 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative validation of surgical phase recognition, instrument keypoint estimation, and instrument instance segmentation in endoscopy: Results of the PhaKIR 2024 challenge
Jul 22, 2025Reliable recognition and localization of surgical instruments in endoscopic video recordings are foundational for a wide range of applications in computer- and robot-assisted minimally invasive surgery (RAMIS), including surgical training, skill assessment, and autonomous assistance. However, robust performance under real-world conditions remains a significant challenge. Incorporating surgical context - such as the current procedural phase - has emerged as a promising strategy to improve robustness and interpretability. To address these challenges, we organized the Surgical Procedure Phase, Keypoint, and Instrument Recognition (PhaKIR) sub-challenge as part of the Endoscopic Vision (EndoVis) challenge at MICCAI 2024. We introduced a novel, multi-center dataset comprising thirteen full-length laparoscopic cholecystectomy videos collected from three distinct medical institutions, with unified annotations for three interrelated tasks: surgical phase recognition, instrument keypoint estimation, and instrument instance segmentation. Unlike existing datasets, ours enables joint investigation of instrument localization and procedural context within the same data while supporting the integration of temporal information across entire procedures. We report results and findings in accordance with the BIAS guidelines for biomedical image analysis challenges. The PhaKIR sub-challenge advances the field by providing a unique benchmark for developing temporally aware, context-driven methods in RAMIS and offers a high-quality resource to support future research in surgical scene understanding.
RoSIS: Robust Framework for Text-Promptable Surgical Instrument Segmentation Using Vision-Language Fusion
Nov 19, 2024Surgical instrument segmentation (SIS) is an essential task in computer-assisted surgeries, with deep learning-based research improving accuracy in complex environments. Recently, text-promptable segmentation methods have been introduced to generate masks based on text prompts describing target objects. However, these methods assume that the object described by a given text prompt exists in the scene. This results in mask generation whenever a related text prompt is provided, even if the object is absent from the image. Existing methods handle this by using prompts only for objects known to be present in the image, which introduces inaccessible information in a vision-based method setting and results in unfair comparisons. For fair comparison, we redefine existing text-promptable SIS settings to robust conditions, called Robust text-promptable SIS (R-SIS), designed to forward prompts of all classes and determine the existence of an object from a given text prompt for the fair comparison. Furthermore, we propose a novel framework, Robust Surgical Instrument Segmentation (RoSIS), which combines visual and language features for promptable segmentation in the R-SIS setting. RoSIS employs an encoder-decoder architecture with a Multi-Modal Fusion Block (MMFB) and a Selective Gate Block (SGB) to achieve balanced integration of vision and language features. Additionally, we introduce an iterative inference strategy that refines segmentation masks in two steps: an initial pass using name-based prompts, followed by a refinement step using location prompts. Experiments on various datasets and settings demonstrate that RoSIS outperforms existing vision-based and promptable methods under robust conditions.
Image-Object-Specific Prompt Learning for Few-Shot Class-Incremental Learning
Sep 06, 2023



While many FSCIL studies have been undertaken, achieving satisfactory performance, especially during incremental sessions, has remained challenging. One prominent challenge is that the encoder, trained with an ample base session training set, often underperforms in incremental sessions. In this study, we introduce a novel training framework for FSCIL, capitalizing on the generalizability of the Contrastive Language-Image Pre-training (CLIP) model to unseen classes. We achieve this by formulating image-object-specific (IOS) classifiers for the input images. Here, an IOS classifier refers to one that targets specific attributes (like wings or wheels) of class objects rather than the image's background. To create these IOS classifiers, we encode a bias prompt into the classifiers using our specially designed module, which harnesses key-prompt pairs to pinpoint the IOS features of classes in each session. From an FSCIL standpoint, our framework is structured to retain previous knowledge and swiftly adapt to new sessions without forgetting or overfitting. This considers the updatability of modules in each session and some tricks empirically found for fast convergence. Our approach consistently demonstrates superior performance compared to state-of-the-art methods across the miniImageNet, CIFAR100, and CUB200 datasets. Further, we provide additional experiments to validate our learned model's ability to achieve IOS classifiers. We also conduct ablation studies to analyze the impact of each module within the architecture.
Balanced Supervised Contrastive Learning for Few-Shot Class-Incremental Learning
May 26, 2023



Few-shot class-incremental learning (FSCIL) presents the primary challenge of balancing underfitting to a new session's task and forgetting the tasks from previous sessions. To address this challenge, we develop a simple yet powerful learning scheme that integrates effective methods for each core component of the FSCIL network, including the feature extractor, base session classifiers, and incremental session classifiers. In feature extractor training, our goal is to obtain balanced generic representations that benefit both current viewable and unseen or past classes. To achieve this, we propose a balanced supervised contrastive loss that effectively balances these two objectives. In terms of classifiers, we analyze and emphasize the importance of unifying initialization methods for both the base and incremental session classifiers. Our method demonstrates outstanding ability for new task learning and preventing forgetting on CUB200, CIFAR100, and miniImagenet datasets, with significant improvements over previous state-of-the-art methods across diverse metrics. We conduct experiments to analyze the significance and rationale behind our approach and visualize the effectiveness of our representations on new tasks. Furthermore, we conduct diverse ablation studies to analyze the effects of each module.
Incremental Few-Shot Object Detection via Simple Fine-Tuning Approach
Feb 20, 2023In this paper, we explore incremental few-shot object detection (iFSD), which incrementally learns novel classes using only a few examples without revisiting base classes. Previous iFSD works achieved the desired results by applying meta-learning. However, meta-learning approaches show insufficient performance that is difficult to apply to practical problems. In this light, we propose a simple fine-tuning-based approach, the Incremental Two-stage Fine-tuning Approach (iTFA) for iFSD, which contains three steps: 1) base training using abundant base classes with the class-agnostic box regressor, 2) separation of the RoI feature extractor and classifier into the base and novel class branches for preserving base knowledge, and 3) fine-tuning the novel branch using only a few novel class examples. We evaluate our iTFA on the real-world datasets PASCAL VOC, COCO, and LVIS. iTFA achieves competitive performance in COCO and shows a 30% higher AP accuracy than meta-learning methods in the LVIS dataset. Experimental results show the effectiveness and applicability of our proposed method.
RDIS: Random Drop Imputation with Self-Training for Incomplete Time Series Data
Oct 20, 2020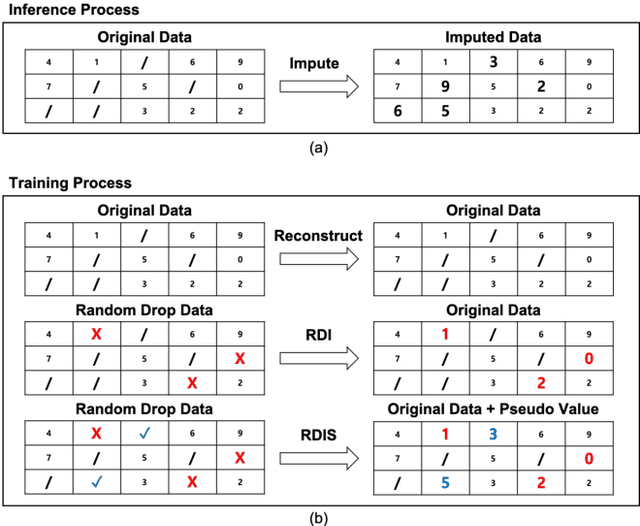
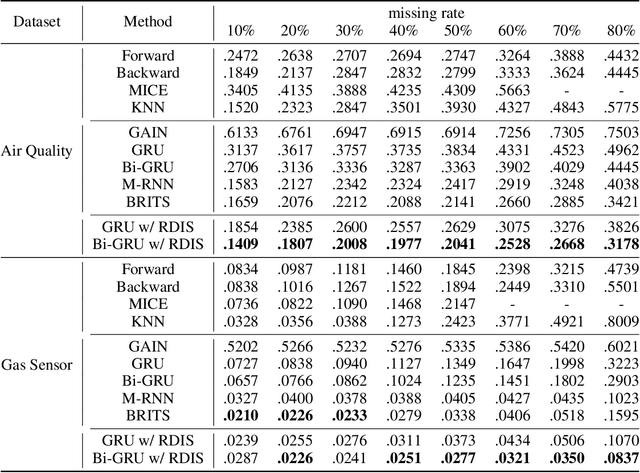
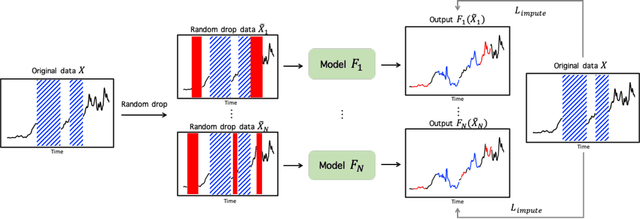

It is common that time-series data with missing values are encountered in many fields such as in finance, meteorology, and robotics. Imputation is an intrinsic method to handle such missing values. In the previous research, most of imputation networks were trained implicitly for the incomplete time series data because missing values have no ground truth. This paper proposes Random Drop Imputation with Self-training (RDIS), a novel training method for imputation networks for the incomplete time-series data. In RDIS, there are extra missing values by applying a random drop on the given incomplete data such that the imputation network can explicitly learn by imputing the random drop values. Also, self-training is introduced to exploit the original missing values without ground truth. To verify the effectiveness of our RDIS on imputation tasks, we graft RDIS to a bidirectional GRU and achieve state-of-the-art results on two real-world datasets, an air quality dataset and a gas sensor dataset with 7.9% and 5.8% margin, respectively.