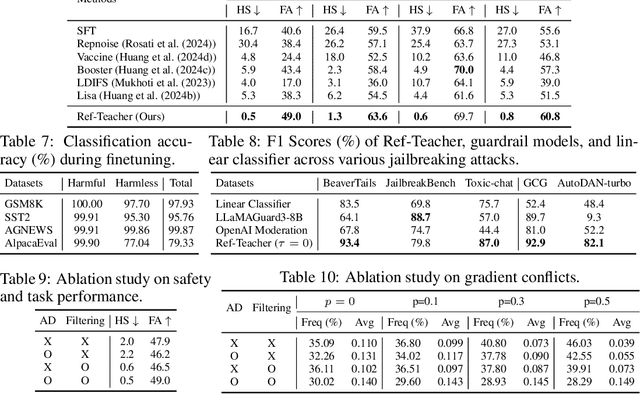

Recently, major AI service providers such as Google and OpenAI have introduced Finetuning-as-a-Service, which enables users to customize Large Language Models (LLMs) for specific downstream tasks using their own data. However, this service is vulnerable to degradation of LLM safety-alignment when user data contains harmful prompts. While some prior works address this issue, fundamentally filtering harmful data from user data remains unexplored. Motivated by our observation that a directional representation reflecting refusal behavior (called the refusal feature) obtained from safety-aligned LLMs can inherently distinguish between harmful and harmless prompts, we propose the Refusal-Feature-guided Teacher (ReFT). Our ReFT model is trained to identify harmful prompts based on the similarity between input prompt features and its refusal feature. During finetuning, the ReFT model serves as a teacher that filters harmful prompts from user data and distills alignment knowledge into the base model. Extensive experiments demonstrate that our ReFT-based finetuning strategy effectively minimizes harmful outputs and enhances finetuning accuracy for user-specific tasks, offering a practical solution for secure and reliable deployment of LLMs in Finetuning-as-a-Service.
Long-tailed Adversarial Training with Self-Distillation
Mar 09, 2025Adversarial training significantly enhances adversarial robustness, yet superior performance is predominantly achieved on balanced datasets. Addressing adversarial robustness in the context of unbalanced or long-tailed distributions is considerably more challenging, mainly due to the scarcity of tail data instances. Previous research on adversarial robustness within long-tailed distributions has primarily focused on combining traditional long-tailed natural training with existing adversarial robustness methods. In this study, we provide an in-depth analysis for the challenge that adversarial training struggles to achieve high performance on tail classes in long-tailed distributions. Furthermore, we propose a simple yet effective solution to advance adversarial robustness on long-tailed distributions through a novel self-distillation technique. Specifically, this approach leverages a balanced self-teacher model, which is trained using a balanced dataset sampled from the original long-tailed dataset. Our extensive experiments demonstrate state-of-the-art performance in both clean and robust accuracy for long-tailed adversarial robustness, with significant improvements in tail class performance on various datasets. We improve the accuracy against PGD attacks for tail classes by 20.3, 7.1, and 3.8 percentage points on CIFAR-10, CIFAR-100, and Tiny-ImageNet, respectively, while achieving the highest robust accuracy.
Class Incremental Learning for Adversarial Robustness
Dec 07, 2023Adversarial training integrates adversarial examples during model training to enhance robustness. However, its application in fixed dataset settings differs from real-world dynamics, where data accumulates incrementally. In this study, we investigate Adversarially Robust Class Incremental Learning (ARCIL), a method that combines adversarial robustness with incremental learning. We observe that combining incremental learning with naive adversarial training easily leads to a loss of robustness. We discover that this is attributed to the disappearance of the flatness of the loss function, a characteristic of adversarial training. To address this issue, we propose the Flatness Preserving Distillation (FPD) loss that leverages the output difference between adversarial and clean examples. Additionally, we introduce the Logit Adjustment Distillation (LAD) loss, which adapts the model's knowledge to perform well on new tasks. Experimental results demonstrate the superiority of our method over approaches that apply adversarial training to existing incremental learning methods, which provides a strong baseline for incremental learning on adversarial robustness in the future. Our method achieves AutoAttack accuracy that is 5.99\%p, 5.27\%p, and 3.90\%p higher on average than the baseline on split CIFAR-10, CIFAR-100, and Tiny ImageNet, respectively. The code will be made available.
Indirect Gradient Matching for Adversarial Robust Distillation
Dec 06, 2023Adversarial training significantly improves adversarial robustness, but superior performance is primarily attained with large models. This substantial performance gap for smaller models has spurred active research into adversarial distillation (AD) to mitigate the difference. Existing AD methods leverage the teacher's logits as a guide. In contrast to these approaches, we aim to transfer another piece of knowledge from the teacher, the input gradient. In this paper, we propose a distillation module termed Indirect Gradient Distillation Module (IGDM) that indirectly matches the student's input gradient with that of the teacher. We hypothesize that students can better acquire the teacher's knowledge by matching the input gradient. Leveraging the observation that adversarial training renders the model locally linear on the input space, we employ Taylor approximation to effectively align gradients without directly calculating them. Experimental results show that IGDM seamlessly integrates with existing AD methods, significantly enhancing the performance of all AD methods. Particularly, utilizing IGDM on the CIFAR-100 dataset improves the AutoAttack accuracy from 28.06% to 30.32% with the ResNet-18 model and from 26.18% to 29.52% with the MobileNetV2 model when integrated into the SOTA method without additional data augmentation. The code will be made available.
Introducing Competition to Boost the Transferability of Targeted Adversarial Examples through Clean Feature Mixup
May 24, 2023Deep neural networks are widely known to be susceptible to adversarial examples, which can cause incorrect predictions through subtle input modifications. These adversarial examples tend to be transferable between models, but targeted attacks still have lower attack success rates due to significant variations in decision boundaries. To enhance the transferability of targeted adversarial examples, we propose introducing competition into the optimization process. Our idea is to craft adversarial perturbations in the presence of two new types of competitor noises: adversarial perturbations towards different target classes and friendly perturbations towards the correct class. With these competitors, even if an adversarial example deceives a network to extract specific features leading to the target class, this disturbance can be suppressed by other competitors. Therefore, within this competition, adversarial examples should take different attack strategies by leveraging more diverse features to overwhelm their interference, leading to improving their transferability to different models. Considering the computational complexity, we efficiently simulate various interference from these two types of competitors in feature space by randomly mixing up stored clean features in the model inference and named this method Clean Feature Mixup (CFM). Our extensive experimental results on the ImageNet-Compatible and CIFAR-10 datasets show that the proposed method outperforms the existing baselines with a clear margin. Our code is available at https://github.com/dreamflake/CFM.
RainUNet for Super-Resolution Rain Movie Prediction under Spatio-temporal Shifts
Dec 07, 2022



This paper presents a solution to the Weather4cast 2022 Challenge Stage 2. The goal of the challenge is to forecast future high-resolution rainfall events obtained from ground radar using low-resolution multiband satellite images. We suggest a solution that performs data preprocessing appropriate to the challenge and then predicts rainfall movies using a novel RainUNet. RainUNet is a hierarchical U-shaped network with temporal-wise separable block (TS block) using a decoupled large kernel 3D convolution to improve the prediction performance. Various evaluation metrics show that our solution is effective compared to the baseline method. The source codes are available at https://github.com/jinyxp/Weather4cast-2022
Improving the Transferability of Targeted Adversarial Examples through Object-Based Diverse Input
Mar 17, 2022
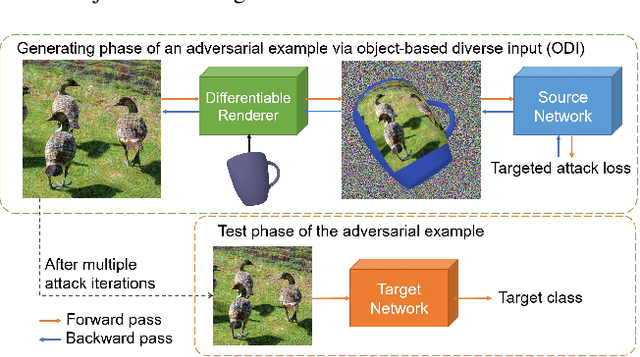
The transferability of adversarial examples allows the deception on black-box models, and transfer-based targeted attacks have attracted a lot of interest due to their practical applicability. To maximize the transfer success rate, adversarial examples should avoid overfitting to the source model, and image augmentation is one of the primary approaches for this. However, prior works utilize simple image transformations such as resizing, which limits input diversity. To tackle this limitation, we propose the object-based diverse input (ODI) method that draws an adversarial image on a 3D object and induces the rendered image to be classified as the target class. Our motivation comes from the humans' superior perception of an image printed on a 3D object. If the image is clear enough, humans can recognize the image content in a variety of viewing conditions. Likewise, if an adversarial example looks like the target class to the model, the model should also classify the rendered image of the 3D object as the target class. The ODI method effectively diversifies the input by leveraging an ensemble of multiple source objects and randomizing viewing conditions. In our experimental results on the ImageNet-Compatible dataset, this method boosts the average targeted attack success rate from 28.3% to 47.0% compared to the state-of-the-art methods. We also demonstrate the applicability of the ODI method to adversarial examples on the face verification task and its superior performance improvement. Our code is available at https://github.com/dreamflake/ODI.
Balancing Domain Experts for Long-Tailed Camera-Trap Recognition
Feb 16, 2022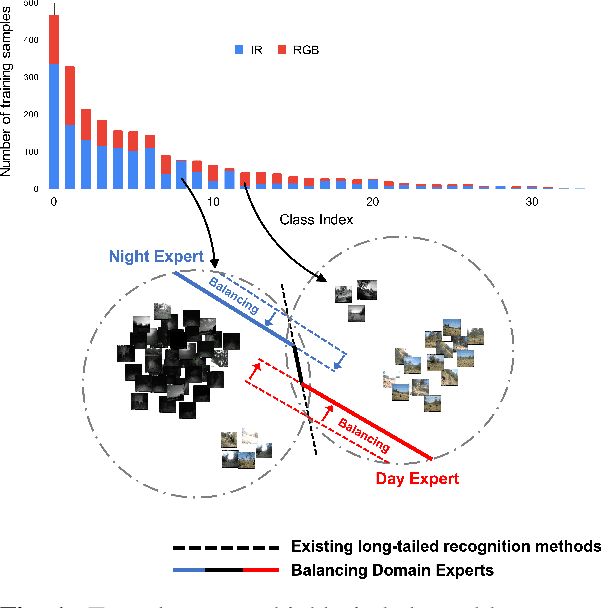
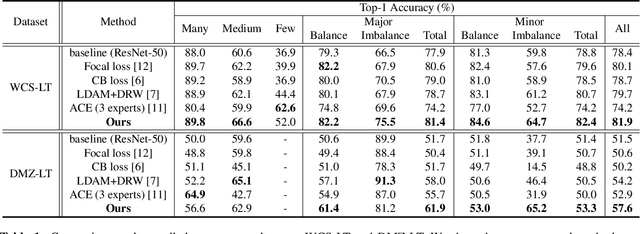
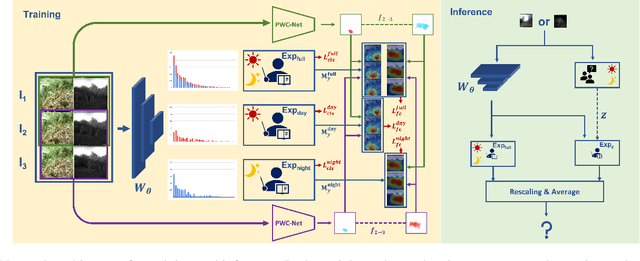
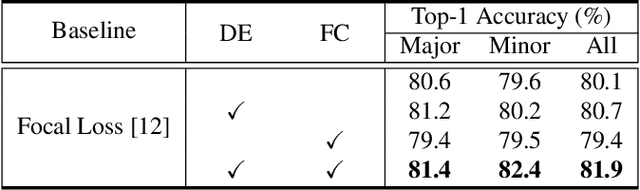
Label distributions in camera-trap images are highly imbalanced and long-tailed, resulting in neural networks tending to be biased towards head-classes that appear frequently. Although long-tail learning has been extremely explored to address data imbalances, few studies have been conducted to consider camera-trap characteristics, such as multi-domain and multi-frame setup. Here, we propose a unified framework and introduce two datasets for long-tailed camera-trap recognition. We first design domain experts, where each expert learns to balance imperfect decision boundaries caused by data imbalances and complement each other to generate domain-balanced decision boundaries. Also, we propose a flow consistency loss to focus on moving objects, expecting class activation maps of multi-frame matches the flow with optical flow maps for input images. Moreover, two long-tailed camera-trap datasets, WCS-LT and DMZ-LT, are introduced to validate our methods. Experimental results show the effectiveness of our framework, and proposed methods outperform previous methods on recessive domain samples.
CAP-GAN: Towards Adversarial Robustness with Cycle-consistent Attentional Purification
Feb 17, 2021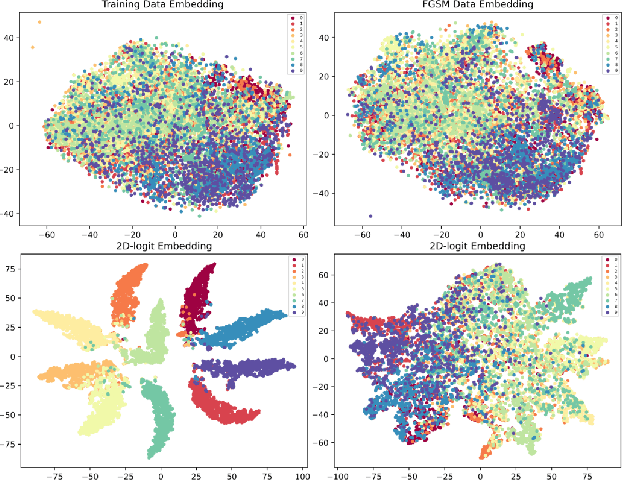
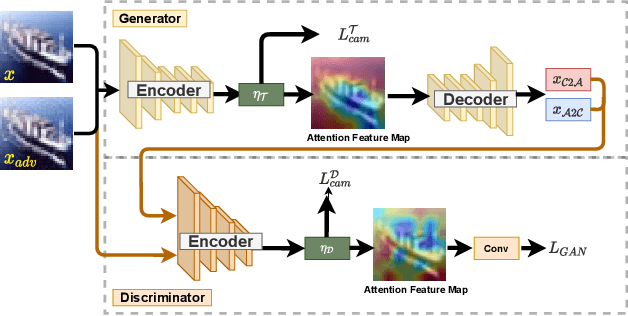
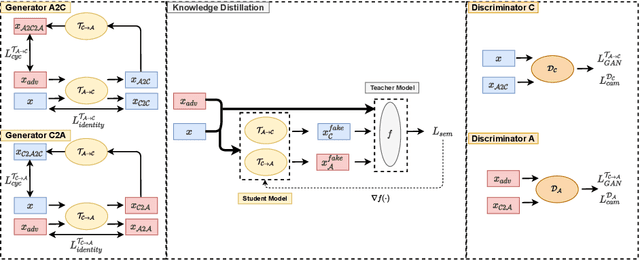
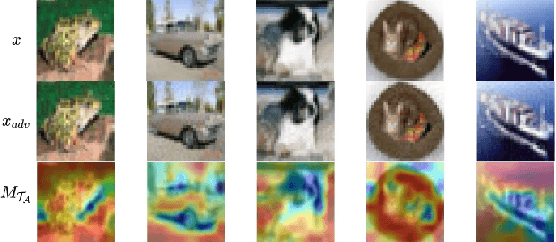
Adversarial attack is aimed at fooling the target classifier with imperceptible perturbation. Adversarial examples, which are carefully crafted with a malicious purpose, can lead to erroneous predictions, resulting in catastrophic accidents. To mitigate the effects of adversarial attacks, we propose a novel purification model called CAP-GAN. CAP-GAN takes account of the idea of pixel-level and feature-level consistency to achieve reasonable purification under cycle-consistent learning. Specifically, we utilize the guided attention module and knowledge distillation to convey meaningful information to the purification model. Once a model is fully trained, inputs would be projected into the purification model and transformed into clean-like images. We vary the capacity of the adversary to argue the robustness against various types of attack strategies. On the CIFAR-10 dataset, CAP-GAN outperforms other pre-processing based defenses under both black-box and white-box settings.
Applying Tensor Decomposition to image for Robustness against Adversarial Attack
Mar 05, 2020
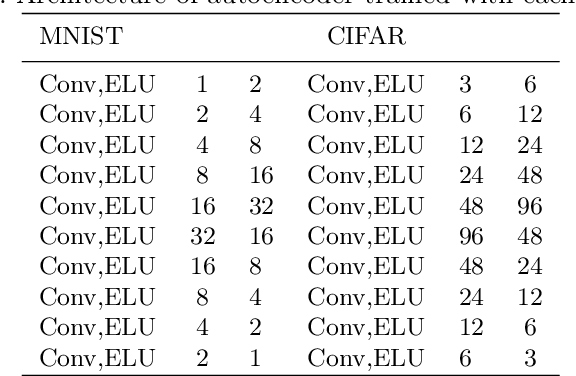
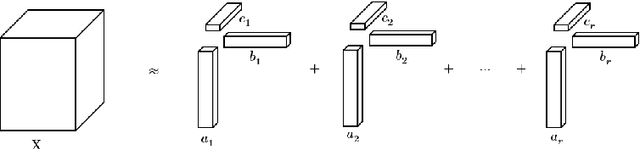
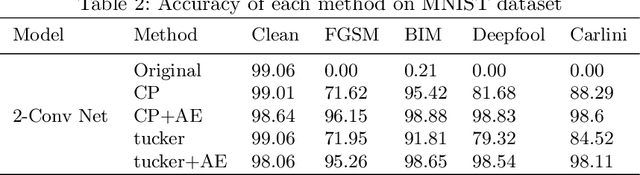
Nowadays the deep learning technology is growing faster and shows dramatic performance in computer vision areas. However, it turns out a deep learning based model is highly vulnerable to some small perturbation called an adversarial attack. It can easily fool the deep learning model by adding small perturbations. On the other hand, tensor decomposition method widely uses for compressing the tensor data, including data matrix, image, etc. In this paper, we suggest combining tensor decomposition for defending the model against adversarial example. We verify this idea is simple and effective to resist adversarial attack. In addition, this method rarely degrades the original performance of clean data. We experiment on MNIST, CIFAR10 and ImageNet data and show our method robust on state-of-the-art attack methods.