 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentRVOS: Reasoning over Object Tracks for Zero-Shot Referring Video Object Segmentation
Mar 24, 2026Referring Video Object Segmentation (RVOS) aims to segment a target object throughout a video given a natural language query. Training-free methods for this task follow a common pipeline: a MLLM selects keyframes, grounds the referred object within those frames, and a video segmentation model propagates the results. While intuitive, this design asks the MLLM to make temporal decisions before any object-level evidence is available, limiting both reasoning quality and spatio-temporal coverage. To overcome this, we propose AgentRVOS, a training-free agentic pipeline built on the complementary strengths of SAM3 and a MLLM. Given a concept derived from the query, SAM3 provides reliable perception over the full spatio-temporal extent through generated mask tracks. The MLLM then identifies the target through query-grounded reasoning over this object-level evidence, iteratively pruning guided by SAM3's temporal existence information. Extensive experiments show that AgentRVOS achieves state-of-the-art performance among training-free methods across multiple benchmarks, with consistent results across diverse MLLM backbones. Our project page is available at: https://cvlab-kaist.github.io/AgentRVOS/.
Decoder-Free Distillation for Quantized Image Restoration
Mar 10, 2026Quantization-Aware Training (QAT), combined with Knowledge Distillation (KD), holds immense promise for compressing models for edge deployment. However, joint optimization for precision-sensitive image restoration (IR) to recover visual quality from degraded images remains largely underexplored. Directly adapting QAT-KD to low-level vision reveals three critical bottlenecks: teacher-student capacity mismatch, spatial error amplification during decoder distillation, and an optimization "tug-of-war" between reconstruction and distillation losses caused by quantization noise. To tackle these, we introduce Quantization-aware Distilled Restoration (QDR), a framework for edge-deployed IR. QDR eliminates capacity mismatch via FP32 self-distillation and prevents error amplification through Decoder-Free Distillation (DFD), which corrects quantization errors strictly at the network bottleneck. To stabilize the optimization tug-of-war, we propose a Learnable Magnitude Reweighting (LMR) that dynamically balances competing gradients. Finally, we design an Edge-Friendly Model (EFM) featuring a lightweight Learnable Degradation Gating (LDG) to dynamically modulate spatial degradation localization. Extensive experiments across four IR tasks demonstrate that our Int8 model recovers 96.5% of FP32 performance, achieves 442 frames per second (FPS) on an NVIDIA Jetson Orin, and boosts downstream object detection by 16.3 mAP
Memory-Efficient Structured Backpropagation for On-Device LLM Fine-Tuning
Feb 13, 2026On-device fine-tuning enables privacy-preserving personalization of large language models, but mobile devices impose severe memory constraints, typically 6--12GB shared across all workloads. Existing approaches force a trade-off between exact gradients with high memory (MeBP) and low memory with noisy estimates (MeZO). We propose Memory-efficient Structured Backpropagation (MeSP), which bridges this gap by manually deriving backward passes that exploit LoRA's low-rank structure. Our key insight is that the intermediate projection $h = xA$ can be recomputed during backward at minimal cost since rank $r \ll d_{in}$, eliminating the need to store it. MeSP achieves 49\% average memory reduction compared to MeBP on Qwen2.5 models (0.5B--3B) while computing mathematically identical gradients. Our analysis also reveals that MeZO's gradient estimates show near-zero correlation with true gradients (cosine similarity $\approx$0.001), explaining its slow convergence. MeSP reduces peak memory from 361MB to 136MB for Qwen2.5-0.5B, enabling fine-tuning scenarios previously infeasible on memory-constrained devices.
Beware of the Batch Size: Hyperparameter Bias in Evaluating LoRA
Feb 10, 2026Low-rank adaptation (LoRA) is a standard approach for fine-tuning large language models, yet its many variants report conflicting empirical gains, often on the same benchmarks. We show that these contradictions arise from a single overlooked factor: the batch size. When properly tuned, vanilla LoRA often matches the performance of more complex variants. We further propose a proxy-based, cost-efficient strategy for batch size tuning, revealing the impact of rank, dataset size, and model capacity on the optimal batch size. Our findings elevate batch size from a minor implementation detail to a first-order design parameter, reconciling prior inconsistencies and enabling more reliable evaluations of LoRA variants.
Over-Alignment vs Over-Fitting: The Role of Feature Learning Strength in Generalization
Jan 31, 2026Feature learning strength (FLS), i.e., the inverse of the effective output scaling of a model, plays a critical role in shaping the optimization dynamics of neural nets. While its impact has been extensively studied under the asymptotic regimes -- both in training time and FLS -- existing theory offers limited insight into how FLS affects generalization in practical settings, such as when training is stopped upon reaching a target training risk. In this work, we investigate the impact of FLS on generalization in deep networks under such practical conditions. Through empirical studies, we first uncover the emergence of an $\textit{optimal FLS}$ -- neither too small nor too large -- that yields substantial generalization gains. This finding runs counter to the prevailing intuition that stronger feature learning universally improves generalization. To explain this phenomenon, we develop a theoretical analysis of gradient flow dynamics in two-layer ReLU nets trained with logistic loss, where FLS is controlled via initialization scale. Our main theoretical result establishes the existence of an optimal FLS arising from a trade-off between two competing effects: An excessively large FLS induces an $\textit{over-alignment}$ phenomenon that degrades generalization, while an overly small FLS leads to $\textit{over-fitting}$.
Lost in the Prompt Order: Revealing the Limitations of Causal Attention in Language Models
Jan 20, 2026Large language models exhibit surprising sensitivity to the structure of the prompt, but the mechanisms underlying this sensitivity remain poorly understood. In this work, we conduct an in-depth investigation on a striking case: in multiple-choice question answering, placing context before the questions and options (CQO) outperforms the reverse order (QOC) by over 14%p, consistently over a wide range of models and datasets. Through systematic architectural analysis, we identify causal attention as the core mechanism: in QOC prompts, the causal mask prevents option tokens from attending to context, creating an information bottleneck where context becomes invisible to options.
MATRIX: Mask Track Alignment for Interaction-aware Video Generation
Oct 08, 2025



Video DiTs have advanced video generation, yet they still struggle to model multi-instance or subject-object interactions. This raises a key question: How do these models internally represent interactions? To answer this, we curate MATRIX-11K, a video dataset with interaction-aware captions and multi-instance mask tracks. Using this dataset, we conduct a systematic analysis that formalizes two perspectives of video DiTs: semantic grounding, via video-to-text attention, which evaluates whether noun and verb tokens capture instances and their relations; and semantic propagation, via video-to-video attention, which assesses whether instance bindings persist across frames. We find both effects concentrate in a small subset of interaction-dominant layers. Motivated by this, we introduce MATRIX, a simple and effective regularization that aligns attention in specific layers of video DiTs with multi-instance mask tracks from the MATRIX-11K dataset, enhancing both grounding and propagation. We further propose InterGenEval, an evaluation protocol for interaction-aware video generation. In experiments, MATRIX improves both interaction fidelity and semantic alignment while reducing drift and hallucination. Extensive ablations validate our design choices. Codes and weights will be released.
Post-training quantization of vision encoders needs prefixing registers
Oct 06, 2025



Transformer-based vision encoders -- such as CLIP -- are central to multimodal intelligence, powering applications from autonomous web agents to robotic control. Since these applications often demand real-time processing of massive visual data, reducing the inference cost of vision encoders is critical. Post-training quantization offers a practical path, but remains challenging even at 8-bit precision due to massive-scale activations (i.e., outliers). In this work, we propose $\textit{RegCache}$, a training-free algorithm to mitigate outliers in vision encoders, enabling quantization with significantly smaller accuracy drops. The proposed RegCache introduces outlier-prone yet semantically meaningless prefix tokens to the target vision encoder, which prevents other tokens from having outliers. Notably, we observe that outliers in vision encoders behave differently from those in language models, motivating two technical innovations: middle-layer prefixing and token deletion. Experiments show that our method consistently improves the accuracy of quantized models across both text-supervised and self-supervised vision encoders.
Next-Depth Lookahead Tree
Sep 18, 2025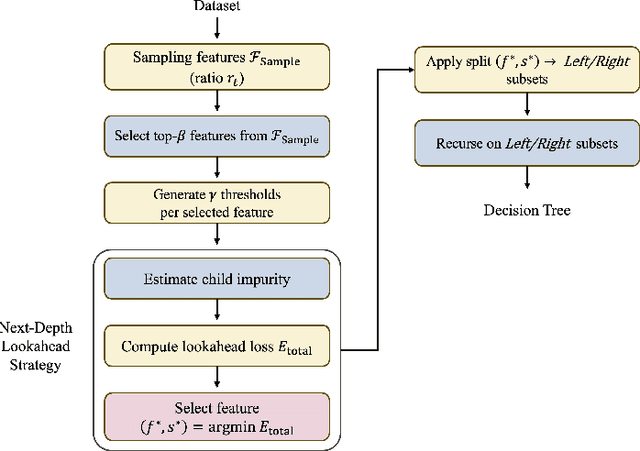
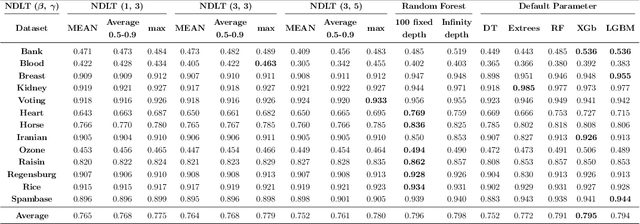
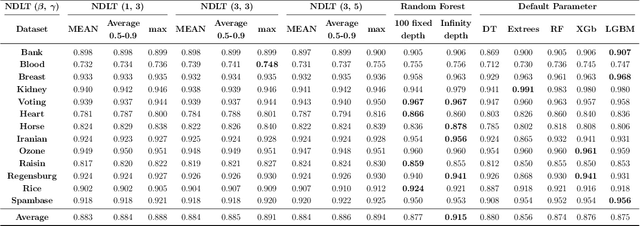
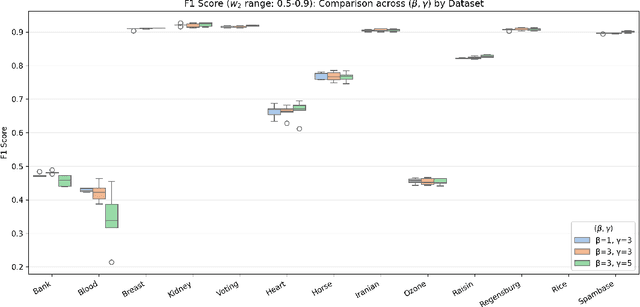
This paper proposes the Next-Depth Lookahead Tree (NDLT), a single-tree model designed to improve performance by evaluating node splits not only at the node being optimized but also by evaluating the quality of the next depth level.
Riemannian Optimization for LoRA on the Stiefel Manifold
Aug 25, 2025While powerful, large language models (LLMs) present significant fine-tuning challenges due to their size. Parameter-efficient fine-tuning (PEFT) methods like LoRA provide solutions, yet suffer from critical optimizer inefficiencies; notably basis redundancy in LoRA's $B$ matrix when using AdamW, which fundamentally limits performance. We address this by optimizing the $B$ matrix on the Stiefel manifold, imposing explicit orthogonality constraints that achieve near-perfect orthogonality and full effective rank. This geometric approach dramatically enhances parameter efficiency and representational capacity. Our Stiefel optimizer consistently outperforms AdamW across benchmarks with both LoRA and DoRA, demonstrating that geometric constraints are the key to unlocking LoRA's full potential for effective LLM fine-tuning.