 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePooling Revisited: Your Receptive Field is Suboptimal
May 30, 2022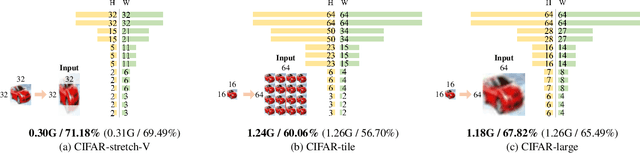
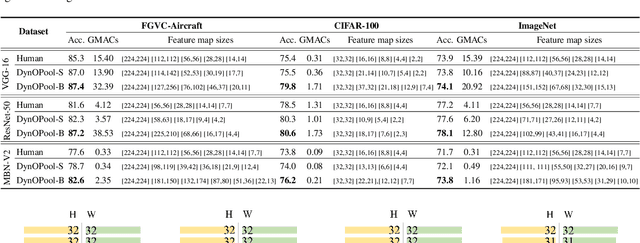
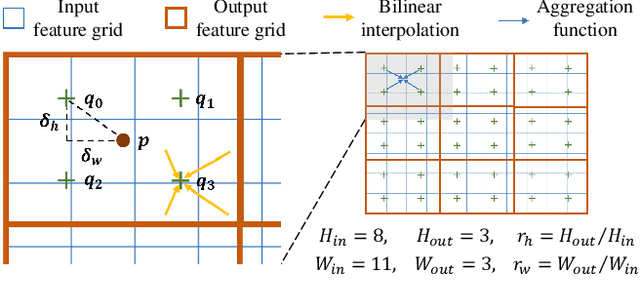
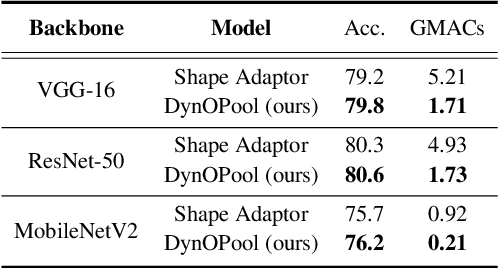
The size and shape of the receptive field determine how the network aggregates local information and affect the overall performance of a model considerably. Many components in a neural network, such as kernel sizes and strides for convolution and pooling operations, influence the configuration of a receptive field. However, they still rely on hyperparameters, and the receptive fields of existing models result in suboptimal shapes and sizes. Hence, we propose a simple yet effective Dynamically Optimized Pooling operation, referred to as DynOPool, which optimizes the scale factors of feature maps end-to-end by learning the desirable size and shape of its receptive field in each layer. Any kind of resizing modules in a deep neural network can be replaced by the operations with DynOPool at a minimal cost. Also, DynOPool controls the complexity of a model by introducing an additional loss term that constrains computational cost. Our experiments show that the models equipped with the proposed learnable resizing module outperform the baseline networks on multiple datasets in image classification and semantic segmentation.
Continual Unsupervised Domain Adaptation with Adversarial Learning
Oct 19, 2020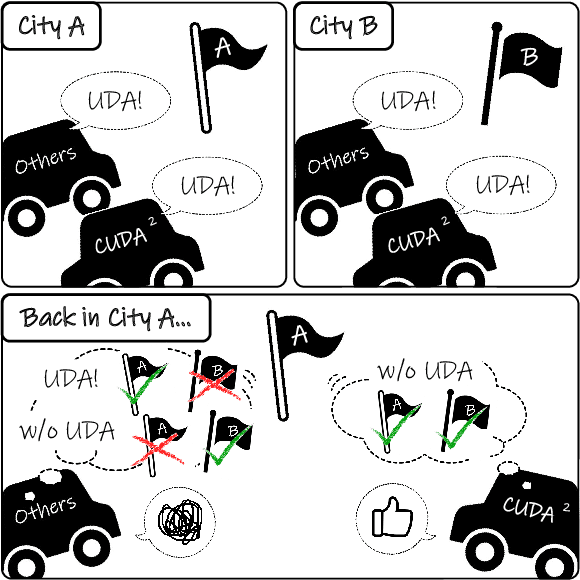
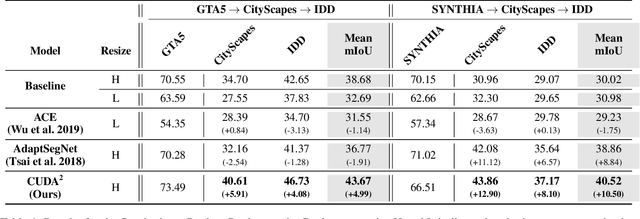
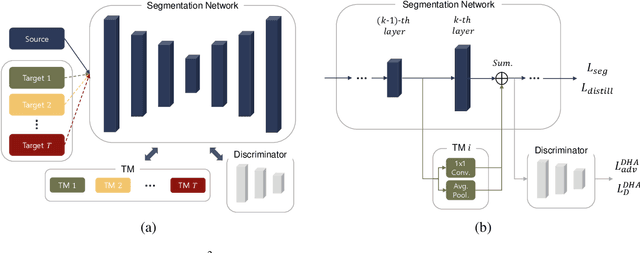
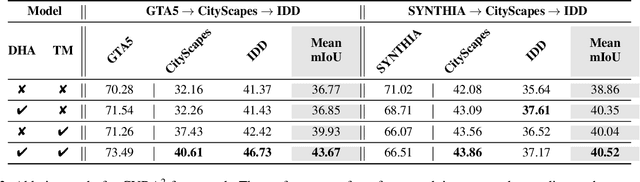
Unsupervised Domain Adaptation (UDA) is essential for autonomous driving due to a lack of labeled real-world road images. Most of the existing UDA methods, however, have focused on a single-step domain adaptation (Synthetic-to-Real). These methods overlook a change in environments in the real world as time goes by. Thus, developing a domain adaptation method for sequentially changing target domains without catastrophic forgetting is required for real-world applications. To deal with the problem above, we propose Continual Unsupervised Domain Adaptation with Adversarial learning (CUDA^2) framework, which can generally be applicable to other UDA methods conducting adversarial learning. CUDA^2 framework generates a sub-memory, called Target-specific Memory (TM) for each new target domain guided by Double Hinge Adversarial (DHA) loss. TM prevents catastrophic forgetting by storing target-specific information, and DHA loss induces a synergy between the existing network and the expanded TM. To the best of our knowledge, we consider realistic autonomous driving scenarios (Synthetic-to-Real-to-Real) in UDA research for the first time. The model with our framework outperforms other state-of-the-art models under the same settings. Besides, extensive experiments are conducted as ablation studies for in-depth analysis.