 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Internal Representations of Graph Metanetworks
Paper and Code
Mar 12, 2025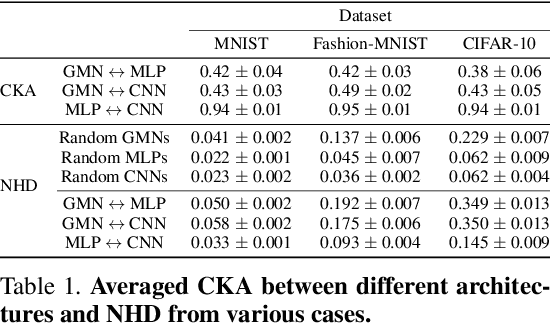
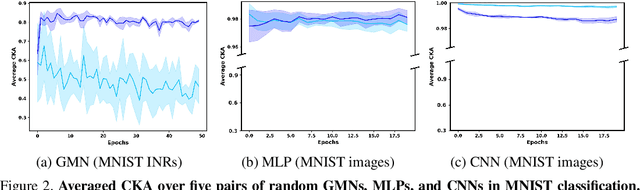
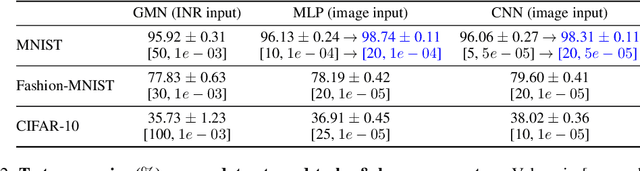
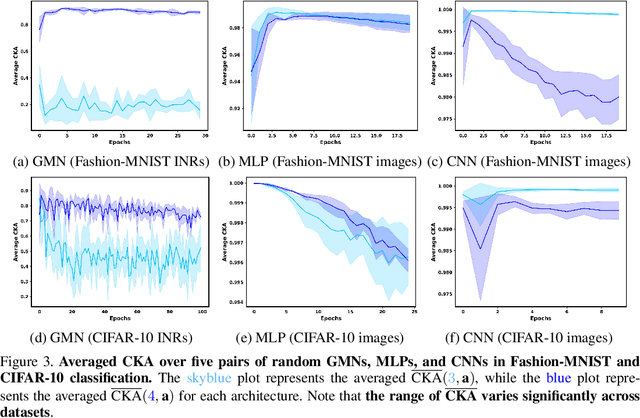
Weight space learning is an emerging paradigm in the deep learning community. The primary goal of weight space learning is to extract informative features from a set of parameters using specially designed neural networks, often referred to as \emph{metanetworks}. However, it remains unclear how these metanetworks learn solely from parameters. To address this, we take the first step toward understanding \emph{representations} of metanetworks, specifically graph metanetworks (GMNs), which achieve state-of-the-art results in this field, using centered kernel alignment (CKA). Through various experiments, we reveal that GMNs and general neural networks (\textit{e.g.,} multi-layer perceptrons (MLPs) and convolutional neural networks (CNNs)) differ in terms of their representation space.