 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVSCD: Video-based Scene Change Detection in Unaligned Scenes
May 20, 2026Detecting what has changed in an environment is essential for long-term autonomy, yet most change detection settings assume fixed viewpoints, mild misalignment, or only a few changed objects. We introduce Video-based Scene Change Detection (VSCD), which predicts a pixel-wise change mask for each query frame, given a reference and a query RGB video of the same indoor space recorded at different times under unconstrained camera motion. The two videos are not temporally synchronized, and many object instances may appear or disappear. To study this setting, we build a large-scale benchmark with over 1.1 million frames annotated with pixel-accurate change masks, together with a real-world test set for evaluating transfer beyond simulation. We propose a query-centric multi-reference model that learns temporal matching implicitly from change-mask supervision, aligns candidate reference features to the query via local patch correspondence, and fuses per-candidate change features using frame-level and patch-level confidence before decoding a high-resolution mask once per frame. Our approach achieves state-of-the-art performance against strong image- and video-based baselines, and we validate its real-world impact by deploying it on a mobile robot for two downstream applications -- visual surveillance and object incremental learning.
TERDNet: Transformer Encoder-Recurrent Decoder Network for Scene Change Detection
May 20, 2026In this work, we address the challenge of Scene Change Detection (SCD), where the goal is to identify variations between two images of the same location captured at different times. Existing SCD models often overlook the varying importance of features across layers, employ single-step decoders that confine refinement, and provide limited insight into encoder pretraining strategies. We propose TERDNet, a Transformer Encoder-Recurrent Decoder Network designed to overcome these limitations. TERDNet consists of a transformer-based encoder that extracts multi-level representations, a feature fusion module that integrates correlation volumes with these features, a recurrent 3-gate-GRU decoder that performs iterative refinement, and a combined convolution-interpolation upsampler that restores fine-grained resolution. Extensive experiments on four public benchmarks show that TERDNet consistently outperforms prior approaches and produces more accurate and detailed change masks. Ablation studies confirm the benefit of segmentation-based pretraining and the effectiveness of our fusion design. In addition, robustness tests under viewpoint misalignment confirm TERDNet's potential for deployment in real-world robotic systems, where reliable perception is critical. Our code is available at https://github.com/AutoCompSysLab/TERDNet.
Context-Nav: Context-Driven Exploration and Viewpoint-Aware 3D Spatial Reasoning for Instance Navigation
Mar 11, 2026Text-goal instance navigation (TGIN) asks an agent to resolve a single, free-form description into actions that reach the correct object instance among same-category distractors. We present \textit{Context-Nav} that elevates long, contextual captions from a local matching cue to a global exploration prior and verifies candidates through 3D spatial reasoning. First, we compute dense text-image alignments for a value map that ranks frontiers -- guiding exploration toward regions consistent with the entire description rather than early detections. Second, upon observing a candidate, we perform a viewpoint-aware relation check: the agent samples plausible observer poses, aligns local frames, and accepts a target only if the spatial relations can be satisfied from at least one viewpoint. The pipeline requires no task-specific training or fine-tuning; we attain state-of-the-art performance on InstanceNav and CoIN-Bench. Ablations show that (i) encoding full captions into the value map avoids wasted motion and (ii) explicit, viewpoint-aware 3D verification prevents semantically plausible but incorrect stops. This suggests that geometry-grounded spatial reasoning is a scalable alternative to heavy policy training or human-in-the-loop interaction for fine-grained instance disambiguation in cluttered 3D scenes.
MA3DSG: Multi-Agent 3D Scene Graph Generation for Large-Scale Indoor Environments
Feb 04, 2026Current 3D scene graph generation (3DSGG) approaches heavily rely on a single-agent assumption and small-scale environments, exhibiting limited scalability to real-world scenarios. In this work, we introduce Multi-Agent 3D Scene Graph Generation (MA3DSG) model, the first framework designed to tackle this scalability challenge using multiple agents. We develop a training-free graph alignment algorithm that efficiently merges partial query graphs from individual agents into a unified global scene graph. Leveraging extensive analysis and empirical insights, our approach enables conventional single-agent systems to operate collaboratively without requiring any learnable parameters. To rigorously evaluate 3DSGG performance, we propose MA3DSG-Bench-a benchmark that supports diverse agent configurations, domain sizes, and environmental conditions-providing a more general and extensible evaluation framework. This work lays a solid foundation for scalable, multi-agent 3DSGG research.
Self-supervised 3D Object Detection from Monocular Pseudo-LiDAR
Sep 20, 2022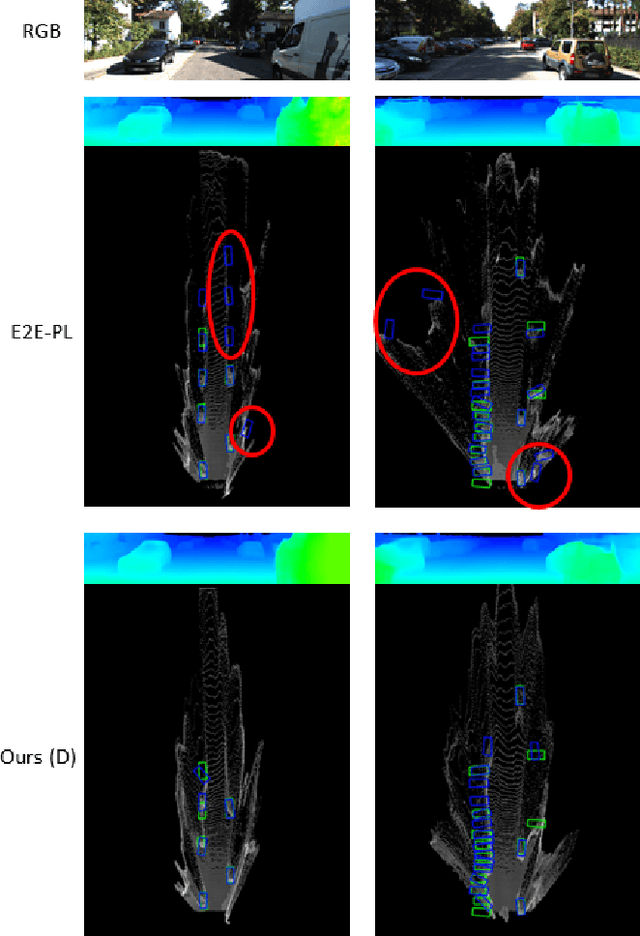


There have been attempts to detect 3D objects by fusion of stereo camera images and LiDAR sensor data or using LiDAR for pre-training and only monocular images for testing, but there have been less attempts to use only monocular image sequences due to low accuracy. In addition, when depth prediction using only monocular images, only scale-inconsistent depth can be predicted, which is the reason why researchers are reluctant to use monocular images alone. Therefore, we propose a method for predicting absolute depth and detecting 3D objects using only monocular image sequences by enabling end-to-end learning of detection networks and depth prediction networks. As a result, the proposed method surpasses other existing methods in performance on the KITTI 3D dataset. Even when monocular image and 3D LiDAR are used together during training in an attempt to improve performance, ours exhibit is the best performance compared to other methods using the same input. In addition, end-to-end learning not only improves depth prediction performance, but also enables absolute depth prediction, because our network utilizes the fact that the size of a 3D object such as a car is determined by the approximate size.
A Dual-Cycled Cross-View Transformer Network for Unified Road Layout Estimation and 3D Object Detection in the Bird's-Eye-View
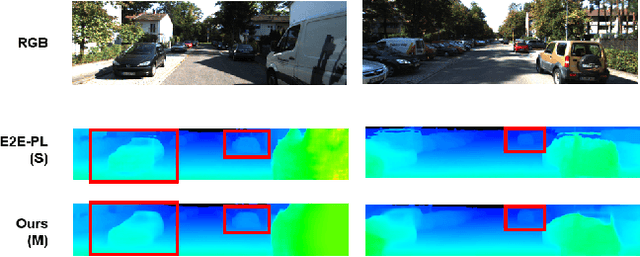
Sep 19, 2022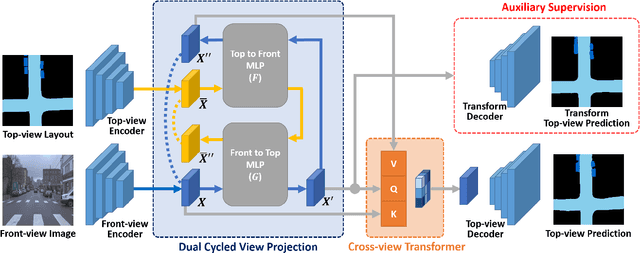


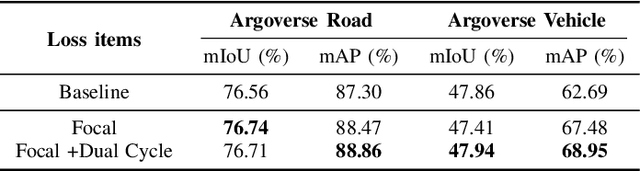
The bird's-eye-view (BEV) representation allows robust learning of multiple tasks for autonomous driving including road layout estimation and 3D object detection. However, contemporary methods for unified road layout estimation and 3D object detection rarely handle the class imbalance of the training dataset and multi-class learning to reduce the total number of networks required. To overcome these limitations, we propose a unified model for road layout estimation and 3D object detection inspired by the transformer architecture and the CycleGAN learning framework. The proposed model deals with the performance degradation due to the class imbalance of the dataset utilizing the focal loss and the proposed dual cycle loss. Moreover, we set up extensive learning scenarios to study the effect of multi-class learning for road layout estimation in various situations. To verify the effectiveness of the proposed model and the learning scheme, we conduct a thorough ablation study and a comparative study. The experiment results attest the effectiveness of our model; we achieve state-of-the-art performance in both the road layout estimation and 3D object detection tasks.
Writing in The Air: Unconstrained Text Recognition from Finger Movement Using Spatio-Temporal Convolution
Apr 19, 2021
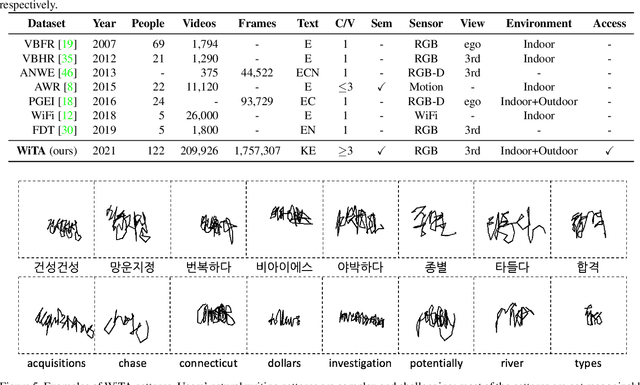

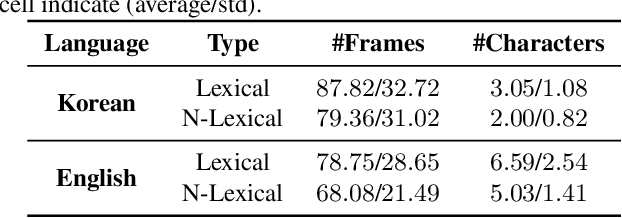
In this paper, we introduce a new benchmark dataset for the challenging writing in the air (WiTA) task -- an elaborate task bridging vision and NLP. WiTA implements an intuitive and natural writing method with finger movement for human-computer interaction (HCI). Our WiTA dataset will facilitate the development of data-driven WiTA systems which thus far have displayed unsatisfactory performance -- due to lack of dataset as well as traditional statistical models they have adopted. Our dataset consists of five sub-datasets in two languages (Korean and English) and amounts to 209,926 video instances from 122 participants. We capture finger movement for WiTA with RGB cameras to ensure wide accessibility and cost-efficiency. Next, we propose spatio-temporal residual network architectures inspired by 3D ResNet. These models perform unconstrained text recognition from finger movement, guarantee a real-time operation by processing 435 and 697 decoding frames-per-second for Korean and English, respectively, and will serve as an evaluation standard. Our dataset and the source codes are available at https://github.com/Uehwan/WiTA.
Revisiting Self-Supervised Monocular Depth Estimation
Mar 23, 2021
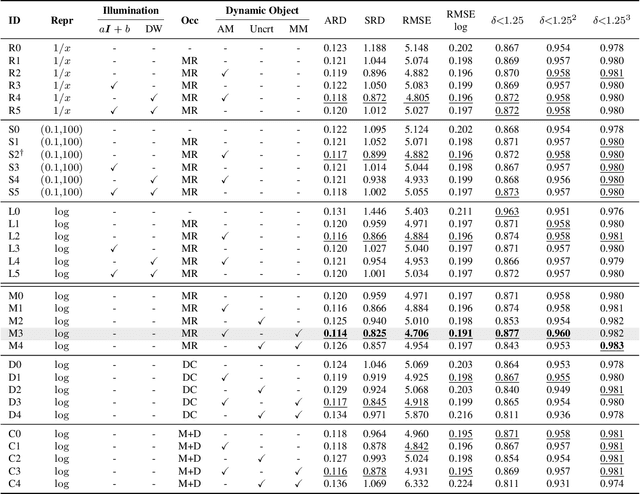


Self-supervised learning of depth map prediction and motion estimation from monocular video sequences is of vital importance -- since it realizes a broad range of tasks in robotics and autonomous vehicles. A large number of research efforts have enhanced the performance by tackling illumination variation, occlusions, and dynamic objects, to name a few. However, each of those efforts targets individual goals and endures as separate works. Moreover, most of previous works have adopted the same CNN architecture, not reaping architectural benefits. Therefore, the need to investigate the inter-dependency of the previous methods and the effect of architectural factors remains. To achieve these objectives, we revisit numerous previously proposed self-supervised methods for joint learning of depth and motion, perform a comprehensive empirical study, and unveil multiple crucial insights. Furthermore, we remarkably enhance the performance as a result of our study -- outperforming previous state-of-the-art performance.
ChangeSim: Towards End-to-End Online Scene Change Detection in Industrial Indoor Environments
Mar 09, 2021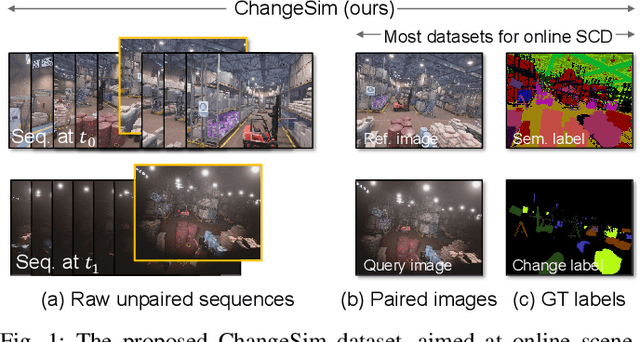

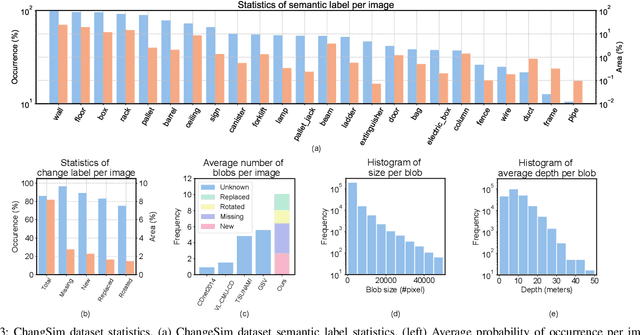

We present a challenging dataset, ChangeSim, aimed at online scene change detection (SCD) and more. The data is collected in photo-realistic simulation environments with the presence of environmental non-targeted variations, such as air turbidity and light condition changes, as well as targeted object changes in industrial indoor environments. By collecting data in simulations, multi-modal sensor data and precise ground truth labels are obtainable such as the RGB image, depth image, semantic segmentation, change segmentation, camera poses, and 3D reconstructions. While the previous online SCD datasets evaluate models given well-aligned image pairs, ChangeSim also provides raw unpaired sequences that present an opportunity to develop an online SCD model in an end-to-end manner, considering both pairing and detection. Experiments show that even the latest pair-based SCD models suffer from the bottleneck of the pairing process, and it gets worse when the environment contains the non-targeted variations. Our dataset is available at http://sammica.github.io/ChangeSim/.
A Real-time Vision Framework for Pedestrian Behavior Recognition and Intention Prediction at Intersections Using 3D Pose Estimation
Sep 23, 2020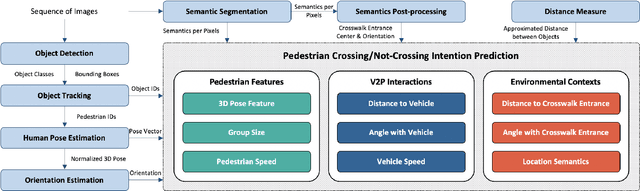
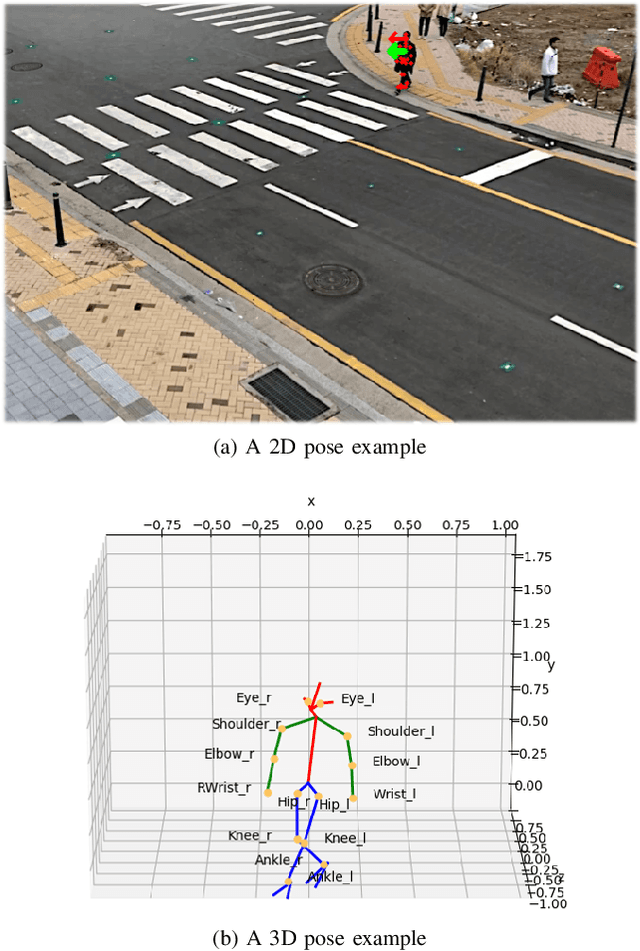
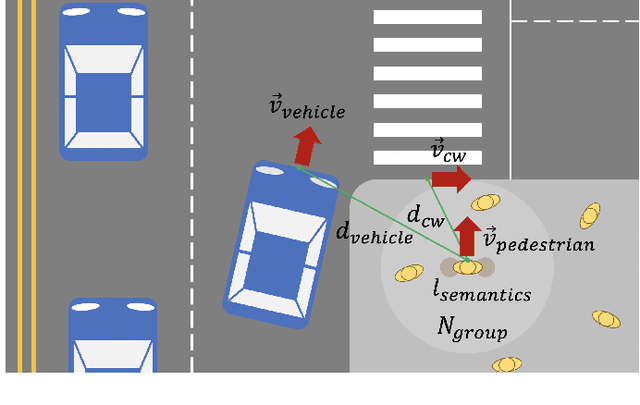

Minimizing traffic accidents between vehicles and pedestrians is one of the primary research goals in intelligent transportation systems. To achieve the goal, pedestrian behavior recognition and prediction of pedestrian's crossing or not-crossing intention play a central role. Contemporary approaches do not guarantee satisfactory performance due to lack of generalization, the requirement of manual data labeling, and high computational complexity. To overcome these limitations, we propose a real-time vision framework for two tasks: pedestrian behavior recognition (100.53 FPS) and intention prediction (35.76 FPS). Our framework obtains satisfying generalization over multiple sites because of the proposed site-independent features. At the center of the feature extraction lies 3D pose estimation. The 3D pose analysis enables robust and accurate recognition of pedestrian behaviors and prediction of intentions over multiple sites. The proposed vision framework realizes 89.3% accuracy in the behavior recognition task on the TUD dataset without any training process and 91.28% accuracy in intention prediction on our dataset achieving new state-of-the-art performance. To contribute to the corresponding research community, we make our source codes public which are available at https://github.com/Uehwan/VisionForPedestrian