 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Federated Learning for Noise-Robust Training
Jan 08, 2026Federated learning (FL) and federated distillation (FD) are distributed learning paradigms that train UE models with enhanced privacy, each offering different trade-offs between noise robustness and learning speed. To mitigate their respective weaknesses, we propose a hybrid federated learning (HFL) framework in which each user equipment (UE) transmits either gradients or logits, and the base station (BS) selects the per-round weights of FL and FD updates. We derive convergence of HFL framework and introduce two methods to exploit degrees of freedom (DoF) in HFL, which are (i) adaptive UE clustering via Jenks optimization and (ii) adaptive weight selection via a damped Newton method. Numerical results show that HFL achieves superior test accuracy at low SNR when both DoF are exploited.
ZIP: An Efficient Zeroth-order Prompt Tuning for Black-box Vision-Language Models
Apr 09, 2025


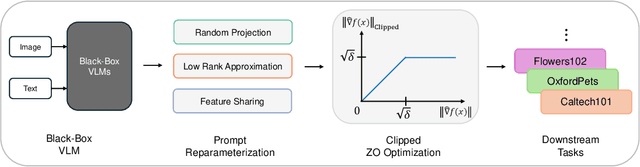
Recent studies have introduced various approaches for prompt-tuning black-box vision-language models, referred to as black-box prompt-tuning (BBPT). While BBPT has demonstrated considerable potential, it is often found that many existing methods require an excessive number of queries (i.e., function evaluations), which poses a significant challenge in real-world scenarios where the number of allowed queries is limited. To tackle this issue, we propose Zeroth-order Intrinsic-dimensional Prompt-tuning (ZIP), a novel approach that enables efficient and robust prompt optimization in a purely black-box setting. The key idea of ZIP is to reduce the problem dimensionality and the variance of zeroth-order gradient estimates, such that the training is done fast with far less queries. We achieve this by re-parameterizing prompts in low-rank representations and designing intrinsic-dimensional clipping of estimated gradients. We evaluate ZIP on 13+ vision-language tasks in standard benchmarks and show that it achieves an average improvement of approximately 6% in few-shot accuracy and 48% in query efficiency compared to the best-performing alternative BBPT methods, establishing a new state of the art. Our ablation analysis further shows that the proposed clipping mechanism is robust and nearly optimal, without the need to manually select the clipping threshold, matching the result of expensive hyperparameter search.
Knowledge Distillation from Language-Oriented to Emergent Communication for Multi-Agent Remote Control
Jan 23, 2024



In this work, we compare emergent communication (EC) built upon multi-agent deep reinforcement learning (MADRL) and language-oriented semantic communication (LSC) empowered by a pre-trained large language model (LLM) using human language. In a multi-agent remote navigation task, with multimodal input data comprising location and channel maps, it is shown that EC incurs high training cost and struggles when using multimodal data, whereas LSC yields high inference computing cost due to the LLM's large size. To address their respective bottlenecks, we propose a novel framework of language-guided EC (LEC) by guiding the EC training using LSC via knowledge distillation (KD). Simulations corroborate that LEC achieves faster travel time while avoiding areas with poor channel conditions, as well as speeding up the MADRL training convergence by up to 61.8% compared to EC.