 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINDIBATOR: Diverse and Fact-Grounded Individuality for Multi-Agent Debate in Molecular Discovery
Feb 02, 2026Multi-agent systems have emerged as a powerful paradigm for automating scientific discovery. To differentiate agent behavior in the multi-agent system, current frameworks typically assign generic role-based personas such as ''reviewer'' or ''writer'' or rely on coarse grained keyword-based personas. While functional, this approach oversimplifies how human scientists operate, whose contributions are shaped by their unique research trajectories. In response, we propose INDIBATOR, a framework for molecular discovery that grounds agents in individualized scientist profiles constructed from two modalities: publication history for literature-derived knowledge and molecular history for structural priors. These agents engage in multi-turn debate through proposal, critique, and voting phases. Our evaluation demonstrates that these fine-grained individuality-grounded agents consistently outperform systems relying on coarse-grained personas, achieving competitive or state-of-the-art performance. These results validate that capturing the ``scientific DNA'' of individual agents is essential for high-quality discovery.
MT-Mol:Multi Agent System with Tool-based Reasoning for Molecular Optimization
May 27, 2025Large language models (LLMs) have large potential for molecular optimization, as they can gather external chemistry tools and enable collaborative interactions to iteratively refine molecular candidates. However, this potential remains underexplored, particularly in the context of structured reasoning, interpretability, and comprehensive tool-grounded molecular optimization. To address this gap, we introduce MT-Mol, a multi-agent framework for molecular optimization that leverages tool-guided reasoning and role-specialized LLM agents. Our system incorporates comprehensive RDKit tools, categorized into five distinct domains: structural descriptors, electronic and topological features, fragment-based functional groups, molecular representations, and miscellaneous chemical properties. Each category is managed by an expert analyst agent, responsible for extracting task-relevant tools and enabling interpretable, chemically grounded feedback. MT-Mol produces molecules with tool-aligned and stepwise reasoning through the interaction between the analyst agents, a molecule-generating scientist, a reasoning-output verifier, and a reviewer agent. As a result, we show that our framework shows the state-of-the-art performance of the PMO-1K benchmark on 17 out of 23 tasks.
Self-Training Large Language Models with Confident Reasoning
May 23, 2025Large language models (LLMs) have shown impressive performance by generating reasoning paths before final answers, but learning such a reasoning path requires costly human supervision. To address this issue, recent studies have explored self-training methods that improve reasoning capabilities using pseudo-labels generated by the LLMs themselves. Among these, confidence-based self-training fine-tunes LLMs to prefer reasoning paths with high-confidence answers, where confidence is estimated via majority voting. However, such methods exclusively focus on the quality of the final answer and may ignore the quality of the reasoning paths, as even an incorrect reasoning path leads to a correct answer by chance. Instead, we advocate the use of reasoning-level confidence to identify high-quality reasoning paths for self-training, supported by our empirical observations. We then propose a new self-training method, CORE-PO, that fine-tunes LLMs to prefer high-COnfidence REasoning paths through Policy Optimization. Our experiments show that CORE-PO improves the accuracy of outputs on four in-distribution and two out-of-distribution benchmarks, compared to existing self-training methods.
Improving Chemical Understanding of LLMs via SMILES Parsing
May 22, 2025Large language models (LLMs) are increasingly recognized as powerful tools for scientific discovery, particularly in molecular science. A fundamental requirement for these models is the ability to accurately understand molecular structures, commonly encoded in the SMILES representation. However, current LLMs struggle to interpret SMILES, even failing to carry out basic tasks such as counting molecular rings. To address this limitation, we introduce CLEANMOL, a novel framework that formulates SMILES parsing into a suite of clean and deterministic tasks explicitly designed to promote graph-level molecular comprehension. These tasks span from subgraph matching to global graph matching, providing structured supervision aligned with molecular structural properties. We construct a molecular pretraining dataset with adaptive difficulty scoring and pre-train open-source LLMs on these tasks. Our results show that CLEANMOL not only enhances structural comprehension but also achieves the best or competes with the baseline on the Mol-Instructions benchmark.
Chain-of-Thoughts for Molecular Understanding
Oct 08, 2024



The adaptation of large language models (LLMs) to chemistry has shown promising performance in molecular understanding tasks, such as generating a text description from a molecule. However, proper reasoning based on molecular structural information remains a significant challenge, e.g., even advanced LLMs such as GPT-4o struggle to identify functional groups which are crucial for inferring the molecular property of interest. To address this limitation, we propose StructCoT, a structure-aware chain-of-thought (CoT) that enhances LLMs' understanding of molecular structures by explicitly injecting the key structural features of molecules. Moreover, we introduce two fine-tuning frameworks for adapting the existing LLMs to use our StructCoT. Our experiments demonstrate that incorporating StructCoT with our fine-tuning frameworks leads to consistent improvements in both molecular understanding tasks.
Can LLMs Generate Diverse Molecules? Towards Alignment with Structural Diversity
Oct 04, 2024



Recent advancements in large language models (LLMs) have demonstrated impressive performance in generating molecular structures as drug candidates, which offers significant potential to accelerate drug discovery. However, the current LLMs overlook a critical requirement for drug discovery: proposing a diverse set of molecules. This diversity is essential for improving the chances of finding a viable drug, as it provides alternative molecules that may succeed where others fail in wet-lab or clinical validations. Despite such a need for diversity, the LLMs often output structurally similar molecules from a given prompt. While decoding schemes like beam search may enhance textual diversity, this often does not align with molecular structural diversity. In response, we propose a new method for fine-tuning molecular generative LLMs to autoregressively generate a set of structurally diverse molecules, where each molecule is generated by conditioning on the previously generated molecules. Our approach consists of two stages: (1) supervised fine-tuning to adapt LLMs to autoregressively generate molecules in a sequence and (2) reinforcement learning to maximize structural diversity within the generated molecules. Our experiments show that (1) our fine-tuning approach enables the LLMs to better discover diverse molecules compared to existing decoding schemes and (2) our fine-tuned model outperforms other representative LLMs in generating diverse molecules, including the ones fine-tuned on chemical domains.
Pessimistic Backward Policy for GFlowNets
May 25, 2024This paper studies Generative Flow Networks (GFlowNets), which learn to sample objects proportionally to a given reward function through the trajectory of state transitions. In this work, we observe that GFlowNets tend to under-exploit the high-reward objects due to training on insufficient number of trajectories, which may lead to a large gap between the estimated flow and the (known) reward value. In response to this challenge, we propose a pessimistic backward policy for GFlowNets (PBP-GFN), which maximizes the observed flow to align closely with the true reward for the object. We extensively evaluate PBP-GFN across eight benchmarks, including hyper-grid environment, bag generation, structured set generation, molecular generation, and four RNA sequence generation tasks. In particular, PBP-GFN enhances the discovery of high-reward objects, maintains the diversity of the objects, and consistently outperforms existing methods.
Hybrid Neural Representations for Spherical Data
Feb 05, 2024



In this paper, we study hybrid neural representations for spherical data, a domain of increasing relevance in scientific research. In particular, our work focuses on weather and climate data as well as comic microwave background (CMB) data. Although previous studies have delved into coordinate-based neural representations for spherical signals, they often fail to capture the intricate details of highly nonlinear signals. To address this limitation, we introduce a novel approach named Hybrid Neural Representations for Spherical data (HNeR-S). Our main idea is to use spherical feature-grids to obtain positional features which are combined with a multilayer perception to predict the target signal. We consider feature-grids with equirectangular and hierarchical equal area isolatitude pixelization structures that align with weather data and CMB data, respectively. We extensively verify the effectiveness of our HNeR-S for regression, super-resolution, temporal interpolation, and compression tasks.
A Simple and Scalable Representation for Graph Generation
Dec 04, 2023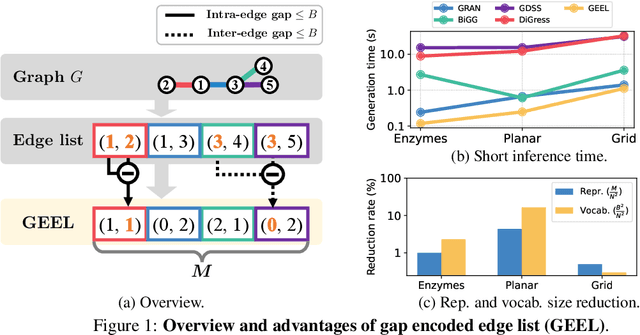
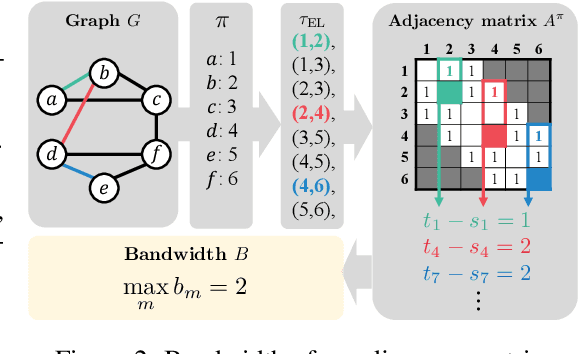
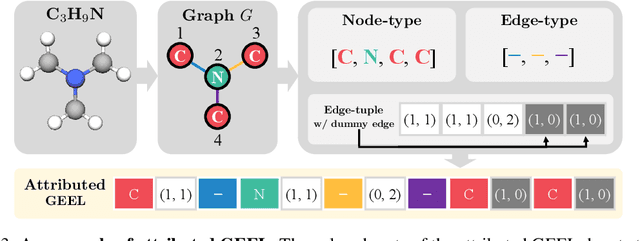
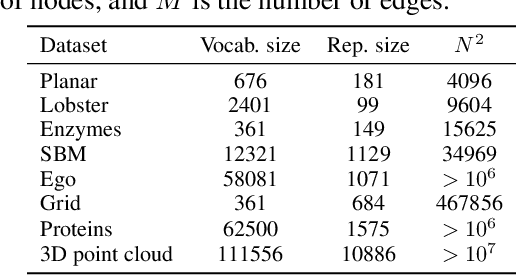
Recently, there has been a surge of interest in employing neural networks for graph generation, a fundamental statistical learning problem with critical applications like molecule design and community analysis. However, most approaches encounter significant limitations when generating large-scale graphs. This is due to their requirement to output the full adjacency matrices whose size grows quadratically with the number of nodes. In response to this challenge, we introduce a new, simple, and scalable graph representation named gap encoded edge list (GEEL) that has a small representation size that aligns with the number of edges. In addition, GEEL significantly reduces the vocabulary size by incorporating the gap encoding and bandwidth restriction schemes. GEEL can be autoregressively generated with the incorporation of node positional encoding, and we further extend GEEL to deal with attributed graphs by designing a new grammar. Our findings reveal that the adoption of this compact representation not only enhances scalability but also bolsters performance by simplifying the graph generation process. We conduct a comprehensive evaluation across ten non-attributed and two molecular graph generation tasks, demonstrating the effectiveness of GEEL.
Hierarchical Graph Generation with $K^2$-trees
Jun 01, 2023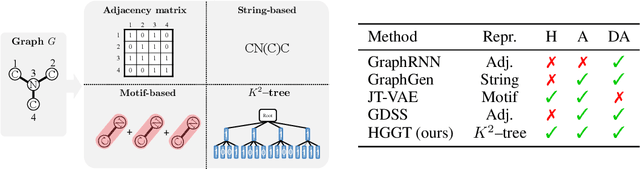
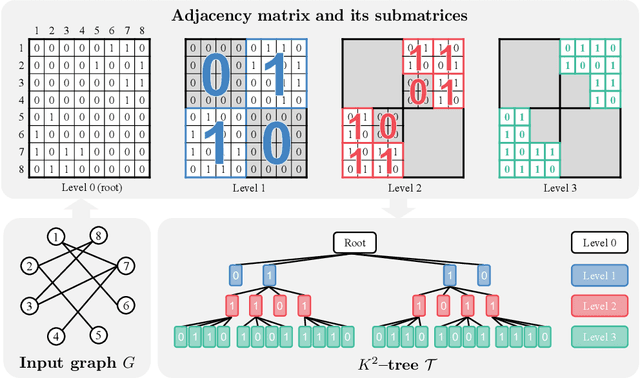
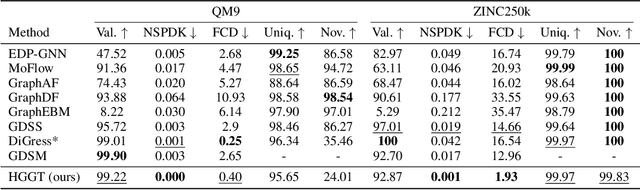
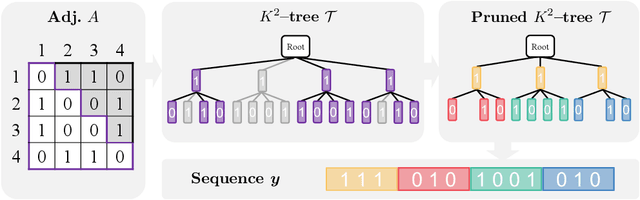
Generating graphs from a target distribution is a significant challenge across many domains, including drug discovery and social network analysis. In this work, we introduce a novel graph generation method leveraging $K^2$-tree representation which was originally designed for lossless graph compression. Our motivation stems from the ability of the $K^2$-trees to enable compact generation while concurrently capturing the inherent hierarchical structure of a graph. In addition, we make further contributions by (1) presenting a sequential $K^2$-tree representation that incorporates pruning, flattening, and tokenization processes and (2) introducing a Transformer-based architecture designed to generate the sequence by incorporating a specialized tree positional encoding scheme. Finally, we extensively evaluate our algorithm on four general and two molecular graph datasets to confirm its superiority for graph generation.