 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffRef3D: A Diffusion-based Proposal Refinement Framework for 3D Object Detection
Oct 25, 2023Denoising diffusion models show remarkable performances in generative tasks, and their potential applications in perception tasks are gaining interest. In this paper, we introduce a novel framework named DiffRef3D which adopts the diffusion process on 3D object detection with point clouds for the first time. Specifically, we formulate the proposal refinement stage of two-stage 3D object detectors as a conditional diffusion process. During training, DiffRef3D gradually adds noise to the residuals between proposals and target objects, then applies the noisy residuals to proposals to generate hypotheses. The refinement module utilizes these hypotheses to denoise the noisy residuals and generate accurate box predictions. In the inference phase, DiffRef3D generates initial hypotheses by sampling noise from a Gaussian distribution as residuals and refines the hypotheses through iterative steps. DiffRef3D is a versatile proposal refinement framework that consistently improves the performance of existing 3D object detection models. We demonstrate the significance of DiffRef3D through extensive experiments on the KITTI benchmark. Code will be available.
PG-RCNN: Semantic Surface Point Generation for 3D Object Detection
Jul 24, 2023One of the main challenges in LiDAR-based 3D object detection is that the sensors often fail to capture the complete spatial information about the objects due to long distance and occlusion. Two-stage detectors with point cloud completion approaches tackle this problem by adding more points to the regions of interest (RoIs) with a pre-trained network. However, these methods generate dense point clouds of objects for all region proposals, assuming that objects always exist in the RoIs. This leads to the indiscriminate point generation for incorrect proposals as well. Motivated by this, we propose Point Generation R-CNN (PG-RCNN), a novel end-to-end detector that generates semantic surface points of foreground objects for accurate detection. Our method uses a jointly trained RoI point generation module to process the contextual information of RoIs and estimate the complete shape and displacement of foreground objects. For every generated point, PG-RCNN assigns a semantic feature that indicates the estimated foreground probability. Extensive experiments show that the point clouds generated by our method provide geometrically and semantically rich information for refining false positive and misaligned proposals. PG-RCNN achieves competitive performance on the KITTI benchmark, with significantly fewer parameters than state-of-the-art models. The code is available at https://github.com/quotation2520/PG-RCNN.
SimVODIS: Simultaneous Visual Odometry, Object Detection, and Instance Segmentation
Nov 16, 2019
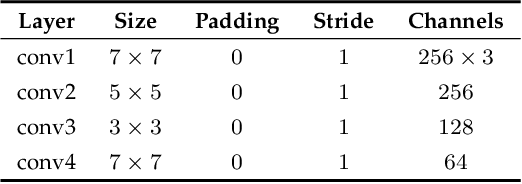


Intelligent agents need to understand the surrounding environment to provide meaningful services to or interact intelligently with humans. The agents should perceive geometric features as well as semantic entities inherent in the environment. Contemporary methods in general provide one type of information regarding the environment at a time, making it difficult to conduct high-level tasks. Moreover, running two types of methods and associating two resultant information requires a lot of computation and complicates the software architecture. To overcome these limitations, we propose a neural architecture that simultaneously performs both geometric and semantic tasks in a single thread: simultaneous visual odometry, object detection, and instance segmentation (SimVODIS). Training SimVODIS requires unlabeled video sequences and the photometric consistency between input image frames generates self-supervision signals. The performance of SimVODIS outperforms or matches the state-of-the-art performance in pose estimation, depth map prediction, object detection, and instance segmentation tasks while completing all the tasks in a single thread. We expect SimVODIS would enhance the autonomy of intelligent agents and let the agents provide effective services to humans.