 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmbient-robust Inverse Rendering using Active RGB-NIR Imaging
May 28, 2026Inverse rendering aims to reconstruct geometry and reflectance of objects from images. Despite recent progress, existing methods often produces inaccurate reconstructions that are sensitive to ambient illumination conditions. Here we introduce an ambient-robust inverse rendering method enabled by active RGB-NIR imaging. Our key insight is to leverage near-infrared (NIR) flash illumination-imperceptible to human observers-to obtain stable point-light shading that is largely invariant to ambient illumination. By using multi-view RGB images illuminated by ambient light and NIR images acquired with active NIR flash illumination, we reconstruct accurate geometry and reflectance by exploiting the complementary benefits of RGB and NIR images via a three-stage inverse rendering method. To enable dense multi-view acquisition, we develop an active imaging system equipped with a RGB-NIR camera and a NIR flash mounted on a mobile base. Using this system, we collect the first multi-view RGB-NIR inverse rendering dataset captured under multiple ambient illumination conditions. Experiments demonstrate that our method outperforms prior approaches, achieving accurate geometry and reflectance estimation across multiple ambient lighting scenarios.
Towards High-fidelity Head Blending with Chroma Keying for Industrial Applications
Nov 01, 2024We introduce an industrial Head Blending pipeline for the task of seamlessly integrating an actor's head onto a target body in digital content creation. The key challenge stems from discrepancies in head shape and hair structure, which lead to unnatural boundaries and blending artifacts. Existing methods treat foreground and background as a single task, resulting in suboptimal blending quality. To address this problem, we propose CHANGER, a novel pipeline that decouples background integration from foreground blending. By utilizing chroma keying for artifact-free background generation and introducing Head shape and long Hair augmentation ($H^2$ augmentation) to simulate a wide range of head shapes and hair styles, CHANGER improves generalization on innumerable various real-world cases. Furthermore, our Foreground Predictive Attention Transformer (FPAT) module enhances foreground blending by predicting and focusing on key head and body regions. Quantitative and qualitative evaluations on benchmark datasets demonstrate that our CHANGER outperforms state-of-the-art methods, delivering high-fidelity, industrial-grade results.
Design and Operation of Autonomous Wheelchair Towing Robot
May 23, 2023


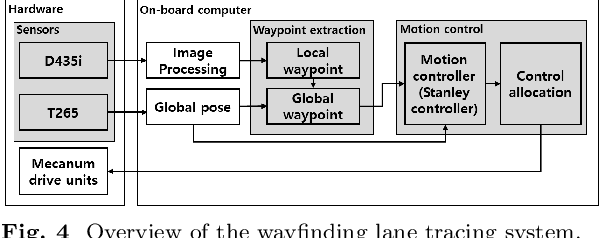
In this study, a new concept of a wheelchair-towing robot for the facile electrification of manual wheelchairs is introduced. The development of this concept includes the design of towing robot hardware and an autonomous driving algorithm to ensure the safe transportation of patients to their intended destinations inside the hospital. We developed a novel docking mechanism to facilitate easy docking and separation between the towing robot and the manual wheelchair, which is connected to the front caster wheel of the manual wheelchair. The towing robot has a mecanum wheel drive, enabling the robot to move with a high degree of freedom in the standalone driving mode while adhering to kinematic constraints in the docking mode. Our novel towing robot features a camera sensor that can observe the ground ahead which allows the robot to autonomously follow color-coded wayfinding lanes installed in hospital corridors. This study introduces dedicated image processing techniques for capturing the lanes and control algorithms for effectively tracing a path to achieve autonomous path following. The autonomous towing performance of our proposed platform was validated by a real-world experiment in which a hospital environment with colored lanes was created.
OAMixer: Object-aware Mixing Layer for Vision Transformers
Dec 13, 2022



Patch-based models, e.g., Vision Transformers (ViTs) and Mixers, have shown impressive results on various visual recognition tasks, alternating classic convolutional networks. While the initial patch-based models (ViTs) treated all patches equally, recent studies reveal that incorporating inductive bias like spatiality benefits the representations. However, most prior works solely focused on the location of patches, overlooking the scene structure of images. Thus, we aim to further guide the interaction of patches using the object information. Specifically, we propose OAMixer (object-aware mixing layer), which calibrates the patch mixing layers of patch-based models based on the object labels. Here, we obtain the object labels in unsupervised or weakly-supervised manners, i.e., no additional human-annotating cost is necessary. Using the object labels, OAMixer computes a reweighting mask with a learnable scale parameter that intensifies the interaction of patches containing similar objects and applies the mask to the patch mixing layers. By learning an object-centric representation, we demonstrate that OAMixer improves the classification accuracy and background robustness of various patch-based models, including ViTs, MLP-Mixers, and ConvMixers. Moreover, we show that OAMixer enhances various downstream tasks, including large-scale classification, self-supervised learning, and multi-object recognition, verifying the generic applicability of OAMixer
Object-aware Contrastive Learning for Debiased Scene Representation
Jul 30, 2021

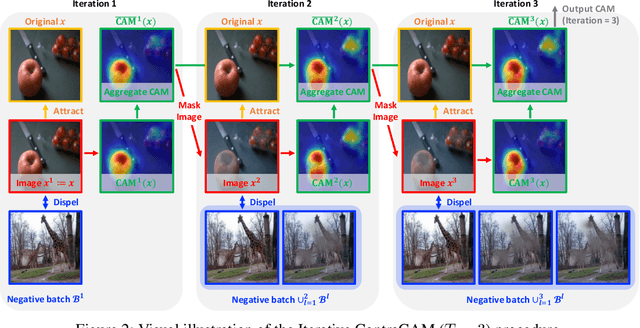

Contrastive self-supervised learning has shown impressive results in learning visual representations from unlabeled images by enforcing invariance against different data augmentations. However, the learned representations are often contextually biased to the spurious scene correlations of different objects or object and background, which may harm their generalization on the downstream tasks. To tackle the issue, we develop a novel object-aware contrastive learning framework that first (a) localizes objects in a self-supervised manner and then (b) debias scene correlations via appropriate data augmentations considering the inferred object locations. For (a), we propose the contrastive class activation map (ContraCAM), which finds the most discriminative regions (e.g., objects) in the image compared to the other images using the contrastively trained models. We further improve the ContraCAM to detect multiple objects and entire shapes via an iterative refinement procedure. For (b), we introduce two data augmentations based on ContraCAM, object-aware random crop and background mixup, which reduce contextual and background biases during contrastive self-supervised learning, respectively. Our experiments demonstrate the effectiveness of our representation learning framework, particularly when trained under multi-object images or evaluated under the background (and distribution) shifted images.