 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation from Language-Oriented to Emergent Communication for Multi-Agent Remote Control
Jan 23, 2024



In this work, we compare emergent communication (EC) built upon multi-agent deep reinforcement learning (MADRL) and language-oriented semantic communication (LSC) empowered by a pre-trained large language model (LLM) using human language. In a multi-agent remote navigation task, with multimodal input data comprising location and channel maps, it is shown that EC incurs high training cost and struggles when using multimodal data, whereas LSC yields high inference computing cost due to the LLM's large size. To address their respective bottlenecks, we propose a novel framework of language-guided EC (LEC) by guiding the EC training using LSC via knowledge distillation (KD). Simulations corroborate that LEC achieves faster travel time while avoiding areas with poor channel conditions, as well as speeding up the MADRL training convergence by up to 61.8% compared to EC.
Towards Semantic Communication Protocols: A Probabilistic Logic Perspective
Jul 08, 2022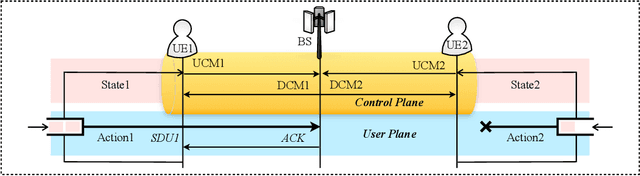
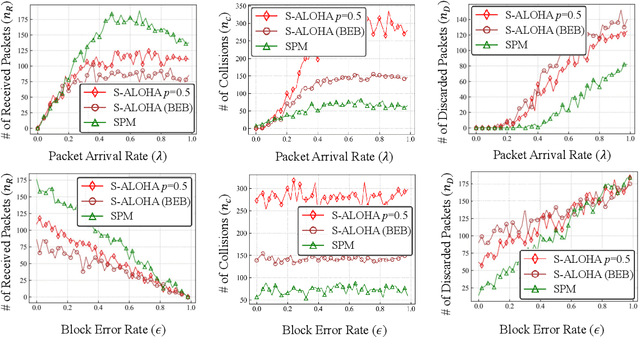
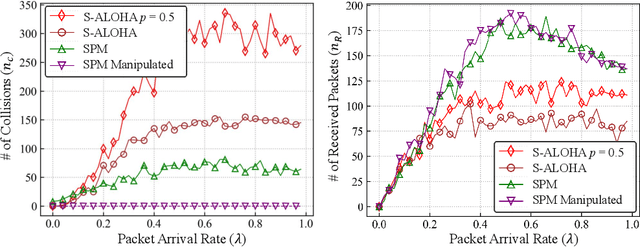
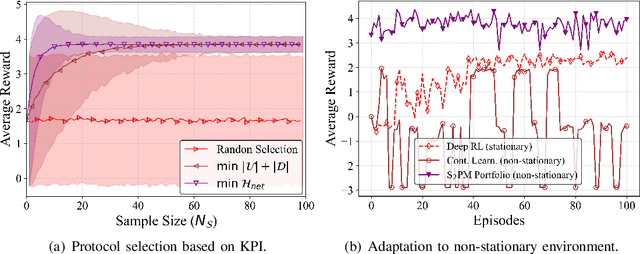
Classical medium access control (MAC) protocols are interpretable, yet their task-agnostic control signaling messages (CMs) are ill-suited for emerging mission-critical applications. By contrast, neural network (NN) based protocol models (NPMs) learn to generate task-specific CMs, but their rationale and impact lack interpretability. To fill this void, in this article we propose, for the first time, a semantic protocol model (SPM) constructed by transforming an NPM into an interpretable symbolic graph written in the probabilistic logic programming language (ProbLog). This transformation is viable by extracting and merging common CMs and their connections while treating the NPM as a CM generator. By extensive simulations, we corroborate that the SPM tightly approximates its original NPM while occupying only 0.02% memory. By leveraging its interpretability and memory-efficiency, we demonstrate several SPM-enabled applications such as SPM reconfiguration for collision-avoidance, as well as comparing different SPMs via semantic entropy calculation and storing multiple SPMs to cope with non-stationary environments.
Communication-Efficient and Personalized Federated Lottery Ticket Learning
Apr 26, 2021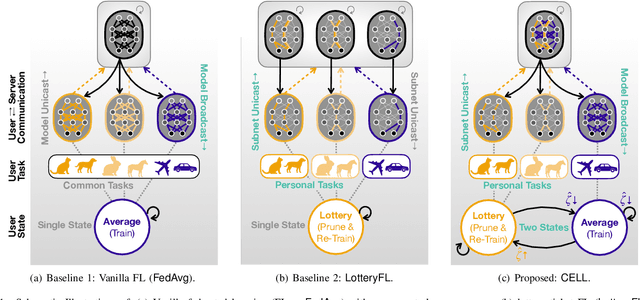

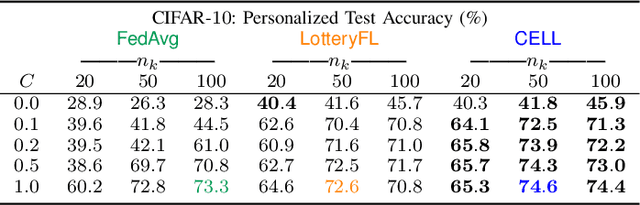
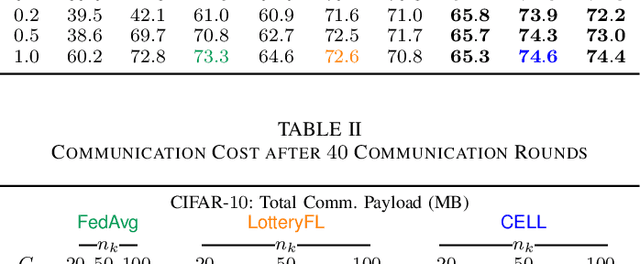
The lottery ticket hypothesis (LTH) claims that a deep neural network (i.e., ground network) contains a number of subnetworks (i.e., winning tickets), each of which exhibiting identically accurate inference capability as that of the ground network. Federated learning (FL) has recently been applied in LotteryFL to discover such winning tickets in a distributed way, showing higher accuracy multi-task learning than Vanilla FL. Nonetheless, LotteryFL relies on unicast transmission on the downlink, and ignores mitigating stragglers, questioning scalability. Motivated by this, in this article we propose a personalized and communication-efficient federated lottery ticket learning algorithm, coined CELL, which exploits downlink broadcast for communication efficiency. Furthermore, it utilizes a novel user grouping method, thereby alternating between FL and lottery learning to mitigate stragglers. Numerical simulations validate that CELL achieves up to 3.6% higher personalized task classification accuracy with 4.3x smaller total communication cost until convergence under the CIFAR-10 dataset.