 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-Efficient Wireless LLM Inference via Uncertainty and Importance-Aware Speculative Decoding
Aug 18, 2025To address the growing demand for on-device LLM inference in resource-constrained environments, hybrid language models (HLM) have emerged, combining lightweight local models with powerful cloud-based LLMs. Recent studies on HLM have primarily focused on improving accuracy and latency, while often overlooking communication and energy efficiency. We propose a token-level filtering mechanism for an energy-efficient importance- and uncertainty-aware HLM inference that leverages both epistemic uncertainty and attention-based importance. Our method opportunistically uploads only informative tokens, reducing LLM usage and communication costs. Experiments with TinyLlama-1.1B and LLaMA-2-7B demonstrate that our method achieves up to 87.5% BERT Score and token throughput of 0.37 tokens/sec while saving the energy consumption by 40.7% compared to standard HLM. Furthermore, compared to our previous U-HLM baseline, our method improves BERTScore from 85.8% to 87.0%, energy savings from 31.6% to 43.6%, and throughput from 0.36 to 0.40. This approach enables an energy-efficient and accurate deployment of LLMs in bandwidth-constrained edge environments.
Hybrid Semantic-Complementary Transmission for High-Fidelity Image Reconstruction
Jul 23, 2025Recent advances in semantic communication (SC) have introduced neural network (NN)-based transceivers that convey semantic representation (SR) of signals such as images. However, these NNs are trained over diverse image distributions and thus often fail to reconstruct fine-grained image-specific details. To overcome this limited reconstruction fidelity, we propose an extended SC framework, hybrid semantic communication (HSC), which supplements SR with complementary representation (CR) capturing residual image-specific information. The CR is constructed at the transmitter, and is combined with the actual SC outcome at the receiver to yield a high-fidelity recomposed image. While the transmission load of SR is fixed due to its NN-based structure, the load of CR can be flexibly adjusted to achieve a desirable fidelity. This controllability directly influences the final reconstruction error, for which we derive a closed-form expression and the corresponding optimal CR. Simulation results demonstrate that HSC substantially reduces MSE compared to the baseline SC without CR transmission across various channels and NN architectures.
Communication-Efficient Hybrid Language Model via Uncertainty-Aware Opportunistic and Compressed Transmission
May 17, 2025To support emerging language-based applications using dispersed and heterogeneous computing resources, the hybrid language model (HLM) offers a promising architecture, where an on-device small language model (SLM) generates draft tokens that are validated and corrected by a remote large language model (LLM). However, the original HLM suffers from substantial communication overhead, as the LLM requires the SLM to upload the full vocabulary distribution for each token. Moreover, both communication and computation resources are wasted when the LLM validates tokens that are highly likely to be accepted. To overcome these limitations, we propose communication-efficient and uncertainty-aware HLM (CU-HLM). In CU-HLM, the SLM transmits truncated vocabulary distributions only when its output uncertainty is high. We validate the feasibility of this opportunistic transmission by discovering a strong correlation between SLM's uncertainty and LLM's rejection probability. Furthermore, we theoretically derive optimal uncertainty thresholds and optimal vocabulary truncation strategies. Simulation results show that, compared to standard HLM, CU-HLM achieves up to 206$\times$ higher token throughput by skipping 74.8% transmissions with 97.4% vocabulary compression, while maintaining 97.4% accuracy.
Uncertainty-Aware Hybrid Inference with On-Device Small and Remote Large Language Models
Dec 17, 2024



This paper studies a hybrid language model (HLM) architecture that integrates a small language model (SLM) operating on a mobile device with a large language model (LLM) hosted at the base station (BS) of a wireless network. The HLM token generation process follows the speculative inference principle: the SLM's vocabulary distribution is uploaded to the LLM, which either accepts or rejects it, with rejected tokens being resampled by the LLM. While this approach ensures alignment between the vocabulary distributions of the SLM and LLM, it suffers from low token throughput due to uplink transmission and the computation costs of running both language models. To address this, we propose a novel HLM structure coined Uncertainty-aware HLM (U-HLM), wherein the SLM locally measures its output uncertainty, and skips both uplink transmissions and LLM operations for tokens that are likely to be accepted. This opportunistic skipping is enabled by our empirical finding of a linear correlation between the SLM's uncertainty and the LLM's rejection probability. We analytically derive the uncertainty threshold and evaluate its expected risk of rejection. Simulations show that U-HLM reduces uplink transmissions and LLM computation by 45.93%, while achieving up to 97.54% of the LLM's inference accuracy and 2.54$\times$ faster token throughput than HLM without skipping.
Privacy-Preserving Split Learning with Vision Transformers using Patch-Wise Random and Noisy CutMix
Aug 02, 2024



In computer vision, the vision transformer (ViT) has increasingly superseded the convolutional neural network (CNN) for improved accuracy and robustness. However, ViT's large model sizes and high sample complexity make it difficult to train on resource-constrained edge devices. Split learning (SL) emerges as a viable solution, leveraging server-side resources to train ViTs while utilizing private data from distributed devices. However, SL requires additional information exchange for weight updates between the device and the server, which can be exposed to various attacks on private training data. To mitigate the risk of data breaches in classification tasks, inspired from the CutMix regularization, we propose a novel privacy-preserving SL framework that injects Gaussian noise into smashed data and mixes randomly chosen patches of smashed data across clients, coined DP-CutMixSL. Our analysis demonstrates that DP-CutMixSL is a differentially private (DP) mechanism that strengthens privacy protection against membership inference attacks during forward propagation. Through simulations, we show that DP-CutMixSL improves privacy protection against membership inference attacks, reconstruction attacks, and label inference attacks, while also improving accuracy compared to DP-SL and DP-MixSL.
Energy-Efficient Edge Learning via Joint Data Deepening-and-Prefetching
Feb 19, 2024The vision of pervasive artificial intelligence (AI) services can be realized by training an AI model on time using real-time data collected by internet of things (IoT) devices. To this end, IoT devices require offloading their data to an edge server in proximity. However, transmitting high-dimensional and voluminous data from energy-constrained IoT devices poses a significant challenge. To address this limitation, we propose a novel offloading architecture, called joint data deepening-and-prefetching (JD2P), which is feature-by-feature offloading comprising two key techniques. The first one is data deepening, where each data sample's features are sequentially offloaded in the order of importance determined by the data embedding technique such as principle component analysis (PCA). Offloading is terminated once the already transmitted features are sufficient for accurate data classification, resulting in a reduction in the amount of transmitted data. The criteria to offload data are derived for binary and multi-class classifiers, which are designed based on support vector machine (SVM) and deep neural network (DNN), respectively. The second one is data prefetching, where some features potentially required in the future are offloaded in advance, thus achieving high efficiency via precise prediction and parameter optimization. We evaluate the effectiveness of JD2P through experiments using the MNIST dataset, and the results demonstrate its significant reduction in expected energy consumption compared to several benchmarks without degrading learning accuracy.
Knowledge Distillation from Language-Oriented to Emergent Communication for Multi-Agent Remote Control
Jan 23, 2024



In this work, we compare emergent communication (EC) built upon multi-agent deep reinforcement learning (MADRL) and language-oriented semantic communication (LSC) empowered by a pre-trained large language model (LLM) using human language. In a multi-agent remote navigation task, with multimodal input data comprising location and channel maps, it is shown that EC incurs high training cost and struggles when using multimodal data, whereas LSC yields high inference computing cost due to the LLM's large size. To address their respective bottlenecks, we propose a novel framework of language-guided EC (LEC) by guiding the EC training using LSC via knowledge distillation (KD). Simulations corroborate that LEC achieves faster travel time while avoiding areas with poor channel conditions, as well as speeding up the MADRL training convergence by up to 61.8% compared to EC.
Generative AI Meets Semantic Communication: Evolution and Revolution of Communication Tasks
Jan 10, 2024While deep generative models are showing exciting abilities in computer vision and natural language processing, their adoption in communication frameworks is still far underestimated. These methods are demonstrated to evolve solutions to classic communication problems such as denoising, restoration, or compression. Nevertheless, generative models can unveil their real potential in semantic communication frameworks, in which the receiver is not asked to recover the sequence of bits used to encode the transmitted (semantic) message, but only to regenerate content that is semantically consistent with the transmitted message. Disclosing generative models capabilities in semantic communication paves the way for a paradigm shift with respect to conventional communication systems, which has great potential to reduce the amount of data traffic and offers a revolutionary versatility to novel tasks and applications that were not even conceivable a few years ago. In this paper, we present a unified perspective of deep generative models in semantic communication and we unveil their revolutionary role in future communication frameworks, enabling emerging applications and tasks. Finally, we analyze the challenges and opportunities to face to develop generative models specifically tailored for communication systems.
Mobility-Induced Graph Learning for WiFi Positioning
Nov 14, 2023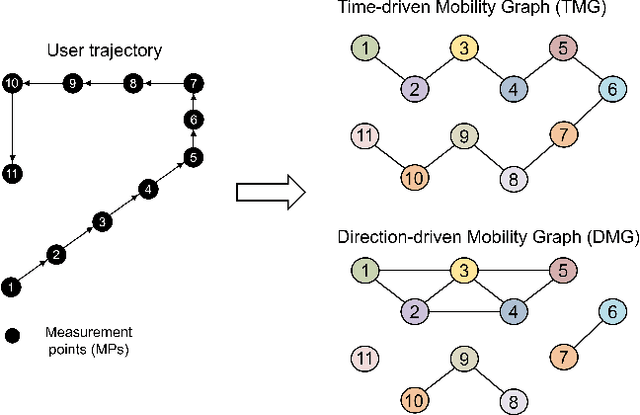

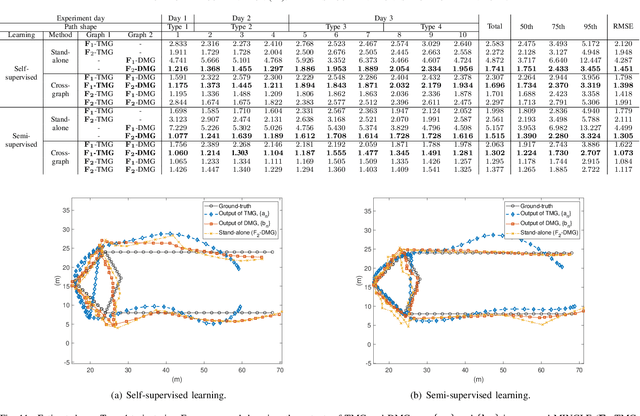
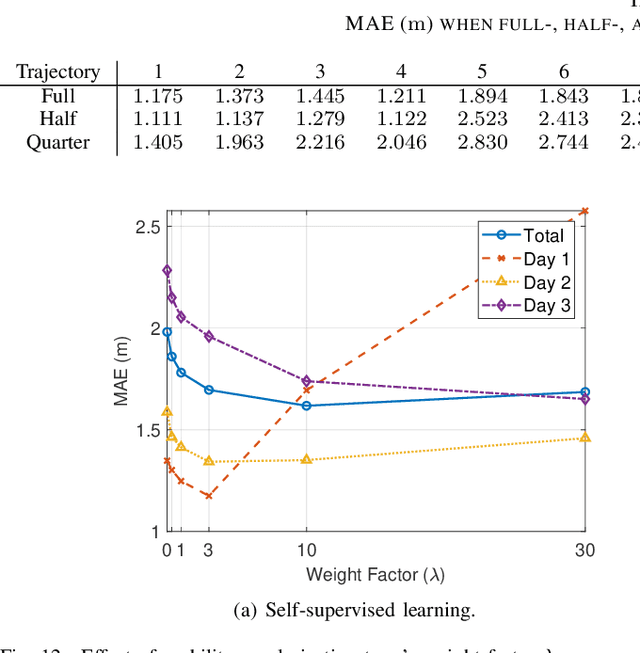
A smartphone-based user mobility tracking could be effective in finding his/her location, while the unpredictable error therein due to low specification of built-in inertial measurement units (IMUs) rejects its standalone usage but demands the integration to another positioning technique like WiFi positioning. This paper aims to propose a novel integration technique using a graph neural network called Mobility-INduced Graph LEarning (MINGLE), which is designed based on two types of graphs made by capturing different user mobility features. Specifically, considering sequential measurement points (MPs) as nodes, a user's regular mobility pattern allows us to connect neighbor MPs as edges, called time-driven mobility graph (TMG). Second, a user's relatively straight transition at a constant pace when moving from one position to another can be captured by connecting the nodes on each path, called a direction-driven mobility graph (DMG). Then, we can design graph convolution network (GCN)-based cross-graph learning, where two different GCN models for TMG and DMG are jointly trained by feeding different input features created by WiFi RTTs yet sharing their weights. Besides, the loss function includes a mobility regularization term such that the differences between adjacent location estimates should be less variant due to the user's stable moving pace. Noting that the regularization term does not require ground-truth location, MINGLE can be designed under semi- and self-supervised learning frameworks. The proposed MINGLE's effectiveness is extensively verified through field experiments, showing a better positioning accuracy than benchmarks, say root mean square errors (RMSEs) being 1.398 (m) and 1.073 (m) for self- and semi-supervised learning cases, respectively.
Towards Semantic Communication Protocols for 6G: From Protocol Learning to Language-Oriented Approaches
Oct 14, 2023



The forthcoming 6G systems are expected to address a wide range of non-stationary tasks. This poses challenges to traditional medium access control (MAC) protocols that are static and predefined. In response, data-driven MAC protocols have recently emerged, offering ability to tailor their signaling messages for specific tasks. This article presents a novel categorization of these data-driven MAC protocols into three levels: Level 1 MAC. task-oriented neural protocols constructed using multi-agent deep reinforcement learning (MADRL); Level 2 MAC. neural network-oriented symbolic protocols developed by converting Level 1 MAC outputs into explicit symbols; and Level 3 MAC. language-oriented semantic protocols harnessing large language models (LLMs) and generative models. With this categorization, we aim to explore the opportunities and challenges of each level by delving into their foundational techniques. Drawing from information theory and associated principles as well as selected case studies, this study provides insights into the trajectory of data-driven MAC protocols and sheds light on future research directions.