 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVOID: The Adverse Visual Conditions Dataset with Obstacles for Driving Scene Understanding
Dec 29, 2025Understanding road scenes for visual perception remains crucial for intelligent self-driving cars. In particular, it is desirable to detect unexpected small road hazards reliably in real-time, especially under varying adverse conditions (e.g., weather and daylight). However, existing road driving datasets provide large-scale images acquired in either normal or adverse scenarios only, and often do not contain the road obstacles captured in the same visual domain as for the other classes. To address this, we introduce a new dataset called AVOID, the Adverse Visual Conditions Dataset, for real-time obstacle detection collected in a simulated environment. AVOID consists of a large set of unexpected road obstacles located along each path captured under various weather and time conditions. Each image is coupled with the corresponding semantic and depth maps, raw and semantic LiDAR data, and waypoints, thereby supporting most visual perception tasks. We benchmark the results on high-performing real-time networks for the obstacle detection task, and also propose and conduct ablation studies using a comprehensive multi-task network for semantic segmentation, depth and waypoint prediction tasks.
Synthetic Data Generation for Phrase Break Prediction with Large Language Model
Jul 24, 2025Current approaches to phrase break prediction address crucial prosodic aspects of text-to-speech systems but heavily rely on vast human annotations from audio or text, incurring significant manual effort and cost. Inherent variability in the speech domain, driven by phonetic factors, further complicates acquiring consistent, high-quality data. Recently, large language models (LLMs) have shown success in addressing data challenges in NLP by generating tailored synthetic data while reducing manual annotation needs. Motivated by this, we explore leveraging LLM to generate synthetic phrase break annotations, addressing the challenges of both manual annotation and speech-related tasks by comparing with traditional annotations and assessing effectiveness across multiple languages. Our findings suggest that LLM-based synthetic data generation effectively mitigates data challenges in phrase break prediction and highlights the potential of LLMs as a viable solution for the speech domain.
A Two-Step Approach for Data-Efficient French Pronunciation Learning
Oct 08, 2024

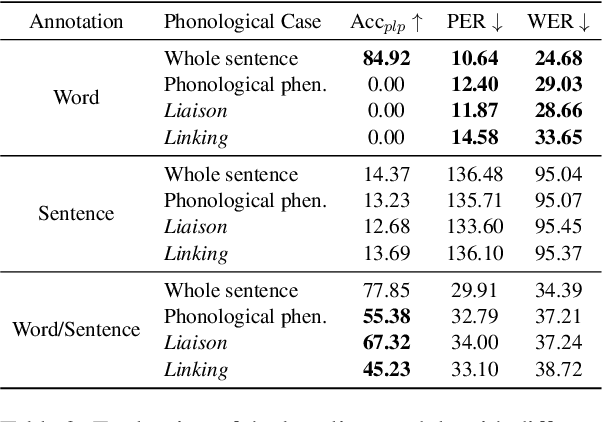

Recent studies have addressed intricate phonological phenomena in French, relying on either extensive linguistic knowledge or a significant amount of sentence-level pronunciation data. However, creating such resources is expensive and non-trivial. To this end, we propose a novel two-step approach that encompasses two pronunciation tasks: grapheme-to-phoneme and post-lexical processing. We then investigate the efficacy of the proposed approach with a notably limited amount of sentence-level pronunciation data. Our findings demonstrate that the proposed two-step approach effectively mitigates the lack of extensive labeled data, and serves as a feasible solution for addressing French phonological phenomena even under resource-constrained environments.
Image-Object-Specific Prompt Learning for Few-Shot Class-Incremental Learning
Sep 06, 2023



While many FSCIL studies have been undertaken, achieving satisfactory performance, especially during incremental sessions, has remained challenging. One prominent challenge is that the encoder, trained with an ample base session training set, often underperforms in incremental sessions. In this study, we introduce a novel training framework for FSCIL, capitalizing on the generalizability of the Contrastive Language-Image Pre-training (CLIP) model to unseen classes. We achieve this by formulating image-object-specific (IOS) classifiers for the input images. Here, an IOS classifier refers to one that targets specific attributes (like wings or wheels) of class objects rather than the image's background. To create these IOS classifiers, we encode a bias prompt into the classifiers using our specially designed module, which harnesses key-prompt pairs to pinpoint the IOS features of classes in each session. From an FSCIL standpoint, our framework is structured to retain previous knowledge and swiftly adapt to new sessions without forgetting or overfitting. This considers the updatability of modules in each session and some tricks empirically found for fast convergence. Our approach consistently demonstrates superior performance compared to state-of-the-art methods across the miniImageNet, CIFAR100, and CUB200 datasets. Further, we provide additional experiments to validate our learned model's ability to achieve IOS classifiers. We also conduct ablation studies to analyze the impact of each module within the architecture.
Semantics-guided Transformer-based Sensor Fusion for Improved Waypoint Prediction
Aug 04, 2023Sensor fusion approaches for intelligent self-driving agents remain key to driving scene understanding given visual global contexts acquired from input sensors. Specifically, for the local waypoint prediction task, single-modality networks are still limited by strong dependency on the sensitivity of the input sensor, and thus recent works promote the use of multiple sensors in fusion in feature level. While it is well known that multiple data modalities promote mutual contextual exchange, deployment to practical driving scenarios requires global 3D scene understanding in real-time with minimal computations, thus placing greater significance on training strategies given a limited number of practically usable sensors. In this light, we exploit carefully selected auxiliary tasks that are highly correlated with the target task of interest (e.g., traffic light recognition and semantic segmentation) by fusing auxiliary task features and also using auxiliary heads for waypoint prediction based on imitation learning. Our multi-task feature fusion augments and improves the base network, TransFuser, by significant margins for safer and more complete road navigation in CARLA simulator as validated on the Town05 Benchmark through extensive experiments.
Cross-Lingual Transfer Learning for Phrase Break Prediction with Multilingual Language Model
Jun 05, 2023



Phrase break prediction is a crucial task for improving the prosody naturalness of a text-to-speech (TTS) system. However, most proposed phrase break prediction models are monolingual, trained exclusively on a large amount of labeled data. In this paper, we address this issue for low-resource languages with limited labeled data using cross-lingual transfer. We investigate the effectiveness of zero-shot and few-shot cross-lingual transfer for phrase break prediction using a pre-trained multilingual language model. We use manually collected datasets in four Indo-European languages: one high-resource language and three with limited resources. Our findings demonstrate that cross-lingual transfer learning can be a particularly effective approach, especially in the few-shot setting, for improving performance in low-resource languages. This suggests that cross-lingual transfer can be inexpensive and effective for developing TTS front-end in resource-poor languages.
Balanced Supervised Contrastive Learning for Few-Shot Class-Incremental Learning
May 26, 2023



Few-shot class-incremental learning (FSCIL) presents the primary challenge of balancing underfitting to a new session's task and forgetting the tasks from previous sessions. To address this challenge, we develop a simple yet powerful learning scheme that integrates effective methods for each core component of the FSCIL network, including the feature extractor, base session classifiers, and incremental session classifiers. In feature extractor training, our goal is to obtain balanced generic representations that benefit both current viewable and unseen or past classes. To achieve this, we propose a balanced supervised contrastive loss that effectively balances these two objectives. In terms of classifiers, we analyze and emphasize the importance of unifying initialization methods for both the base and incremental session classifiers. Our method demonstrates outstanding ability for new task learning and preventing forgetting on CUB200, CIFAR100, and miniImagenet datasets, with significant improvements over previous state-of-the-art methods across diverse metrics. We conduct experiments to analyze the significance and rationale behind our approach and visualize the effectiveness of our representations on new tasks. Furthermore, we conduct diverse ablation studies to analyze the effects of each module.
Incremental Few-Shot Object Detection via Simple Fine-Tuning Approach
Feb 20, 2023In this paper, we explore incremental few-shot object detection (iFSD), which incrementally learns novel classes using only a few examples without revisiting base classes. Previous iFSD works achieved the desired results by applying meta-learning. However, meta-learning approaches show insufficient performance that is difficult to apply to practical problems. In this light, we propose a simple fine-tuning-based approach, the Incremental Two-stage Fine-tuning Approach (iTFA) for iFSD, which contains three steps: 1) base training using abundant base classes with the class-agnostic box regressor, 2) separation of the RoI feature extractor and classifier into the base and novel class branches for preserving base knowledge, and 3) fine-tuning the novel branch using only a few novel class examples. We evaluate our iTFA on the real-world datasets PASCAL VOC, COCO, and LVIS. iTFA achieves competitive performance in COCO and shows a 30% higher AP accuracy than meta-learning methods in the LVIS dataset. Experimental results show the effectiveness and applicability of our proposed method.
Doubly Contrastive End-to-End Semantic Segmentation for Autonomous Driving under Adverse Weather
Nov 21, 2022Road scene understanding tasks have recently become crucial for self-driving vehicles. In particular, real-time semantic segmentation is indispensable for intelligent self-driving agents to recognize roadside objects in the driving area. As prior research works have primarily sought to improve the segmentation performance with computationally heavy operations, they require far significant hardware resources for both training and deployment, and thus are not suitable for real-time applications. As such, we propose a doubly contrastive approach to improve the performance of a more practical lightweight model for self-driving, specifically under adverse weather conditions such as fog, nighttime, rain and snow. Our proposed approach exploits both image- and pixel-level contrasts in an end-to-end supervised learning scheme without requiring a memory bank for global consistency or the pretraining step used in conventional contrastive methods. We validate the effectiveness of our method using SwiftNet on the ACDC dataset, where it achieves up to 1.34%p improvement in mIoU (ResNet-18 backbone) at 66.7 FPS (2048x1024 resolution) on a single RTX 3080 Mobile GPU at inference. Furthermore, we demonstrate that replacing image-level supervision with self-supervision achieves comparable performance when pre-trained with clear weather images.
Deep Q-Network for AI Soccer
Sep 21, 2022

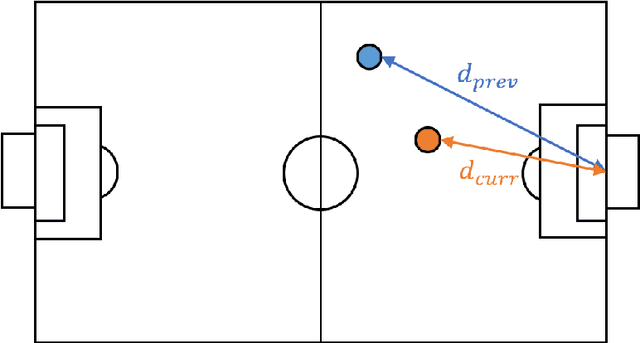

Reinforcement learning has shown an outstanding performance in the applications of games, particularly in Atari games as well as Go. Based on these successful examples, we attempt to apply one of the well-known reinforcement learning algorithms, Deep Q-Network, to the AI Soccer game. AI Soccer is a 5:5 robot soccer game where each participant develops an algorithm that controls five robots in a team to defeat the opponent participant. Deep Q-Network is designed to implement our original rewards, the state space, and the action space to train each agent so that it can take proper actions in different situations during the game. Our algorithm was able to successfully train the agents, and its performance was preliminarily proven through the mini-competition against 10 teams wishing to take part in the AI Soccer international competition. The competition was organized by the AI World Cup committee, in conjunction with the WCG 2019 Xi'an AI Masters. With our algorithm, we got the achievement of advancing to the round of 16 in this international competition with 130 teams from 39 countries.