 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Training Large Language Models with Confident Reasoning
May 23, 2025Large language models (LLMs) have shown impressive performance by generating reasoning paths before final answers, but learning such a reasoning path requires costly human supervision. To address this issue, recent studies have explored self-training methods that improve reasoning capabilities using pseudo-labels generated by the LLMs themselves. Among these, confidence-based self-training fine-tunes LLMs to prefer reasoning paths with high-confidence answers, where confidence is estimated via majority voting. However, such methods exclusively focus on the quality of the final answer and may ignore the quality of the reasoning paths, as even an incorrect reasoning path leads to a correct answer by chance. Instead, we advocate the use of reasoning-level confidence to identify high-quality reasoning paths for self-training, supported by our empirical observations. We then propose a new self-training method, CORE-PO, that fine-tunes LLMs to prefer high-COnfidence REasoning paths through Policy Optimization. Our experiments show that CORE-PO improves the accuracy of outputs on four in-distribution and two out-of-distribution benchmarks, compared to existing self-training methods.
Can LLMs Generate Diverse Molecules? Towards Alignment with Structural Diversity
Oct 04, 2024



Recent advancements in large language models (LLMs) have demonstrated impressive performance in generating molecular structures as drug candidates, which offers significant potential to accelerate drug discovery. However, the current LLMs overlook a critical requirement for drug discovery: proposing a diverse set of molecules. This diversity is essential for improving the chances of finding a viable drug, as it provides alternative molecules that may succeed where others fail in wet-lab or clinical validations. Despite such a need for diversity, the LLMs often output structurally similar molecules from a given prompt. While decoding schemes like beam search may enhance textual diversity, this often does not align with molecular structural diversity. In response, we propose a new method for fine-tuning molecular generative LLMs to autoregressively generate a set of structurally diverse molecules, where each molecule is generated by conditioning on the previously generated molecules. Our approach consists of two stages: (1) supervised fine-tuning to adapt LLMs to autoregressively generate molecules in a sequence and (2) reinforcement learning to maximize structural diversity within the generated molecules. Our experiments show that (1) our fine-tuning approach enables the LLMs to better discover diverse molecules compared to existing decoding schemes and (2) our fine-tuned model outperforms other representative LLMs in generating diverse molecules, including the ones fine-tuned on chemical domains.
Pessimistic Backward Policy for GFlowNets
May 25, 2024This paper studies Generative Flow Networks (GFlowNets), which learn to sample objects proportionally to a given reward function through the trajectory of state transitions. In this work, we observe that GFlowNets tend to under-exploit the high-reward objects due to training on insufficient number of trajectories, which may lead to a large gap between the estimated flow and the (known) reward value. In response to this challenge, we propose a pessimistic backward policy for GFlowNets (PBP-GFN), which maximizes the observed flow to align closely with the true reward for the object. We extensively evaluate PBP-GFN across eight benchmarks, including hyper-grid environment, bag generation, structured set generation, molecular generation, and four RNA sequence generation tasks. In particular, PBP-GFN enhances the discovery of high-reward objects, maintains the diversity of the objects, and consistently outperforms existing methods.
Learning Energy Decompositions for Partial Inference of GFlowNets
Oct 05, 2023



This paper studies generative flow networks (GFlowNets) to sample objects from the Boltzmann energy distribution via a sequence of actions. In particular, we focus on improving GFlowNet with partial inference: training flow functions with the evaluation of the intermediate states or transitions. To this end, the recently developed forward-looking GFlowNet reparameterizes the flow functions based on evaluating the energy of intermediate states. However, such an evaluation of intermediate energies may (i) be too expensive or impossible to evaluate and (ii) even provide misleading training signals under large energy fluctuations along the sequence of actions. To resolve this issue, we propose learning energy decompositions for GFlowNets (LED-GFN). Our main idea is to (i) decompose the energy of an object into learnable potential functions defined on state transitions and (ii) reparameterize the flow functions using the potential functions. In particular, to produce informative local credits, we propose to regularize the potential to change smoothly over the sequence of actions. It is also noteworthy that training GFlowNet with our learned potential can preserve the optimal policy. We empirically verify the superiority of LED-GFN in five problems including the generation of unstructured and maximum independent sets, molecular graphs, and RNA sequences.
Diffusion Probabilistic Models for Graph-Structured Prediction
Feb 23, 2023


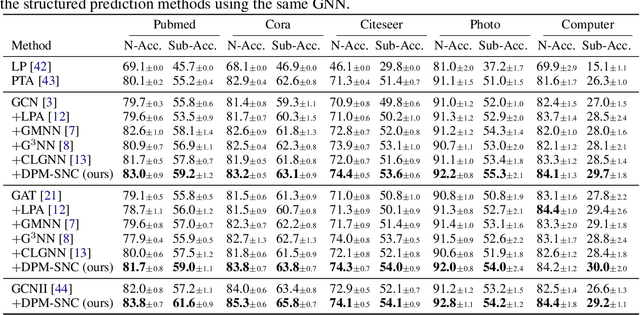
This paper studies graph-structured prediction for supervised learning on graphs with node-wise or edge-wise target dependencies. To solve this problem, recent works investigated combining graph neural networks (GNNs) with conventional structured prediction algorithms like conditional random fields. However, in this work, we pursue an alternative direction building on the recent successes of diffusion probabilistic models (DPMs). That is, we propose a new framework using DPMs to make graph-structured predictions. In the fully supervised setting, our DPM captures the target dependencies by iteratively updating each target estimate based on the estimates of nearby targets. We also propose a variational expectation maximization algorithm to train our DPM in the semi-supervised setting. Extensive experiments verify that our framework consistently outperforms existing neural structured prediction models on inductive and transductive node classification. We also demonstrate the competitive performance of our framework for algorithmic reasoning tasks.