 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-Object-Specific Prompt Learning for Few-Shot Class-Incremental Learning
Sep 06, 2023



While many FSCIL studies have been undertaken, achieving satisfactory performance, especially during incremental sessions, has remained challenging. One prominent challenge is that the encoder, trained with an ample base session training set, often underperforms in incremental sessions. In this study, we introduce a novel training framework for FSCIL, capitalizing on the generalizability of the Contrastive Language-Image Pre-training (CLIP) model to unseen classes. We achieve this by formulating image-object-specific (IOS) classifiers for the input images. Here, an IOS classifier refers to one that targets specific attributes (like wings or wheels) of class objects rather than the image's background. To create these IOS classifiers, we encode a bias prompt into the classifiers using our specially designed module, which harnesses key-prompt pairs to pinpoint the IOS features of classes in each session. From an FSCIL standpoint, our framework is structured to retain previous knowledge and swiftly adapt to new sessions without forgetting or overfitting. This considers the updatability of modules in each session and some tricks empirically found for fast convergence. Our approach consistently demonstrates superior performance compared to state-of-the-art methods across the miniImageNet, CIFAR100, and CUB200 datasets. Further, we provide additional experiments to validate our learned model's ability to achieve IOS classifiers. We also conduct ablation studies to analyze the impact of each module within the architecture.
Writing in The Air: Unconstrained Text Recognition from Finger Movement Using Spatio-Temporal Convolution
Apr 19, 2021
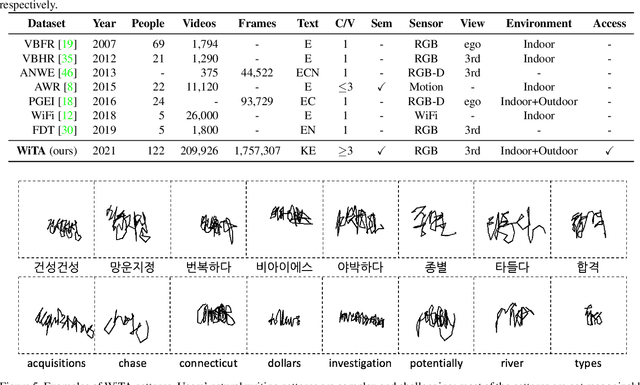

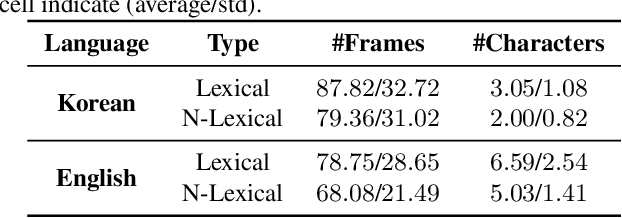
In this paper, we introduce a new benchmark dataset for the challenging writing in the air (WiTA) task -- an elaborate task bridging vision and NLP. WiTA implements an intuitive and natural writing method with finger movement for human-computer interaction (HCI). Our WiTA dataset will facilitate the development of data-driven WiTA systems which thus far have displayed unsatisfactory performance -- due to lack of dataset as well as traditional statistical models they have adopted. Our dataset consists of five sub-datasets in two languages (Korean and English) and amounts to 209,926 video instances from 122 participants. We capture finger movement for WiTA with RGB cameras to ensure wide accessibility and cost-efficiency. Next, we propose spatio-temporal residual network architectures inspired by 3D ResNet. These models perform unconstrained text recognition from finger movement, guarantee a real-time operation by processing 435 and 697 decoding frames-per-second for Korean and English, respectively, and will serve as an evaluation standard. Our dataset and the source codes are available at https://github.com/Uehwan/WiTA.
ChangeSim: Towards End-to-End Online Scene Change Detection in Industrial Indoor Environments
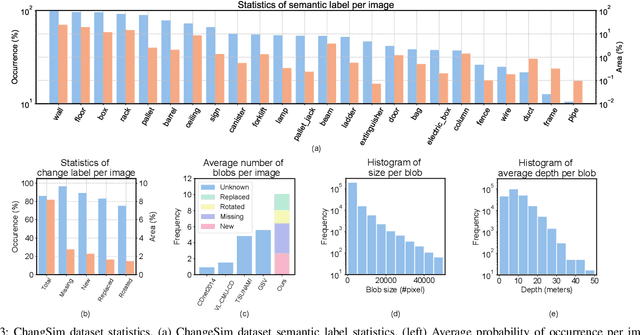
Mar 09, 2021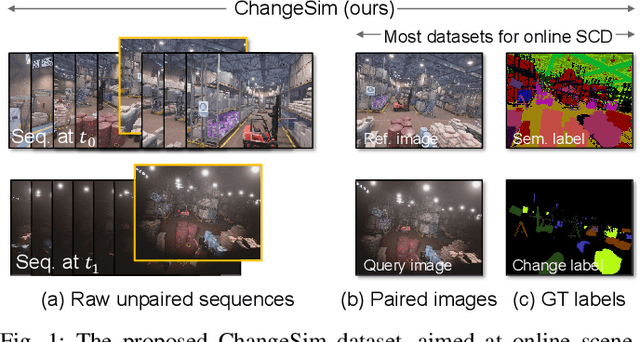


We present a challenging dataset, ChangeSim, aimed at online scene change detection (SCD) and more. The data is collected in photo-realistic simulation environments with the presence of environmental non-targeted variations, such as air turbidity and light condition changes, as well as targeted object changes in industrial indoor environments. By collecting data in simulations, multi-modal sensor data and precise ground truth labels are obtainable such as the RGB image, depth image, semantic segmentation, change segmentation, camera poses, and 3D reconstructions. While the previous online SCD datasets evaluate models given well-aligned image pairs, ChangeSim also provides raw unpaired sequences that present an opportunity to develop an online SCD model in an end-to-end manner, considering both pairing and detection. Experiments show that even the latest pair-based SCD models suffer from the bottleneck of the pairing process, and it gets worse when the environment contains the non-targeted variations. Our dataset is available at http://sammica.github.io/ChangeSim/.