 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards High-fidelity Head Blending with Chroma Keying for Industrial Applications
Nov 01, 2024We introduce an industrial Head Blending pipeline for the task of seamlessly integrating an actor's head onto a target body in digital content creation. The key challenge stems from discrepancies in head shape and hair structure, which lead to unnatural boundaries and blending artifacts. Existing methods treat foreground and background as a single task, resulting in suboptimal blending quality. To address this problem, we propose CHANGER, a novel pipeline that decouples background integration from foreground blending. By utilizing chroma keying for artifact-free background generation and introducing Head shape and long Hair augmentation ($H^2$ augmentation) to simulate a wide range of head shapes and hair styles, CHANGER improves generalization on innumerable various real-world cases. Furthermore, our Foreground Predictive Attention Transformer (FPAT) module enhances foreground blending by predicting and focusing on key head and body regions. Quantitative and qualitative evaluations on benchmark datasets demonstrate that our CHANGER outperforms state-of-the-art methods, delivering high-fidelity, industrial-grade results.
ChangeSim: Towards End-to-End Online Scene Change Detection in Industrial Indoor Environments
Mar 09, 2021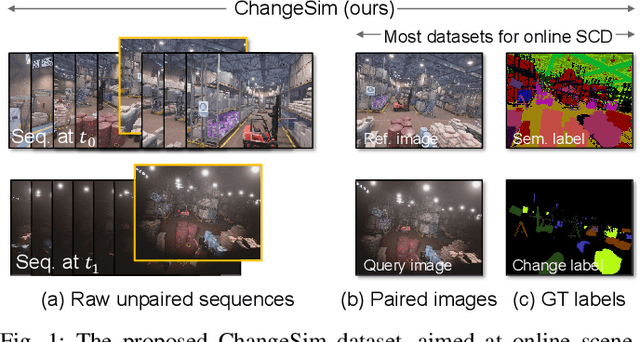

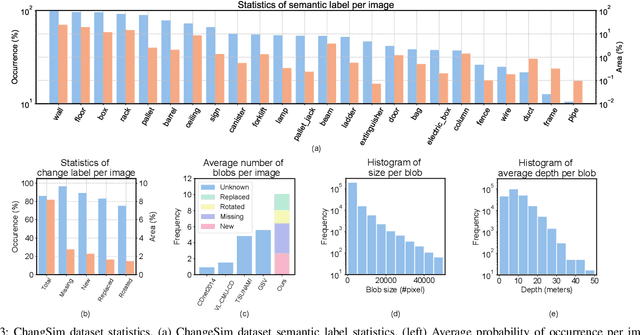

We present a challenging dataset, ChangeSim, aimed at online scene change detection (SCD) and more. The data is collected in photo-realistic simulation environments with the presence of environmental non-targeted variations, such as air turbidity and light condition changes, as well as targeted object changes in industrial indoor environments. By collecting data in simulations, multi-modal sensor data and precise ground truth labels are obtainable such as the RGB image, depth image, semantic segmentation, change segmentation, camera poses, and 3D reconstructions. While the previous online SCD datasets evaluate models given well-aligned image pairs, ChangeSim also provides raw unpaired sequences that present an opportunity to develop an online SCD model in an end-to-end manner, considering both pairing and detection. Experiments show that even the latest pair-based SCD models suffer from the bottleneck of the pairing process, and it gets worse when the environment contains the non-targeted variations. Our dataset is available at http://sammica.github.io/ChangeSim/.
Continual Unsupervised Domain Adaptation with Adversarial Learning
Oct 19, 2020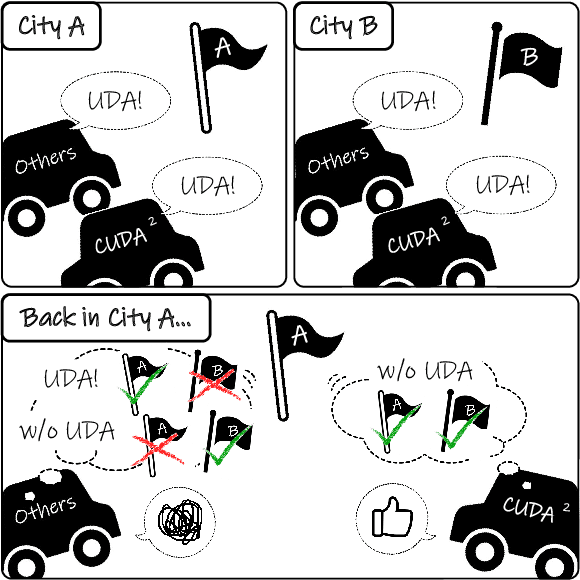
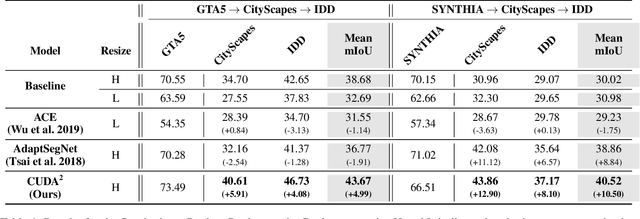
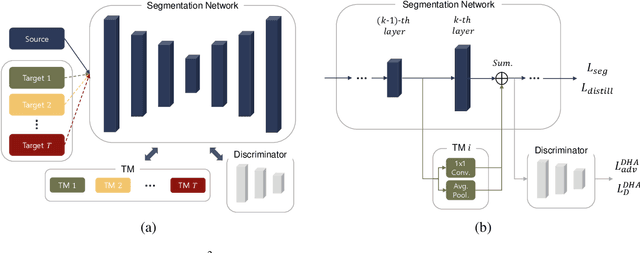
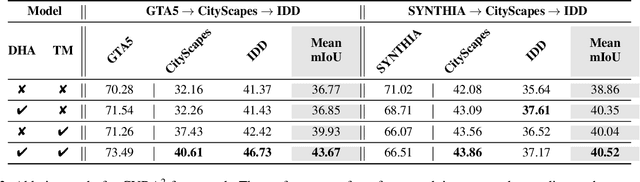
Unsupervised Domain Adaptation (UDA) is essential for autonomous driving due to a lack of labeled real-world road images. Most of the existing UDA methods, however, have focused on a single-step domain adaptation (Synthetic-to-Real). These methods overlook a change in environments in the real world as time goes by. Thus, developing a domain adaptation method for sequentially changing target domains without catastrophic forgetting is required for real-world applications. To deal with the problem above, we propose Continual Unsupervised Domain Adaptation with Adversarial learning (CUDA^2) framework, which can generally be applicable to other UDA methods conducting adversarial learning. CUDA^2 framework generates a sub-memory, called Target-specific Memory (TM) for each new target domain guided by Double Hinge Adversarial (DHA) loss. TM prevents catastrophic forgetting by storing target-specific information, and DHA loss induces a synergy between the existing network and the expanded TM. To the best of our knowledge, we consider realistic autonomous driving scenarios (Synthetic-to-Real-to-Real) in UDA research for the first time. The model with our framework outperforms other state-of-the-art models under the same settings. Besides, extensive experiments are conducted as ablation studies for in-depth analysis.
I-Keyboard: Fully Imaginary Keyboard on Touch Devices Empowered by Deep Neural Decoder
Jul 31, 2019

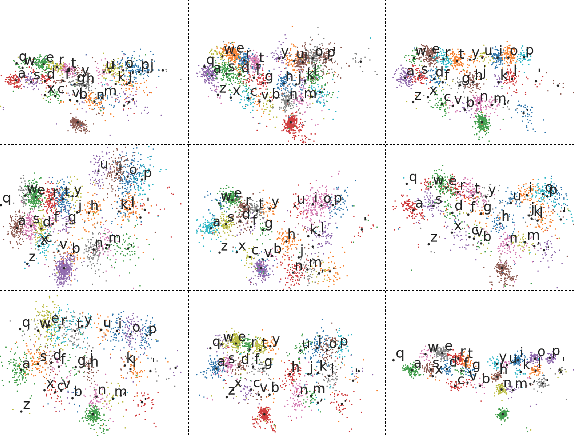
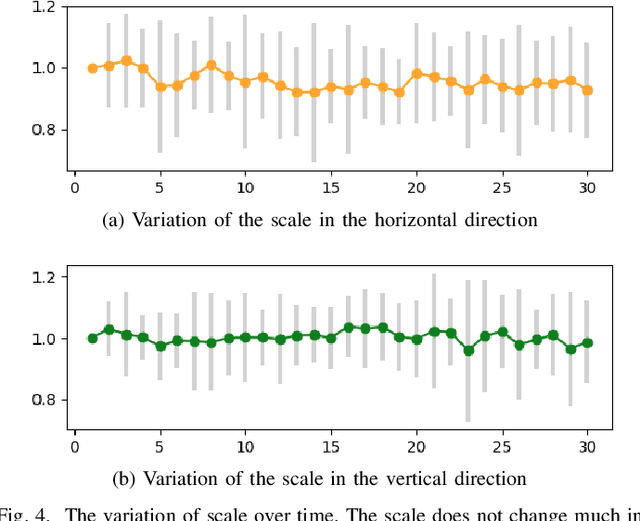
Text-entry aims to provide an effective and efficient pathway for humans to deliver their messages to computers. With the advent of mobile computing, the recent focus of text-entry research has moved from physical keyboards to soft keyboards. Current soft keyboards, however, increase the typo rate due to lack of tactile feedback and degrade the usability of mobile devices due to their large portion on screens. To tackle these limitations, we propose a fully imaginary keyboard (I-Keyboard) with a deep neural decoder (DND). The invisibility of I-Keyboard maximizes the usability of mobile devices and DND empowered by a deep neural architecture allows users to start typing from any position on the touch screens at any angle. To the best of our knowledge, the eyes-free ten-finger typing scenario of I-Keyboard which does not necessitate both a calibration step and a predefined region for typing is first explored in this work. For the purpose of training DND, we collected the largest user data in the process of developing I-Keyboard. We verified the performance of the proposed I-Keyboard and DND by conducting a series of comprehensive simulations and experiments under various conditions. I-Keyboard showed 18.95% and 4.06% increases in typing speed (45.57 WPM) and accuracy (95.84%), respectively over the baseline.