 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRIFT open dataset: A drone-derived intelligence for traffic analysis in urban environmen
Apr 15, 2025Reliable traffic data are essential for understanding urban mobility and developing effective traffic management strategies. This study introduces the DRone-derived Intelligence For Traffic analysis (DRIFT) dataset, a large-scale urban traffic dataset collected systematically from synchronized drone videos at approximately 250 meters altitude, covering nine interconnected intersections in Daejeon, South Korea. DRIFT provides high-resolution vehicle trajectories that include directional information, processed through video synchronization and orthomap alignment, resulting in a comprehensive dataset of 81,699 vehicle trajectories. Through our DRIFT dataset, researchers can simultaneously analyze traffic at multiple scales - from individual vehicle maneuvers like lane-changes and safety metrics such as time-to-collision to aggregate network flow dynamics across interconnected urban intersections. The DRIFT dataset is structured to enable immediate use without additional preprocessing, complemented by open-source models for object detection and trajectory extraction, as well as associated analytical tools. DRIFT is expected to significantly contribute to academic research and practical applications, such as traffic flow analysis and simulation studies. The dataset and related resources are publicly accessible at https://github.com/AIxMobility/The-DRIFT.
Advanced computer vision for extracting georeferenced vehicle trajectories from drone imagery
Nov 04, 2024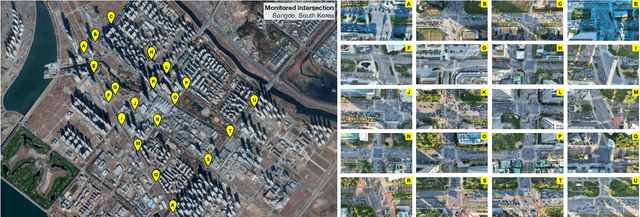

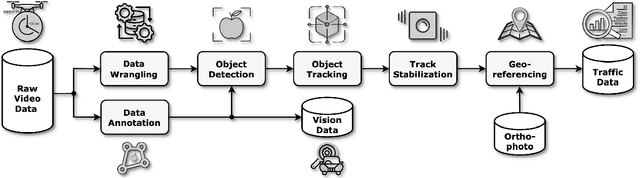
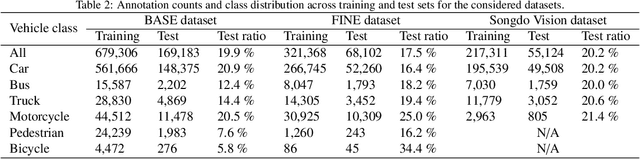
This paper presents a framework for extracting georeferenced vehicle trajectories from high-altitude drone footage, addressing key challenges in urban traffic monitoring and limitations of traditional ground-based systems. We employ state-of-the-art computer vision and deep learning to create an end-to-end pipeline that enhances vehicle detection, tracking, and trajectory stabilization. Conducted in the Songdo International Business District, South Korea, the study used a multi-drone experiment over 20 intersections, capturing approximately 12TB of 4K video data over four days. We developed a novel track stabilization method that uses detected vehicle bounding boxes as exclusion masks during image registration, which, combined with advanced georeferencing techniques, accurately transforms vehicle coordinates into real-world geographical data. Additionally, our framework includes robust vehicle dimension estimation and detailed road segmentation for in-depth traffic analysis. The framework produced two high-quality datasets: the Songdo Traffic dataset, comprising nearly 1 million unique vehicle trajectories, and the Songdo Vision dataset, containing over 5,000 human-annotated frames with about 300,000 vehicle instances in four classes. Comparisons between drone-derived data and high-precision sensor data from an instrumented probe vehicle highlight the accuracy and consistency of our framework's extraction in dense urban settings. By publicly releasing these datasets and the pipeline source code, this work sets new benchmarks for data quality, reproducibility, and scalability in traffic research. Results demonstrate the potential of integrating drone technology with advanced computer vision for precise, cost-effective urban traffic monitoring, providing valuable resources for the research community to develop intelligent transportation systems and improve traffic management strategies.
A Real-time Evaluation Framework for Pedestrian's Potential Risk at Non-Signalized Intersections Based on Predicted Post-Encroachment Time
Apr 24, 2024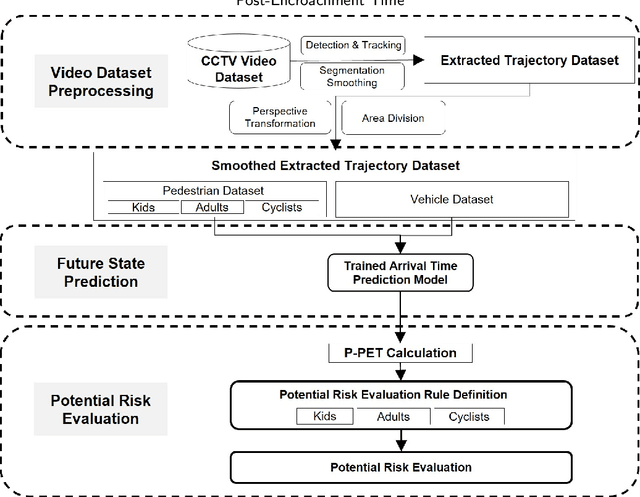



Addressing pedestrian safety at intersections is one of the paramount concerns in the field of transportation research, driven by the urgency of reducing traffic-related injuries and fatalities. With advances in computer vision technologies and predictive models, the pursuit of developing real-time proactive protection systems is increasingly recognized as vital to improving pedestrian safety at intersections. The core of these protection systems lies in the prediction-based evaluation of pedestrian's potential risks, which plays a significant role in preventing the occurrence of accidents. The major challenges in the current prediction-based potential risk evaluation research can be summarized into three aspects: the inadequate progress in creating a real-time framework for the evaluation of pedestrian's potential risks, the absence of accurate and explainable safety indicators that can represent the potential risk, and the lack of tailor-made evaluation criteria specifically for each category of pedestrians. To address these research challenges, in this study, a framework with computer vision technologies and predictive models is developed to evaluate the potential risk of pedestrians in real time. Integral to this framework is a novel surrogate safety measure, the Predicted Post-Encroachment Time (P-PET), derived from deep learning models capable to predict the arrival time of pedestrians and vehicles at intersections. To further improve the effectiveness and reliability of pedestrian risk evaluation, we classify pedestrians into distinct categories and apply specific evaluation criteria for each group. The results demonstrate the framework's ability to effectively identify potential risks through the use of P-PET, indicating its feasibility for real-time applications and its improved performance in risk evaluation across different categories of pedestrians.
A Framework for Pedestrian Sub-classification and Arrival Time Prediction at Signalized Intersection Using Preprocessed Lidar Data
Jan 15, 2022The mortality rate for pedestrians using wheelchairs was 36% higher than the overall population pedestrian mortality rate. However, there is no data to clarify the pedestrians' categories in both fatal and nonfatal accidents, since police reports often do not keep a record of whether a victim was using a wheelchair or has a disability. Currently, real-time detection of vulnerable road users using advanced traffic sensors installed at the infrastructure side has a great potential to significantly improve traffic safety at the intersection. In this research, we develop a systematic framework with a combination of machine learning and deep learning models to distinguish disabled people from normal walk pedestrians and predict the time needed to reach the next side of the intersection. The proposed framework shows high performance both at vulnerable user classification and arrival time prediction accuracy.
Transformer-based Map Matching Model with Limited Ground-Truth Data using Transfer-Learning Approach
Aug 03, 2021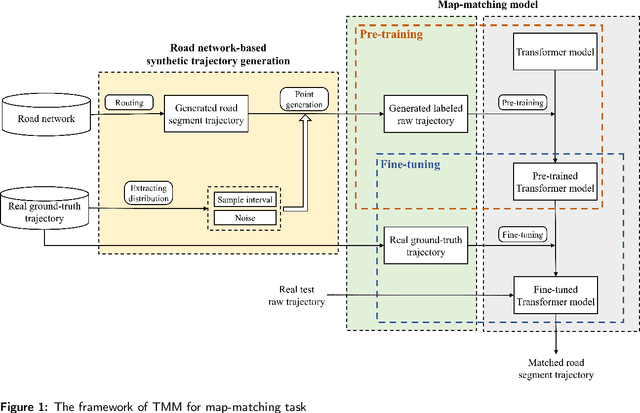
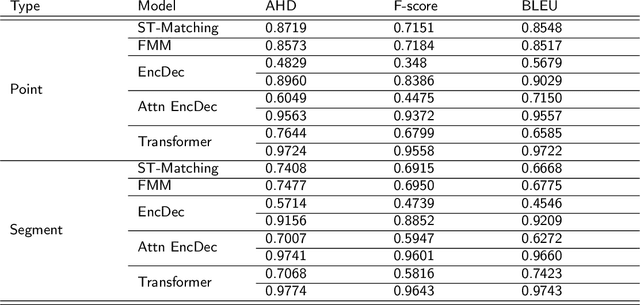
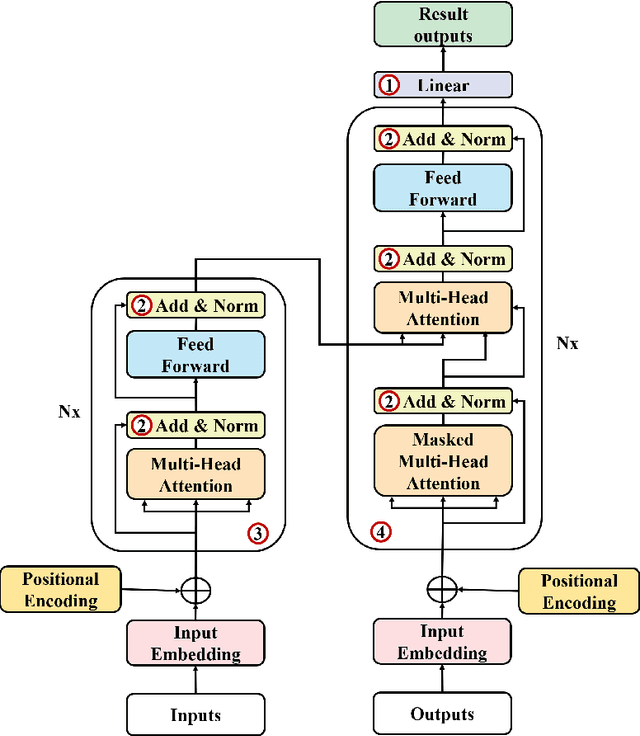
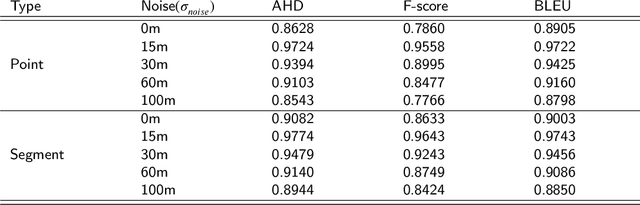
In many trajectory-based applications, it is necessary to map raw GPS trajectories onto road networks in digital maps, which is commonly referred to as a map-matching process. While most previous map-matching methods have focused on using rule-based algorithms to deal with the map-matching problems, in this paper, we consider the map-matching task from the data perspective, proposing a deep learning-based map-matching model. We build a Transformer-based map-matching model with a transfer learning approach. We generate synthetic trajectory data to pre-train the Transformer model and then fine-tune the model with a limited number of ground-truth data to minimize the model development cost and reduce the real-to-virtual gap. Three metrics (Average Hamming Distance, F-score, and BLEU) at two levels (point and segment level) are used to evaluate the model performance. The results indicate that the proposed model outperforms existing models. Furthermore, we use the attention weights of the Transformer to plot the map-matching process and find how the model matches the road segments correctly.
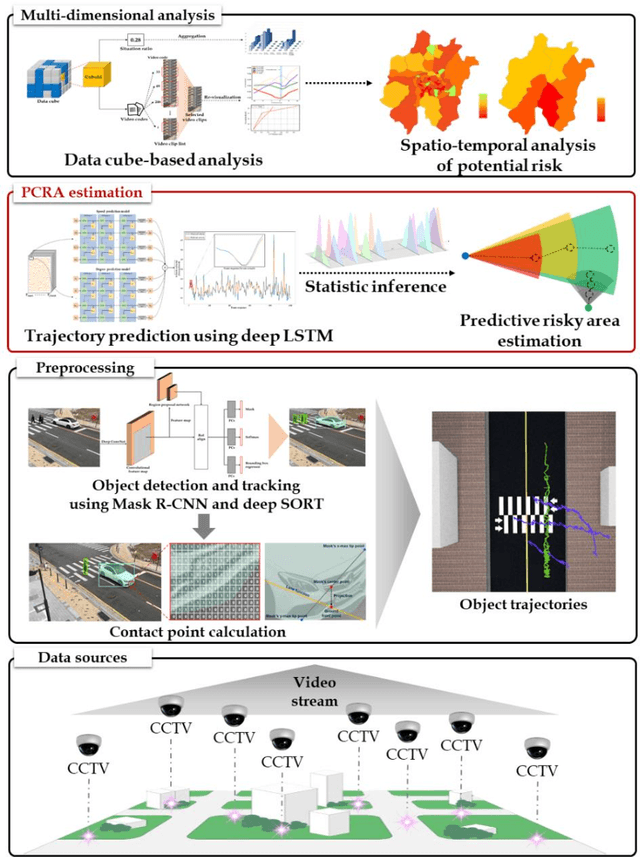
Analyzing vehicle pedestrian interactions combining data cube structure and predictive collision risk estimation model
Jul 26, 2021
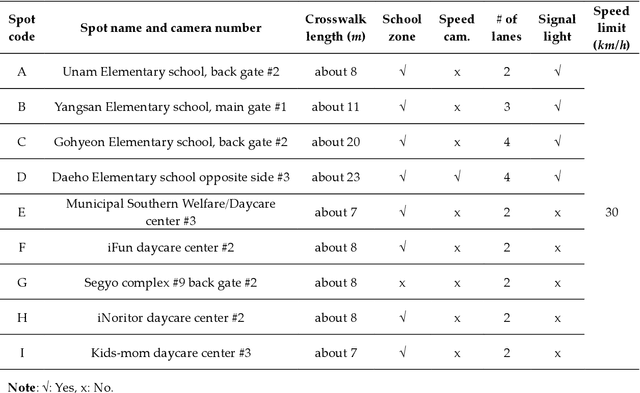
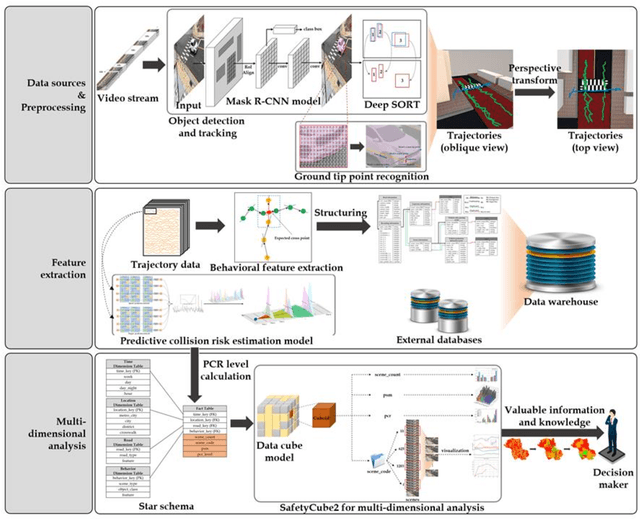
Traffic accidents are a threat to human lives, particularly pedestrians causing premature deaths. Therefore, it is necessary to devise systems to prevent accidents in advance and respond proactively, using potential risky situations as one of the surrogate safety measurements. This study introduces a new concept of a pedestrian safety system that combines the field and the centralized processes. The system can warn of upcoming risks immediately in the field and improve the safety of risk frequent areas by assessing the safety levels of roads without actual collisions. In particular, this study focuses on the latter by introducing a new analytical framework for a crosswalk safety assessment with behaviors of vehicle/pedestrian and environmental features. We obtain these behavioral features from actual traffic video footage in the city with complete automatic processing. The proposed framework mainly analyzes these behaviors in multidimensional perspectives by constructing a data cube structure, which combines the LSTM based predictive collision risk estimation model and the on line analytical processing operations. From the PCR estimation model, we categorize the severity of risks as four levels and apply the proposed framework to assess the crosswalk safety with behavioral features. Our analytic experiments are based on two scenarios, and the various descriptive results are harvested the movement patterns of vehicles and pedestrians by road environment and the relationships between risk levels and car speeds. Thus, the proposed framework can support decision makers by providing valuable information to improve pedestrian safety for future accidents, and it can help us better understand their behaviors near crosswalks proactively. In order to confirm the feasibility and applicability of the proposed framework, we implement and apply it to actual operating CCTVs in Osan City, Korea.
Automated Object Behavioral Feature Extraction for Potential Risk Analysis based on Video Sensor
Jul 08, 2021
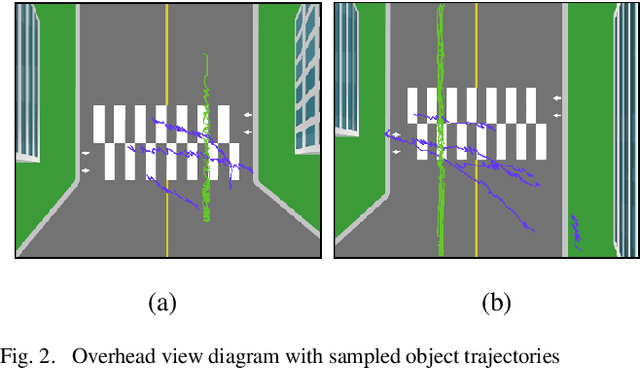
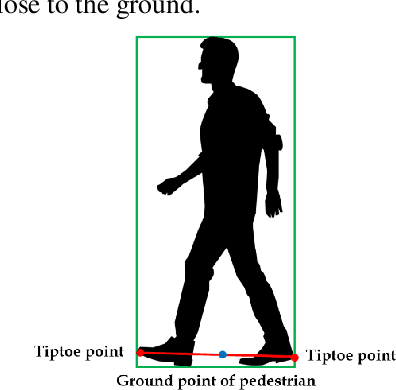
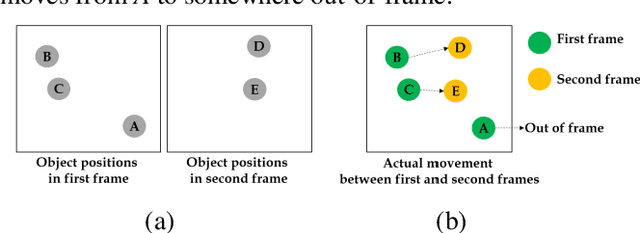
Pedestrians are exposed to risk of death or serious injuries on roads, especially unsignalized crosswalks, for a variety of reasons. To date, an extensive variety of studies have reported on vision based traffic safety system. However, many studies required manual inspection of the volumes of traffic video to reliably obtain traffic related objects behavioral factors. In this paper, we propose an automated and simpler system for effectively extracting object behavioral features from video sensors deployed on the road. We conduct basic statistical analysis on these features, and show how they can be useful for monitoring the traffic behavior on the road. We confirm the feasibility of the proposed system by applying our prototype to two unsignalized crosswalks in Osan city, South Korea. To conclude, we compare behaviors of vehicles and pedestrians in those two areas by simple statistical analysis. This study demonstrates the potential for a network of connected video sensors to provide actionable data for smart cities to improve pedestrian safety in dangerous road environments.
Vision based Pedestrian Potential Risk Analysis based on Automated Behavior Feature Extraction for Smart and Safe City
May 27, 2021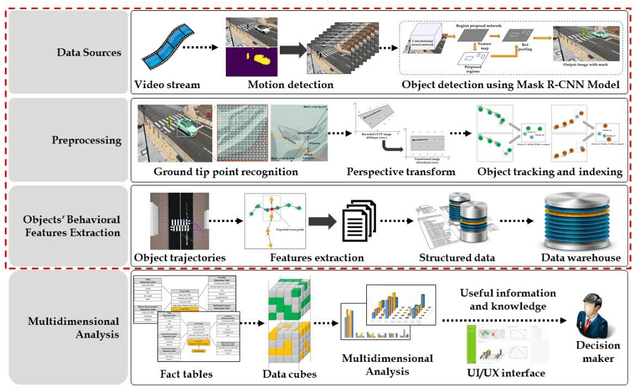

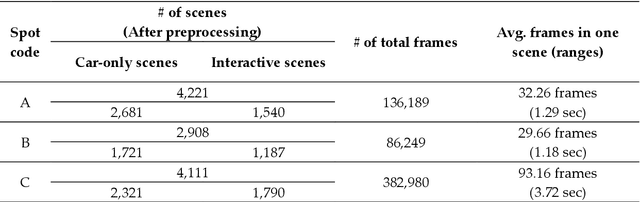
Despite recent advances in vehicle safety technologies, road traffic accidents still pose a severe threat to human lives and have become a leading cause of premature deaths. In particular, crosswalks present a major threat to pedestrians, but we lack dense behavioral data to investigate the risks they face. Therefore, we propose a comprehensive analytical model for pedestrian potential risk using video footage gathered by road security cameras deployed at such crossings. The proposed system automatically detects vehicles and pedestrians, calculates trajectories by frames, and extracts behavioral features affecting the likelihood of potentially dangerous scenes between these objects. Finally, we design a data cube model by using the large amount of the extracted features accumulated in a data warehouse to perform multidimensional analysis for potential risk scenes with levels of abstraction, but this is beyond the scope of this paper, and will be detailed in a future study. In our experiment, we focused on extracting the various behavioral features from multiple crosswalks, and visualizing and interpreting their behaviors and relationships among them by camera location to show how they may or may not contribute to potential risk. We validated feasibility and applicability by applying it in multiple crosswalks in Osan city, Korea.
A novel method of predictive collision risk area estimation for proactive pedestrian accident prevention system in urban surveillance infrastructure
May 06, 2021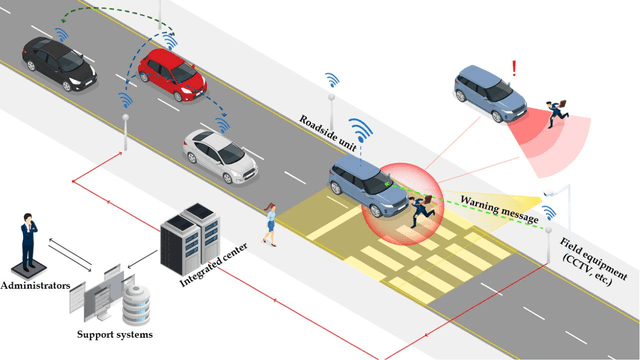


Road traffic accidents, especially vehicle pedestrian collisions in crosswalk, globally pose a severe threat to human lives and have become a leading cause of premature deaths. In order to protect such vulnerable road users from collisions, it is necessary to recognize possible conflict in advance and warn to road users, not post facto. A breakthrough for proactively preventing pedestrian collisions is to recognize pedestrian's potential risks based on vision sensors such as CCTVs. In this study, we propose a predictive collision risk area estimation system at unsignalized crosswalks. The proposed system applied trajectories of vehicles and pedestrians from video footage after preprocessing, and then predicted their trajectories by using deep LSTM networks. With use of predicted trajectories, this system can infer collision risk areas statistically, further severity of levels is divided as danger, warning, and relative safe. In order to validate the feasibility and applicability of the proposed system, we applied it and assess the severity of potential risks in two unsignalized spots in Osan city, Korea.
A Real-time Vision Framework for Pedestrian Behavior Recognition and Intention Prediction at Intersections Using 3D Pose Estimation
Sep 23, 2020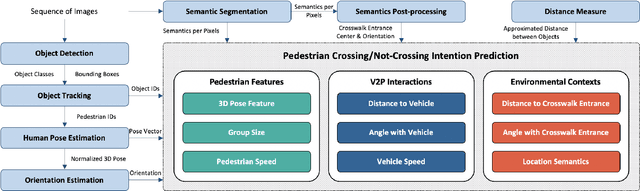
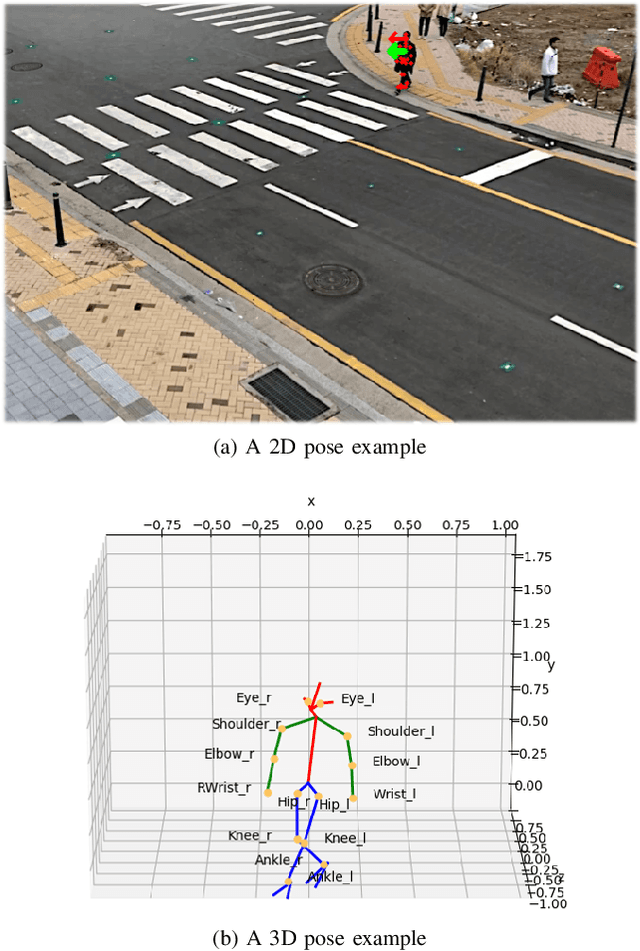

Minimizing traffic accidents between vehicles and pedestrians is one of the primary research goals in intelligent transportation systems. To achieve the goal, pedestrian behavior recognition and prediction of pedestrian's crossing or not-crossing intention play a central role. Contemporary approaches do not guarantee satisfactory performance due to lack of generalization, the requirement of manual data labeling, and high computational complexity. To overcome these limitations, we propose a real-time vision framework for two tasks: pedestrian behavior recognition (100.53 FPS) and intention prediction (35.76 FPS). Our framework obtains satisfying generalization over multiple sites because of the proposed site-independent features. At the center of the feature extraction lies 3D pose estimation. The 3D pose analysis enables robust and accurate recognition of pedestrian behaviors and prediction of intentions over multiple sites. The proposed vision framework realizes 89.3% accuracy in the behavior recognition task on the TUD dataset without any training process and 91.28% accuracy in intention prediction on our dataset achieving new state-of-the-art performance. To contribute to the corresponding research community, we make our source codes public which are available at https://github.com/Uehwan/VisionForPedestrian