 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Concepts Speak Louder Than Words:Explainable Video Action Recognition
Nov 05, 2025Effective explanations of video action recognition models should disentangle how movements unfold over time from the surrounding spatial context. However, existing methods based on saliency produce entangled explanations, making it unclear whether predictions rely on motion or spatial context. Language-based approaches offer structure but often fail to explain motions due to their tacit nature -- intuitively understood but difficult to verbalize. To address these challenges, we propose Disentangled Action aNd Context concept-based Explainable (DANCE) video action recognition, a framework that predicts actions through disentangled concept types: motion dynamics, objects, and scenes. We define motion dynamics concepts as human pose sequences. We employ a large language model to automatically extract object and scene concepts. Built on an ante-hoc concept bottleneck design, DANCE enforces prediction through these concepts. Experiments on four datasets -- KTH, Penn Action, HAA500, and UCF-101 -- demonstrate that DANCE significantly improves explanation clarity with competitive performance. We validate the superior interpretability of DANCE through a user study. Experimental results also show that DANCE is beneficial for model debugging, editing, and failure analysis.
ConceptSplit: Decoupled Multi-Concept Personalization of Diffusion Models via Token-wise Adaptation and Attention Disentanglement
Oct 06, 2025In recent years, multi-concept personalization for text-to-image (T2I) diffusion models to represent several subjects in an image has gained much more attention. The main challenge of this task is "concept mixing", where multiple learned concepts interfere or blend undesirably in the output image. To address this issue, in this paper, we present ConceptSplit, a novel framework to split the individual concepts through training and inference. Our framework comprises two key components. First, we introduce Token-wise Value Adaptation (ToVA), a merging-free training method that focuses exclusively on adapting the value projection in cross-attention. Based on our empirical analysis, we found that modifying the key projection, a common approach in existing methods, can disrupt the attention mechanism and lead to concept mixing. Second, we propose Latent Optimization for Disentangled Attention (LODA), which alleviates attention entanglement during inference by optimizing the input latent. Through extensive qualitative and quantitative experiments, we demonstrate that ConceptSplit achieves robust multi-concept personalization, mitigating unintended concept interference. Code is available at https://github.com/KU-VGI/ConceptSplit
ESSENTIAL: Episodic and Semantic Memory Integration for Video Class-Incremental Learning
Aug 14, 2025In this work, we tackle the problem of video classincremental learning (VCIL). Many existing VCIL methods mitigate catastrophic forgetting by rehearsal training with a few temporally dense samples stored in episodic memory, which is memory-inefficient. Alternatively, some methods store temporally sparse samples, sacrificing essential temporal information and thereby resulting in inferior performance. To address this trade-off between memory-efficiency and performance, we propose EpiSodic and SEmaNTIc memory integrAtion for video class-incremental Learning (ESSENTIAL). ESSENTIAL consists of episodic memory for storing temporally sparse features and semantic memory for storing general knowledge represented by learnable prompts. We introduce a novel memory retrieval (MR) module that integrates episodic memory and semantic prompts through cross-attention, enabling the retrieval of temporally dense features from temporally sparse features. We rigorously validate ESSENTIAL on diverse datasets: UCF-101, HMDB51, and Something-Something-V2 from the TCD benchmark and UCF-101, ActivityNet, and Kinetics-400 from the vCLIMB benchmark. Remarkably, with significantly reduced memory, ESSENTIAL achieves favorable performance on the benchmarks.
Do Not Mimic My Voice: Speaker Identity Unlearning for Zero-Shot Text-to-Speech
Jul 27, 2025The rapid advancement of Zero-Shot Text-to-Speech (ZS-TTS) technology has enabled high-fidelity voice synthesis from minimal audio cues, raising significant privacy and ethical concerns. Despite the threats to voice privacy, research to selectively remove the knowledge to replicate unwanted individual voices from pre-trained model parameters has not been explored. In this paper, we address the new challenge of speaker identity unlearning for ZS-TTS systems. To meet this goal, we propose the first machine unlearning frameworks for ZS-TTS, especially Teacher-Guided Unlearning (TGU), designed to ensure the model forgets designated speaker identities while retaining its ability to generate accurate speech for other speakers. Our proposed methods incorporate randomness to prevent consistent replication of forget speakers' voices, assuring unlearned identities remain untraceable. Additionally, we propose a new evaluation metric, speaker-Zero Retrain Forgetting (spk-ZRF). This assesses the model's ability to disregard prompts associated with forgotten speakers, effectively neutralizing its knowledge of these voices. The experiments conducted on the state-of-the-art model demonstrate that TGU prevents the model from replicating forget speakers' voices while maintaining high quality for other speakers. The demo is available at https://speechunlearn.github.io/
SFUOD: Source-Free Unknown Object Detection
Jul 23, 2025Source-free object detection adapts a detector pre-trained on a source domain to an unlabeled target domain without requiring access to labeled source data. While this setting is practical as it eliminates the need for the source dataset during domain adaptation, it operates under the restrictive assumption that only pre-defined objects from the source domain exist in the target domain. This closed-set setting prevents the detector from detecting undefined objects. To ease this assumption, we propose Source-Free Unknown Object Detection (SFUOD), a novel scenario which enables the detector to not only recognize known objects but also detect undefined objects as unknown objects. To this end, we propose CollaPAUL (Collaborative tuning and Principal Axis-based Unknown Labeling), a novel framework for SFUOD. Collaborative tuning enhances knowledge adaptation by integrating target-dependent knowledge from the auxiliary encoder with source-dependent knowledge from the pre-trained detector through a cross-domain attention mechanism. Additionally, principal axes-based unknown labeling assigns pseudo-labels to unknown objects by estimating objectness via principal axes projection and confidence scores from model predictions. The proposed CollaPAUL achieves state-of-the-art performances on SFUOD benchmarks, and extensive experiments validate its effectiveness.
Universal Domain Adaptation for Semantic Segmentation
May 28, 2025Unsupervised domain adaptation for semantic segmentation (UDA-SS) aims to transfer knowledge from labeled source data to unlabeled target data. However, traditional UDA-SS methods assume that category settings between source and target domains are known, which is unrealistic in real-world scenarios. This leads to performance degradation if private classes exist. To address this limitation, we propose Universal Domain Adaptation for Semantic Segmentation (UniDA-SS), achieving robust adaptation even without prior knowledge of category settings. We define the problem in the UniDA-SS scenario as low confidence scores of common classes in the target domain, which leads to confusion with private classes. To solve this problem, we propose UniMAP: UniDA-SS with Image Matching and Prototype-based Distinction, a novel framework composed of two key components. First, Domain-Specific Prototype-based Distinction (DSPD) divides each class into two domain-specific prototypes, enabling finer separation of domain-specific features and enhancing the identification of common classes across domains. Second, Target-based Image Matching (TIM) selects a source image containing the most common-class pixels based on the target pseudo-label and pairs it in a batch to promote effective learning of common classes. We also introduce a new UniDA-SS benchmark and demonstrate through various experiments that UniMAP significantly outperforms baselines. The code is available at \href{https://github.com/KU-VGI/UniMAP}{this https URL}.
PCBEAR: Pose Concept Bottleneck for Explainable Action Recognition
Apr 17, 2025Human action recognition (HAR) has achieved impressive results with deep learning models, but their decision-making process remains opaque due to their black-box nature. Ensuring interpretability is crucial, especially for real-world applications requiring transparency and accountability. Existing video XAI methods primarily rely on feature attribution or static textual concepts, both of which struggle to capture motion dynamics and temporal dependencies essential for action understanding. To address these challenges, we propose Pose Concept Bottleneck for Explainable Action Recognition (PCBEAR), a novel concept bottleneck framework that introduces human pose sequences as motion-aware, structured concepts for video action recognition. Unlike methods based on pixel-level features or static textual descriptions, PCBEAR leverages human skeleton poses, which focus solely on body movements, providing robust and interpretable explanations of motion dynamics. We define two types of pose-based concepts: static pose concepts for spatial configurations at individual frames, and dynamic pose concepts for motion patterns across multiple frames. To construct these concepts, PCBEAR applies clustering to video pose sequences, allowing for automatic discovery of meaningful concepts without manual annotation. We validate PCBEAR on KTH, Penn-Action, and HAA500, showing that it achieves high classification performance while offering interpretable, motion-driven explanations. Our method provides both strong predictive performance and human-understandable insights into the model's reasoning process, enabling test-time interventions for debugging and improving model behavior.
ESC: Erasing Space Concept for Knowledge Deletion
Apr 03, 2025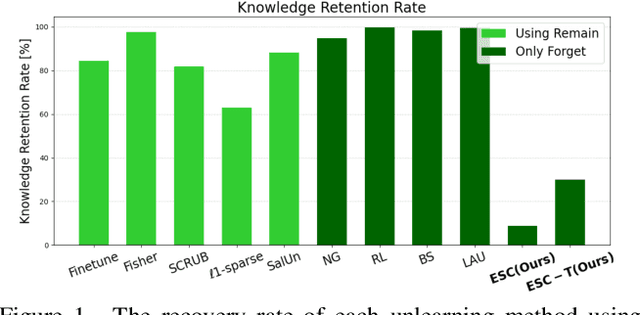



As concerns regarding privacy in deep learning continue to grow, individuals are increasingly apprehensive about the potential exploitation of their personal knowledge in trained models. Despite several research efforts to address this, they often fail to consider the real-world demand from users for complete knowledge erasure. Furthermore, our investigation reveals that existing methods have a risk of leaking personal knowledge through embedding features. To address these issues, we introduce a novel concept of Knowledge Deletion (KD), an advanced task that considers both concerns, and provides an appropriate metric, named Knowledge Retention score (KR), for assessing knowledge retention in feature space. To achieve this, we propose a novel training-free erasing approach named Erasing Space Concept (ESC), which restricts the important subspace for the forgetting knowledge by eliminating the relevant activations in the feature. In addition, we suggest ESC with Training (ESC-T), which uses a learnable mask to better balance the trade-off between forgetting and preserving knowledge in KD. Our extensive experiments on various datasets and models demonstrate that our proposed methods achieve the fastest and state-of-the-art performance. Notably, our methods are applicable to diverse forgetting scenarios, such as facial domain setting, demonstrating the generalizability of our methods. The code is available at http://github.com/KU-VGI/ESC .
Multispectral Pedestrian Detection with Sparsely Annotated Label
Jan 05, 2025



Although existing Sparsely Annotated Object Detection (SAOD) approches have made progress in handling sparsely annotated environments in multispectral domain, where only some pedestrians are annotated, they still have the following limitations: (i) they lack considerations for improving the quality of pseudo-labels for missing annotations, and (ii) they rely on fixed ground truth annotations, which leads to learning only a limited range of pedestrian visual appearances in the multispectral domain. To address these issues, we propose a novel framework called Sparsely Annotated Multispectral Pedestrian Detection (SAMPD). For limitation (i), we introduce Multispectral Pedestrian-aware Adaptive Weight (MPAW) and Positive Pseudo-label Enhancement (PPE) module. Utilizing multispectral knowledge, these modules ensure the generation of high-quality pseudo-labels and enable effective learning by increasing weights for high-quality pseudo-labels based on modality characteristics. To address limitation (ii), we propose an Adaptive Pedestrian Retrieval Augmentation (APRA) module, which adaptively incorporates pedestrian patches from ground-truth and dynamically integrates high-quality pseudo-labels with the ground-truth, facilitating a more diverse learning pool of pedestrians. Extensive experimental results demonstrate that our SAMPD significantly enhances performance in sparsely annotated environments within the multispectral domain.
Towards High-fidelity Head Blending with Chroma Keying for Industrial Applications
Nov 01, 2024We introduce an industrial Head Blending pipeline for the task of seamlessly integrating an actor's head onto a target body in digital content creation. The key challenge stems from discrepancies in head shape and hair structure, which lead to unnatural boundaries and blending artifacts. Existing methods treat foreground and background as a single task, resulting in suboptimal blending quality. To address this problem, we propose CHANGER, a novel pipeline that decouples background integration from foreground blending. By utilizing chroma keying for artifact-free background generation and introducing Head shape and long Hair augmentation ($H^2$ augmentation) to simulate a wide range of head shapes and hair styles, CHANGER improves generalization on innumerable various real-world cases. Furthermore, our Foreground Predictive Attention Transformer (FPAT) module enhances foreground blending by predicting and focusing on key head and body regions. Quantitative and qualitative evaluations on benchmark datasets demonstrate that our CHANGER outperforms state-of-the-art methods, delivering high-fidelity, industrial-grade results.