 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Forest and Trees in Images and Long Captions for Visually Grounded Understanding
Feb 03, 2026Large vision-language models such as CLIP struggle with long captions because they align images and texts as undifferentiated wholes. Fine-grained vision-language understanding requires hierarchical semantics capturing both global context and localized details across visual and textual domains. Yet linguistic hierarchies from syntax or semantics rarely match visual organization, and purely visual hierarchies tend to fragment scenes into appearance-driven parts without semantic focus. We propose CAFT (Cross-domain Alignment of Forests and Trees), a hierarchical image-text representation learning framework that aligns global and local semantics across images and long captions without pixel-level supervision. Coupling a fine-to-coarse visual encoder with a hierarchical text transformer, it uses a hierarchical alignment loss that matches whole images with whole captions while biasing region-sentence correspondences, so that coarse semantics are built from fine-grained evidence rather than from aggregation untethered to part-level grounding. Trained on 30M image-text pairs, CAFT achieves state-of-the-art performance on six long-text retrieval benchmarks and exhibits strong scaling behavior. Experiments show that hierarchical cross-domain alignment enables fine-grained, visually grounded image-text representations to emerge without explicit region-level supervision.
SHED Light on Segmentation for Dense Prediction
Jan 30, 2026Dense prediction infers per-pixel values from a single image and is fundamental to 3D perception and robotics. Although real-world scenes exhibit strong structure, existing methods treat it as an independent pixel-wise prediction, often resulting in structural inconsistencies. We propose SHED, a novel encoder-decoder architecture that enforces geometric prior explicitly by incorporating segmentation into dense prediction. By bidirectional hierarchical reasoning, segment tokens are hierarchically pooled in the encoder and unpooled in the decoder to reverse the hierarchy. The model is supervised only at the final output, allowing the segment hierarchy to emerge without explicit segmentation supervision. SHED improves depth boundary sharpness and segment coherence, while demonstrating strong cross-domain generalization from synthetic to the real-world environments. Its hierarchy-aware decoder better captures global 3D scene layouts, leading to improved semantic segmentation performance. Moreover, SHED enhances 3D reconstruction quality and reveals interpretable part-level structures that are often missed by conventional pixel-wise methods.
Bring My Cup! Personalizing Vision-Language-Action Models with Visual Attentive Prompting
Dec 23, 2025While Vision-Language-Action (VLA) models generalize well to generic instructions, they struggle with personalized commands such as "bring my cup", where the robot must act on one specific instance among visually similar objects. We study this setting of manipulating personal objects, in which a VLA must identify and control a user-specific object unseen during training using only a few reference images. To address this challenge, we propose Visual Attentive Prompting (VAP), a simple-yet-effective training-free perceptual adapter that equips frozen VLAs with top-down selective attention. VAP treats the reference images as a non-parametric visual memory, grounds the personal object in the scene through open-vocabulary detection and embedding-based matching, and then injects this grounding as a visual prompt by highlighting the object and rewriting the instruction. We construct two simulation benchmarks, Personalized-SIMPLER and Personalized-VLABench, and a real-world tabletop benchmark to evaluate personalized manipulation across multiple robots and tasks. Experiments show that VAP consistently outperforms generic policies and token-learning baselines in both success rate and correct-object manipulation, helping to bridge the gap between semantic understanding and instance-level control.
Open Ad-hoc Categorization with Contextualized Feature Learning
Dec 18, 2025Adaptive categorization of visual scenes is essential for AI agents to handle changing tasks. Unlike fixed common categories for plants or animals, ad-hoc categories are created dynamically to serve specific goals. We study open ad-hoc categorization: Given a few labeled exemplars and abundant unlabeled data, the goal is to discover the underlying context and to expand ad-hoc categories through semantic extension and visual clustering around it. Building on the insight that ad-hoc and common categories rely on similar perceptual mechanisms, we propose OAK, a simple model that introduces a small set of learnable context tokens at the input of a frozen CLIP and optimizes with both CLIP's image-text alignment objective and GCD's visual clustering objective. On Stanford and Clevr-4 datasets, OAK achieves state-of-the-art in accuracy and concept discovery across multiple categorizations, including 87.4% novel accuracy on Stanford Mood, surpassing CLIP and GCD by over 50%. Moreover, OAK produces interpretable saliency maps, focusing on hands for Action, faces for Mood, and backgrounds for Location, promoting transparency and trust while enabling adaptive and generalizable categorization.
* 26 pages, 17 figures
Sparsified State-Space Models are Efficient Highway Networks
May 27, 2025State-space models (SSMs) offer a promising architecture for sequence modeling, providing an alternative to Transformers by replacing expensive self-attention with linear recurrences. In this paper, we propose a simple yet effective trick to enhance SSMs within given computational budgets by sparsifying them. Our intuition is that tokens in SSMs are highly redundant due to gradual recurrent updates, and dense recurrence operations block the delivery of past information. In particular, we observe that upper layers of SSMs tend to be more redundant as they encode global information, while lower layers encode local information. Motivated by this, we introduce Simba, a hierarchical sparsification method for SSMs based on token pruning. Simba sparsifies upper layers more than lower layers, encouraging the upper layers to behave like highways. To achieve this, we propose a novel token pruning criterion for SSMs, measuring the global impact of tokens on the final output by accumulating local recurrences. We demonstrate that Simba outperforms the baseline model, Mamba, with the same FLOPS in various natural language tasks. Moreover, we illustrate the effect of highways, showing that Simba not only enhances efficiency but also improves the information flow across long sequences. Code is available at https://github.com/woominsong/Simba.
SuRe: Summarizing Retrievals using Answer Candidates for Open-domain QA of LLMs
Apr 17, 2024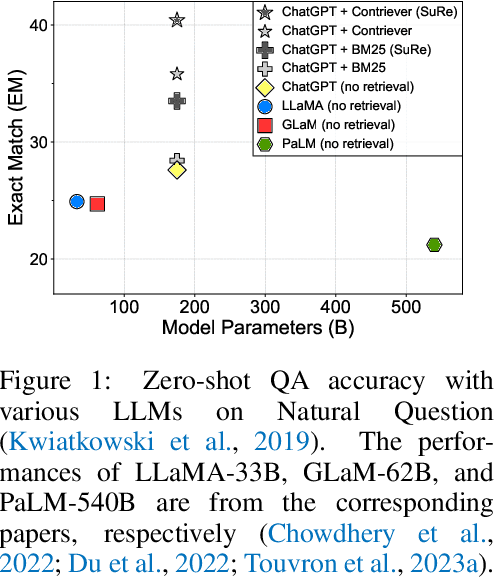
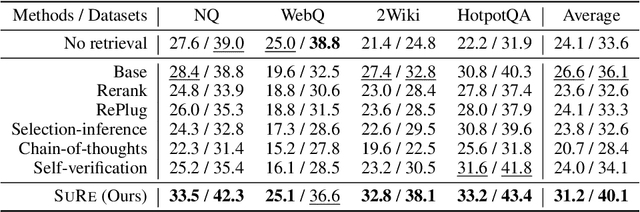

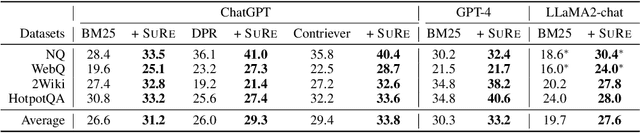
Large language models (LLMs) have made significant advancements in various natural language processing tasks, including question answering (QA) tasks. While incorporating new information with the retrieval of relevant passages is a promising way to improve QA with LLMs, the existing methods often require additional fine-tuning which becomes infeasible with recent LLMs. Augmenting retrieved passages via prompting has the potential to address this limitation, but this direction has been limitedly explored. To this end, we design a simple yet effective framework to enhance open-domain QA (ODQA) with LLMs, based on the summarized retrieval (SuRe). SuRe helps LLMs predict more accurate answers for a given question, which are well-supported by the summarized retrieval that could be viewed as an explicit rationale extracted from the retrieved passages. Specifically, SuRe first constructs summaries of the retrieved passages for each of the multiple answer candidates. Then, SuRe confirms the most plausible answer from the candidate set by evaluating the validity and ranking of the generated summaries. Experimental results on diverse ODQA benchmarks demonstrate the superiority of SuRe, with improvements of up to 4.6% in exact match (EM) and 4.0% in F1 score over standard prompting approaches. SuRe also can be integrated with a broad range of retrieval methods and LLMs. Finally, the generated summaries from SuRe show additional advantages to measure the importance of retrieved passages and serve as more preferred rationales by models and humans.
Hierarchical Context Merging: Better Long Context Understanding for Pre-trained LLMs
Apr 16, 2024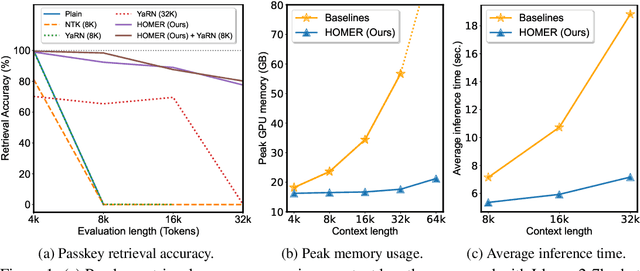
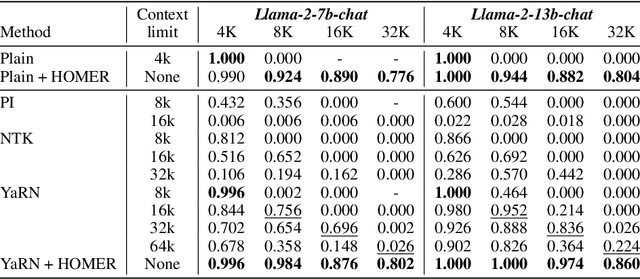
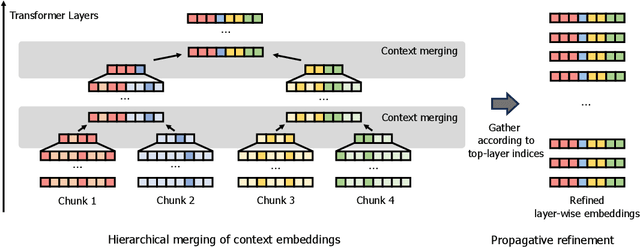
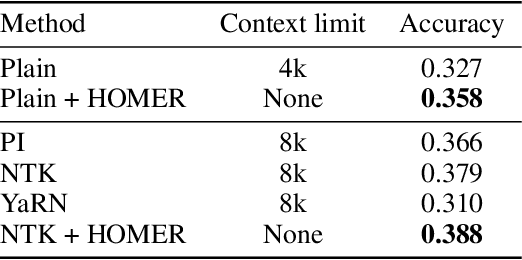
Large language models (LLMs) have shown remarkable performance in various natural language processing tasks. However, a primary constraint they face is the context limit, i.e., the maximum number of tokens they can process. Previous works have explored architectural changes and modifications in positional encoding to relax the constraint, but they often require expensive training or do not address the computational demands of self-attention. In this paper, we present Hierarchical cOntext MERging (HOMER), a new training-free scheme designed to overcome the limitations. HOMER uses a divide-and-conquer algorithm, dividing long inputs into manageable chunks. Each chunk is then processed collectively, employing a hierarchical strategy that merges adjacent chunks at progressive transformer layers. A token reduction technique precedes each merging, ensuring memory usage efficiency. We also propose an optimized computational order reducing the memory requirement to logarithmically scale with respect to input length, making it especially favorable for environments with tight memory restrictions. Our experiments demonstrate the proposed method's superior performance and memory efficiency, enabling the broader use of LLMs in contexts requiring extended context. Code is available at https://github.com/alinlab/HOMER.
S-CLIP: Semi-supervised Vision-Language Pre-training using Few Specialist Captions
May 23, 2023


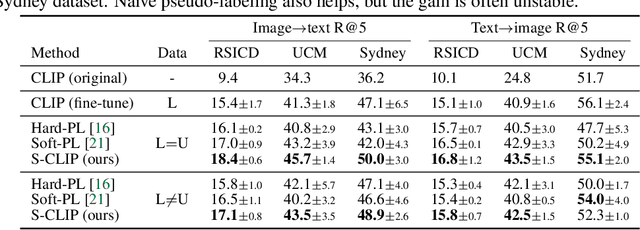
Vision-language models, such as contrastive language-image pre-training (CLIP), have demonstrated impressive results in natural image domains. However, these models often struggle when applied to specialized domains like remote sensing, and adapting to such domains is challenging due to the limited number of image-text pairs available for training. To address this, we propose S-CLIP, a semi-supervised learning method for training CLIP that utilizes additional unpaired images. S-CLIP employs two pseudo-labeling strategies specifically designed for contrastive learning and the language modality. The caption-level pseudo-label is given by a combination of captions of paired images, obtained by solving an optimal transport problem between unpaired and paired images. The keyword-level pseudo-label is given by a keyword in the caption of the nearest paired image, trained through partial label learning that assumes a candidate set of labels for supervision instead of the exact one. By combining these objectives, S-CLIP significantly enhances the training of CLIP using only a few image-text pairs, as demonstrated in various specialist domains, including remote sensing, fashion, scientific figures, and comics. For instance, S-CLIP improves CLIP by 10% for zero-shot classification and 4% for image-text retrieval on the remote sensing benchmark, matching the performance of supervised CLIP while using three times fewer image-text pairs.
RoPAWS: Robust Semi-supervised Representation Learning from Uncurated Data
Feb 28, 2023
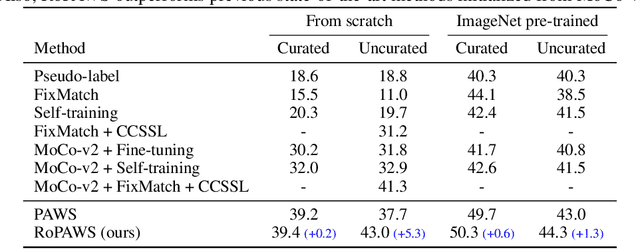
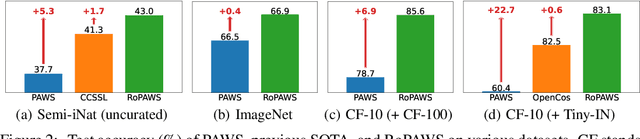

Semi-supervised learning aims to train a model using limited labels. State-of-the-art semi-supervised methods for image classification such as PAWS rely on self-supervised representations learned with large-scale unlabeled but curated data. However, PAWS is often less effective when using real-world unlabeled data that is uncurated, e.g., contains out-of-class data. We propose RoPAWS, a robust extension of PAWS that can work with real-world unlabeled data. We first reinterpret PAWS as a generative classifier that models densities using kernel density estimation. From this probabilistic perspective, we calibrate its prediction based on the densities of labeled and unlabeled data, which leads to a simple closed-form solution from the Bayes' rule. We demonstrate that RoPAWS significantly improves PAWS for uncurated Semi-iNat by +5.3% and curated ImageNet by +0.4%.
Diffusion Probabilistic Models for Graph-Structured Prediction
Feb 23, 2023


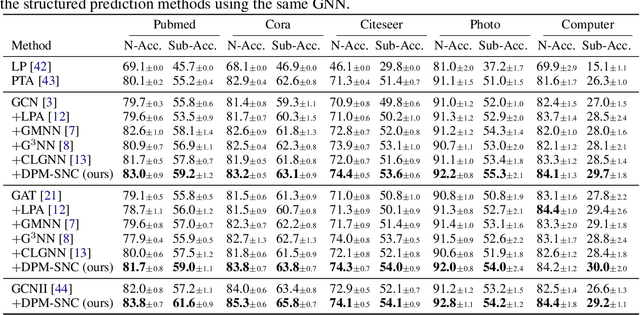
This paper studies graph-structured prediction for supervised learning on graphs with node-wise or edge-wise target dependencies. To solve this problem, recent works investigated combining graph neural networks (GNNs) with conventional structured prediction algorithms like conditional random fields. However, in this work, we pursue an alternative direction building on the recent successes of diffusion probabilistic models (DPMs). That is, we propose a new framework using DPMs to make graph-structured predictions. In the fully supervised setting, our DPM captures the target dependencies by iteratively updating each target estimate based on the estimates of nearby targets. We also propose a variational expectation maximization algorithm to train our DPM in the semi-supervised setting. Extensive experiments verify that our framework consistently outperforms existing neural structured prediction models on inductive and transductive node classification. We also demonstrate the competitive performance of our framework for algorithmic reasoning tasks.