 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenign-to-Toxic Jailbreaking: Inducing Harmful Responses from Harmless Prompts
May 26, 2025Optimization-based jailbreaks typically adopt the Toxic-Continuation setting in large vision-language models (LVLMs), following the standard next-token prediction objective. In this setting, an adversarial image is optimized to make the model predict the next token of a toxic prompt. However, we find that the Toxic-Continuation paradigm is effective at continuing already-toxic inputs, but struggles to induce safety misalignment when explicit toxic signals are absent. We propose a new paradigm: Benign-to-Toxic (B2T) jailbreak. Unlike prior work, we optimize adversarial images to induce toxic outputs from benign conditioning. Since benign conditioning contains no safety violations, the image alone must break the model's safety mechanisms. Our method outperforms prior approaches, transfers in black-box settings, and complements text-based jailbreaks. These results reveal an underexplored vulnerability in multimodal alignment and introduce a fundamentally new direction for jailbreak approaches.
Doubly-Universal Adversarial Perturbations: Deceiving Vision-Language Models Across Both Images and Text with a Single Perturbation
Dec 11, 2024



Large Vision-Language Models (VLMs) have demonstrated remarkable performance across multimodal tasks by integrating vision encoders with large language models (LLMs). However, these models remain vulnerable to adversarial attacks. Among such attacks, Universal Adversarial Perturbations (UAPs) are especially powerful, as a single optimized perturbation can mislead the model across various input images. In this work, we introduce a novel UAP specifically designed for VLMs: the Doubly-Universal Adversarial Perturbation (Doubly-UAP), capable of universally deceiving VLMs across both image and text inputs. To successfully disrupt the vision encoder's fundamental process, we analyze the core components of the attention mechanism. After identifying value vectors in the middle-to-late layers as the most vulnerable, we optimize Doubly-UAP in a label-free manner with a frozen model. Despite being developed as a black-box to the LLM, Doubly-UAP achieves high attack success rates on VLMs, consistently outperforming baseline methods across vision-language tasks. Extensive ablation studies and analyses further demonstrate the robustness of Doubly-UAP and provide insights into how it influences internal attention mechanisms.
Parameter Efficient Mamba Tuning via Projector-targeted Diagonal-centric Linear Transformation
Nov 21, 2024



Despite the growing interest in Mamba architecture as a potential replacement for Transformer architecture, parameter-efficient fine-tuning (PEFT) approaches for Mamba remain largely unexplored. In our study, we introduce two key insights-driven strategies for PEFT in Mamba architecture: (1) While state-space models (SSMs) have been regarded as the cornerstone of Mamba architecture, then expected to play a primary role in transfer learning, our findings reveal that Projectors -- not SSMs -- are the predominant contributors to transfer learning, and (2) Based on our observation that adapting pretrained Projectors to new tasks can be effectively approximated through a near-diagonal linear transformation, we propose a novel PEFT method specialized to Mamba architecture: Projector-targeted Diagonal-centric Linear Transformation (ProDiaL). ProDiaL focuses on optimizing only diagonal-centric linear transformation matrices, without directly fine-tuning the pretrained Projector weights. This targeted approach allows efficient task adaptation, utilizing less than 1% of the total parameters, and exhibits strong performance across both vision and language Mamba models, highlighting its versatility and effectiveness.
VideoMamba: Spatio-Temporal Selective State Space Model
Jul 11, 2024



We introduce VideoMamba, a novel adaptation of the pure Mamba architecture, specifically designed for video recognition. Unlike transformers that rely on self-attention mechanisms leading to high computational costs by quadratic complexity, VideoMamba leverages Mamba's linear complexity and selective SSM mechanism for more efficient processing. The proposed Spatio-Temporal Forward and Backward SSM allows the model to effectively capture the complex relationship between non-sequential spatial and sequential temporal information in video. Consequently, VideoMamba is not only resource-efficient but also effective in capturing long-range dependency in videos, demonstrated by competitive performance and outstanding efficiency on a variety of video understanding benchmarks. Our work highlights the potential of VideoMamba as a powerful tool for video understanding, offering a simple yet effective baseline for future research in video analysis.
Breaking Temporal Consistency: Generating Video Universal Adversarial Perturbations Using Image Models
Nov 17, 2023As video analysis using deep learning models becomes more widespread, the vulnerability of such models to adversarial attacks is becoming a pressing concern. In particular, Universal Adversarial Perturbation (UAP) poses a significant threat, as a single perturbation can mislead deep learning models on entire datasets. We propose a novel video UAP using image data and image model. This enables us to take advantage of the rich image data and image model-based studies available for video applications. However, there is a challenge that image models are limited in their ability to analyze the temporal aspects of videos, which is crucial for a successful video attack. To address this challenge, we introduce the Breaking Temporal Consistency (BTC) method, which is the first attempt to incorporate temporal information into video attacks using image models. We aim to generate adversarial videos that have opposite patterns to the original. Specifically, BTC-UAP minimizes the feature similarity between neighboring frames in videos. Our approach is simple but effective at attacking unseen video models. Additionally, it is applicable to videos of varying lengths and invariant to temporal shifts. Our approach surpasses existing methods in terms of effectiveness on various datasets, including ImageNet, UCF-101, and Kinetics-400.
PG-RCNN: Semantic Surface Point Generation for 3D Object Detection
Jul 24, 2023One of the main challenges in LiDAR-based 3D object detection is that the sensors often fail to capture the complete spatial information about the objects due to long distance and occlusion. Two-stage detectors with point cloud completion approaches tackle this problem by adding more points to the regions of interest (RoIs) with a pre-trained network. However, these methods generate dense point clouds of objects for all region proposals, assuming that objects always exist in the RoIs. This leads to the indiscriminate point generation for incorrect proposals as well. Motivated by this, we propose Point Generation R-CNN (PG-RCNN), a novel end-to-end detector that generates semantic surface points of foreground objects for accurate detection. Our method uses a jointly trained RoI point generation module to process the contextual information of RoIs and estimate the complete shape and displacement of foreground objects. For every generated point, PG-RCNN assigns a semantic feature that indicates the estimated foreground probability. Extensive experiments show that the point clouds generated by our method provide geometrically and semantically rich information for refining false positive and misaligned proposals. PG-RCNN achieves competitive performance on the KITTI benchmark, with significantly fewer parameters than state-of-the-art models. The code is available at https://github.com/quotation2520/PG-RCNN.
Improving the Transferability of Targeted Adversarial Examples through Object-Based Diverse Input
Mar 17, 2022
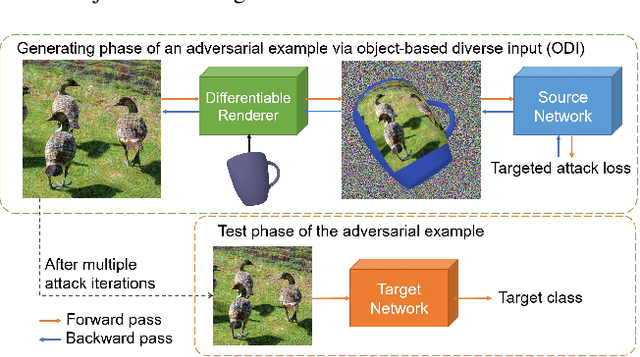
The transferability of adversarial examples allows the deception on black-box models, and transfer-based targeted attacks have attracted a lot of interest due to their practical applicability. To maximize the transfer success rate, adversarial examples should avoid overfitting to the source model, and image augmentation is one of the primary approaches for this. However, prior works utilize simple image transformations such as resizing, which limits input diversity. To tackle this limitation, we propose the object-based diverse input (ODI) method that draws an adversarial image on a 3D object and induces the rendered image to be classified as the target class. Our motivation comes from the humans' superior perception of an image printed on a 3D object. If the image is clear enough, humans can recognize the image content in a variety of viewing conditions. Likewise, if an adversarial example looks like the target class to the model, the model should also classify the rendered image of the 3D object as the target class. The ODI method effectively diversifies the input by leveraging an ensemble of multiple source objects and randomizing viewing conditions. In our experimental results on the ImageNet-Compatible dataset, this method boosts the average targeted attack success rate from 28.3% to 47.0% compared to the state-of-the-art methods. We also demonstrate the applicability of the ODI method to adversarial examples on the face verification task and its superior performance improvement. Our code is available at https://github.com/dreamflake/ODI.