 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRewardFlow: Generate Images by Optimizing What You Reward
Apr 09, 2026We introduce RewardFlow, an inversion-free framework that steers pretrained diffusion and flow-matching models at inference time through multi-reward Langevin dynamics. RewardFlow unifies complementary differentiable rewards for semantic alignment, perceptual fidelity, localized grounding, object consistency, and human preference, and further introduces a differentiable VQA-based reward that provides fine-grained semantic supervision through language-vision reasoning. To coordinate these heterogeneous objectives, we design a prompt-aware adaptive policy that extracts semantic primitives from the instruction, infers edit intent, and dynamically modulates reward weights and step sizes throughout sampling. Across several image editing and compositional generation benchmarks, RewardFlow delivers state-of-the-art edit fidelity and compositional alignment.
PyraTok: Language-Aligned Pyramidal Tokenizer for Video Understanding and Generation
Jan 22, 2026Discrete video VAEs underpin modern text-to-video generation and video understanding systems, yet existing tokenizers typically learn visual codebooks at a single scale with limited vocabularies and shallow language supervision, leading to poor cross-modal alignment and zero-shot transfer. We introduce PyraTok, a language-aligned pyramidal tokenizer that learns semantically structured discrete latents across multiple spatiotemporal resolutions. PyraTok builds on a pretrained video VAE and a novel Language aligned Pyramidal Quantization (LaPQ) module that discretizes encoder features at several depths using a shared large binary codebook, yielding compact yet expressive video token sequences. To tightly couple visual tokens with language, PyraTok jointly optimizes multi-scale text-guided quantization and a global autoregressive objective over the token hierarchy. Across ten benchmarks, PyraTok delivers state-of-the-art (SOTA) video reconstruction, consistently improves text-to-video quality, and sets new SOTA zero-shot performance on video segmentation, temporal action localization, and video understanding, scaling robustly to up to 4K/8K resolutions.
Model Stock: All we need is just a few fine-tuned models
Mar 28, 2024This paper introduces an efficient fine-tuning method for large pre-trained models, offering strong in-distribution (ID) and out-of-distribution (OOD) performance. Breaking away from traditional practices that need a multitude of fine-tuned models for averaging, our approach employs significantly fewer models to achieve final weights yet yield superior accuracy. Drawing from key insights in the weight space of fine-tuned weights, we uncover a strong link between the performance and proximity to the center of weight space. Based on this, we introduce a method that approximates a center-close weight using only two fine-tuned models, applicable during or after training. Our innovative layer-wise weight averaging technique surpasses state-of-the-art model methods such as Model Soup, utilizing only two fine-tuned models. This strategy can be aptly coined Model Stock, highlighting its reliance on selecting a minimal number of models to draw a more optimized-averaged model. We demonstrate the efficacy of Model Stock with fine-tuned models based upon pre-trained CLIP architectures, achieving remarkable performance on both ID and OOD tasks on the standard benchmarks, all while barely bringing extra computational demands. Our code and pre-trained models are available at https://github.com/naver-ai/model-stock.
Pooling Revisited: Your Receptive Field is Suboptimal
May 30, 2022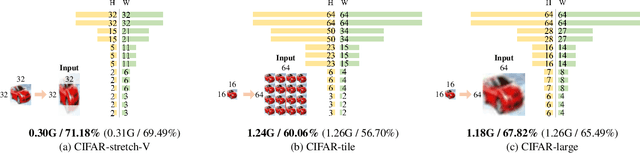
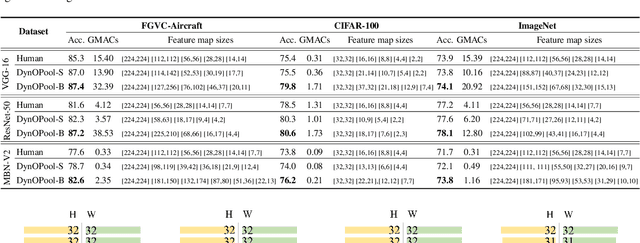
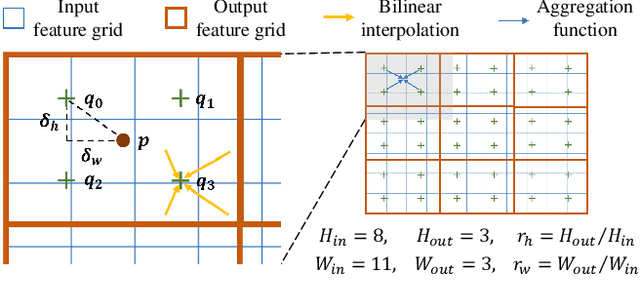
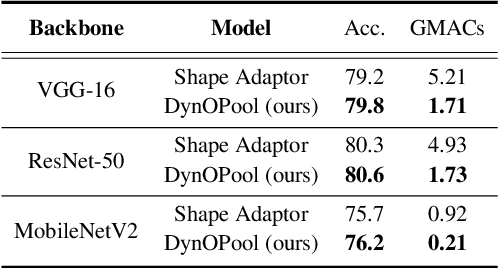
The size and shape of the receptive field determine how the network aggregates local information and affect the overall performance of a model considerably. Many components in a neural network, such as kernel sizes and strides for convolution and pooling operations, influence the configuration of a receptive field. However, they still rely on hyperparameters, and the receptive fields of existing models result in suboptimal shapes and sizes. Hence, we propose a simple yet effective Dynamically Optimized Pooling operation, referred to as DynOPool, which optimizes the scale factors of feature maps end-to-end by learning the desirable size and shape of its receptive field in each layer. Any kind of resizing modules in a deep neural network can be replaced by the operations with DynOPool at a minimal cost. Also, DynOPool controls the complexity of a model by introducing an additional loss term that constrains computational cost. Our experiments show that the models equipped with the proposed learnable resizing module outperform the baseline networks on multiple datasets in image classification and semantic segmentation.