 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-Efficient Wireless LLM Inference via Uncertainty and Importance-Aware Speculative Decoding
Aug 18, 2025To address the growing demand for on-device LLM inference in resource-constrained environments, hybrid language models (HLM) have emerged, combining lightweight local models with powerful cloud-based LLMs. Recent studies on HLM have primarily focused on improving accuracy and latency, while often overlooking communication and energy efficiency. We propose a token-level filtering mechanism for an energy-efficient importance- and uncertainty-aware HLM inference that leverages both epistemic uncertainty and attention-based importance. Our method opportunistically uploads only informative tokens, reducing LLM usage and communication costs. Experiments with TinyLlama-1.1B and LLaMA-2-7B demonstrate that our method achieves up to 87.5% BERT Score and token throughput of 0.37 tokens/sec while saving the energy consumption by 40.7% compared to standard HLM. Furthermore, compared to our previous U-HLM baseline, our method improves BERTScore from 85.8% to 87.0%, energy savings from 31.6% to 43.6%, and throughput from 0.36 to 0.40. This approach enables an energy-efficient and accurate deployment of LLMs in bandwidth-constrained edge environments.
Communication-Efficient Hybrid Language Model via Uncertainty-Aware Opportunistic and Compressed Transmission
May 17, 2025To support emerging language-based applications using dispersed and heterogeneous computing resources, the hybrid language model (HLM) offers a promising architecture, where an on-device small language model (SLM) generates draft tokens that are validated and corrected by a remote large language model (LLM). However, the original HLM suffers from substantial communication overhead, as the LLM requires the SLM to upload the full vocabulary distribution for each token. Moreover, both communication and computation resources are wasted when the LLM validates tokens that are highly likely to be accepted. To overcome these limitations, we propose communication-efficient and uncertainty-aware HLM (CU-HLM). In CU-HLM, the SLM transmits truncated vocabulary distributions only when its output uncertainty is high. We validate the feasibility of this opportunistic transmission by discovering a strong correlation between SLM's uncertainty and LLM's rejection probability. Furthermore, we theoretically derive optimal uncertainty thresholds and optimal vocabulary truncation strategies. Simulation results show that, compared to standard HLM, CU-HLM achieves up to 206$\times$ higher token throughput by skipping 74.8% transmissions with 97.4% vocabulary compression, while maintaining 97.4% accuracy.
Uncertainty-Aware Hybrid Inference with On-Device Small and Remote Large Language Models
Dec 17, 2024



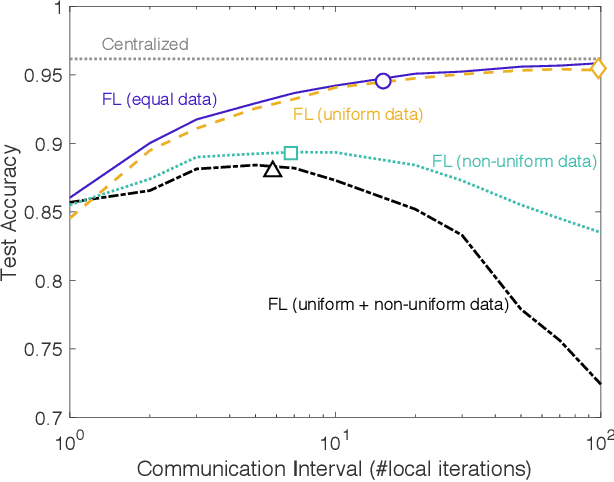
This paper studies a hybrid language model (HLM) architecture that integrates a small language model (SLM) operating on a mobile device with a large language model (LLM) hosted at the base station (BS) of a wireless network. The HLM token generation process follows the speculative inference principle: the SLM's vocabulary distribution is uploaded to the LLM, which either accepts or rejects it, with rejected tokens being resampled by the LLM. While this approach ensures alignment between the vocabulary distributions of the SLM and LLM, it suffers from low token throughput due to uplink transmission and the computation costs of running both language models. To address this, we propose a novel HLM structure coined Uncertainty-aware HLM (U-HLM), wherein the SLM locally measures its output uncertainty, and skips both uplink transmissions and LLM operations for tokens that are likely to be accepted. This opportunistic skipping is enabled by our empirical finding of a linear correlation between the SLM's uncertainty and the LLM's rejection probability. We analytically derive the uncertainty threshold and evaluate its expected risk of rejection. Simulations show that U-HLM reduces uplink transmissions and LLM computation by 45.93%, while achieving up to 97.54% of the LLM's inference accuracy and 2.54$\times$ faster token throughput than HLM without skipping.
Privacy-Preserving Split Learning with Vision Transformers using Patch-Wise Random and Noisy CutMix
Aug 02, 2024



In computer vision, the vision transformer (ViT) has increasingly superseded the convolutional neural network (CNN) for improved accuracy and robustness. However, ViT's large model sizes and high sample complexity make it difficult to train on resource-constrained edge devices. Split learning (SL) emerges as a viable solution, leveraging server-side resources to train ViTs while utilizing private data from distributed devices. However, SL requires additional information exchange for weight updates between the device and the server, which can be exposed to various attacks on private training data. To mitigate the risk of data breaches in classification tasks, inspired from the CutMix regularization, we propose a novel privacy-preserving SL framework that injects Gaussian noise into smashed data and mixes randomly chosen patches of smashed data across clients, coined DP-CutMixSL. Our analysis demonstrates that DP-CutMixSL is a differentially private (DP) mechanism that strengthens privacy protection against membership inference attacks during forward propagation. Through simulations, we show that DP-CutMixSL improves privacy protection against membership inference attacks, reconstruction attacks, and label inference attacks, while also improving accuracy compared to DP-SL and DP-MixSL.
SplitAMC: Split Learning for Robust Automatic Modulation Classification
Apr 17, 2023Automatic modulation classification (AMC) is a technology that identifies a modulation scheme without prior signal information and plays a vital role in various applications, including cognitive radio and link adaptation. With the development of deep learning (DL), DL-based AMC methods have emerged, while most of them focus on reducing computational complexity in a centralized structure. This centralized learning-based AMC (CentAMC) violates data privacy in the aspect of direct transmission of client-side raw data. Federated learning-based AMC (FedeAMC) can bypass this issue by exchanging model parameters, but causes large resultant latency and client-side computational load. Moreover, both CentAMC and FedeAMC are vulnerable to large-scale noise occured in the wireless channel between the client and the server. To this end, we develop a novel AMC method based on a split learning (SL) framework, coined SplitAMC, that can achieve high accuracy even in poor channel conditions, while guaranteeing data privacy and low latency. In SplitAMC, each client can benefit from data privacy leakage by exchanging smashed data and its gradient instead of raw data, and has robustness to noise with the help of high scale of smashed data. Numerical evaluations validate that SplitAMC outperforms CentAMC and FedeAMC in terms of accuracy for all SNRs as well as latency.
Differentially Private CutMix for Split Learning with Vision Transformer
Oct 28, 2022



Recently, vision transformer (ViT) has started to outpace the conventional CNN in computer vision tasks. Considering privacy-preserving distributed learning with ViT, federated learning (FL) communicates models, which becomes ill-suited due to ViT' s large model size and computing costs. Split learning (SL) detours this by communicating smashed data at a cut-layer, yet suffers from data privacy leakage and large communication costs caused by high similarity between ViT' s smashed data and input data. Motivated by this problem, we propose DP-CutMixSL, a differentially private (DP) SL framework by developing DP patch-level randomized CutMix (DP-CutMix), a novel privacy-preserving inter-client interpolation scheme that replaces randomly selected patches in smashed data. By experiment, we show that DP-CutMixSL not only boosts privacy guarantees and communication efficiency, but also achieves higher accuracy than its Vanilla SL counterpart. Theoretically, we analyze that DP-CutMix amplifies R\'enyi DP (RDP), which is upper-bounded by its Vanilla Mixup counterpart.
Federated Knowledge Distillation
Nov 04, 2020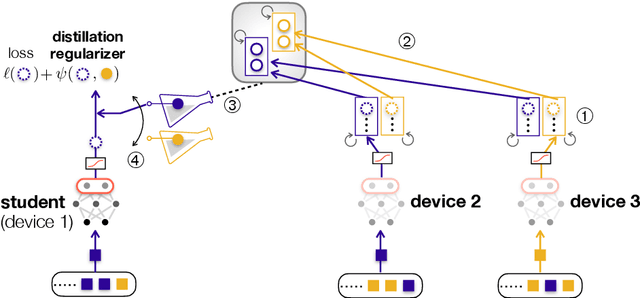

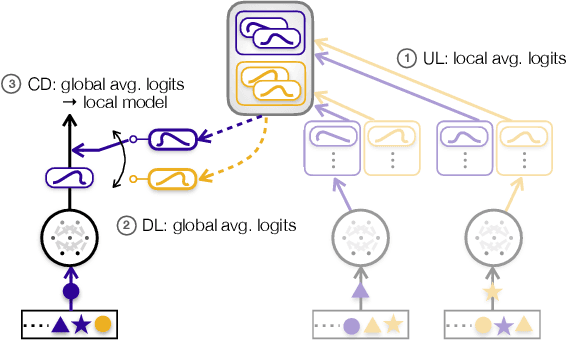
Distributed learning frameworks often rely on exchanging model parameters across workers, instead of revealing their raw data. A prime example is federated learning that exchanges the gradients or weights of each neural network model. Under limited communication resources, however, such a method becomes extremely costly particularly for modern deep neural networks having a huge number of model parameters. In this regard, federated distillation (FD) is a compelling distributed learning solution that only exchanges the model outputs whose dimensions are commonly much smaller than the model sizes (e.g., 10 labels in the MNIST dataset). The goal of this chapter is to provide a deep understanding of FD while demonstrating its communication efficiency and applicability to a variety of tasks. To this end, towards demystifying the operational principle of FD, the first part of this chapter provides a novel asymptotic analysis for two foundational algorithms of FD, namely knowledge distillation (KD) and co-distillation (CD), by exploiting the theory of neural tangent kernel (NTK). Next, the second part elaborates on a baseline implementation of FD for a classification task, and illustrates its performance in terms of accuracy and communication efficiency compared to FL. Lastly, to demonstrate the applicability of FD to various distributed learning tasks and environments, the third part presents two selected applications, namely FD over asymmetric uplink-and-downlink wireless channels and FD for reinforcement learning.
Mix2FLD: Downlink Federated Learning After Uplink Federated Distillation With Two-Way Mixup
Jun 17, 2020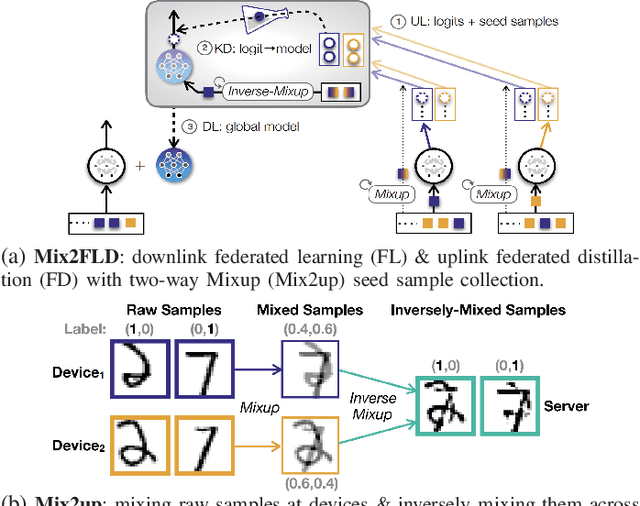
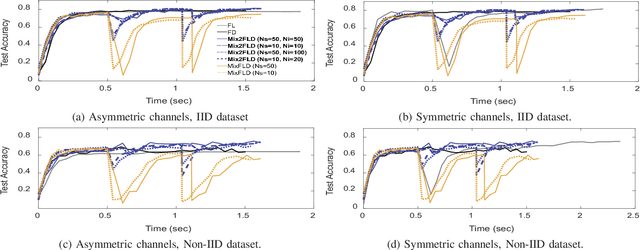
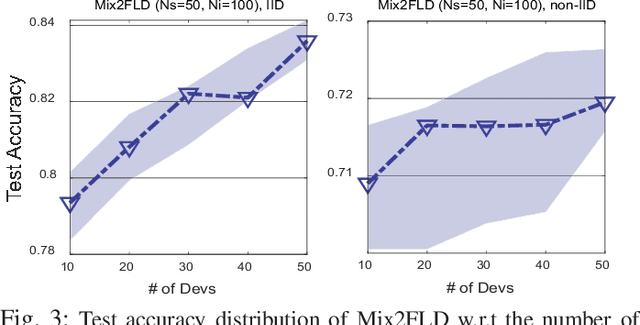
This letter proposes a novel communication-efficient and privacy-preserving distributed machine learning framework, coined Mix2FLD. To address uplink-downlink capacity asymmetry, local model outputs are uploaded to a server in the uplink as in federated distillation (FD), whereas global model parameters are downloaded in the downlink as in federated learning (FL). This requires a model output-to-parameter conversion at the server, after collecting additional data samples from devices. To preserve privacy while not compromising accuracy, linearly mixed-up local samples are uploaded, and inversely mixed up across different devices at the server. Numerical evaluations show that Mix2FLD achieves up to 16.7% higher test accuracy while reducing convergence time by up to 18.8% under asymmetric uplink-downlink channels compared to FL.
Distilling On-Device Intelligence at the Network Edge
Aug 16, 2019
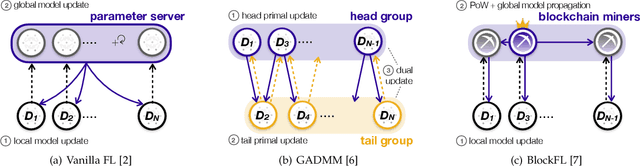
Devices at the edge of wireless networks are the last mile data sources for machine learning (ML). As opposed to traditional ready-made public datasets, these user-generated private datasets reflect the freshest local environments in real time. They are thus indispensable for enabling mission-critical intelligent systems, ranging from fog radio access networks (RANs) to driverless cars and e-Health wearables. This article focuses on how to distill high-quality on-device ML models using fog computing, from such user-generated private data dispersed across wirelessly connected devices. To this end, we introduce communication-efficient and privacy-preserving distributed ML frameworks, termed fog ML (FML), wherein on-device ML models are trained by exchanging model parameters, model outputs, and surrogate data. We then present advanced FML frameworks addressing wireless RAN characteristics, limited on-device resources, and imbalanced data distributions. Our study suggests that the full potential of FML can be reached by co-designing communication and distributed ML operations while accounting for heterogeneous hardware specifications, data characteristics, and user requirements.
Multi-hop Federated Private Data Augmentation with Sample Compression
Jul 15, 2019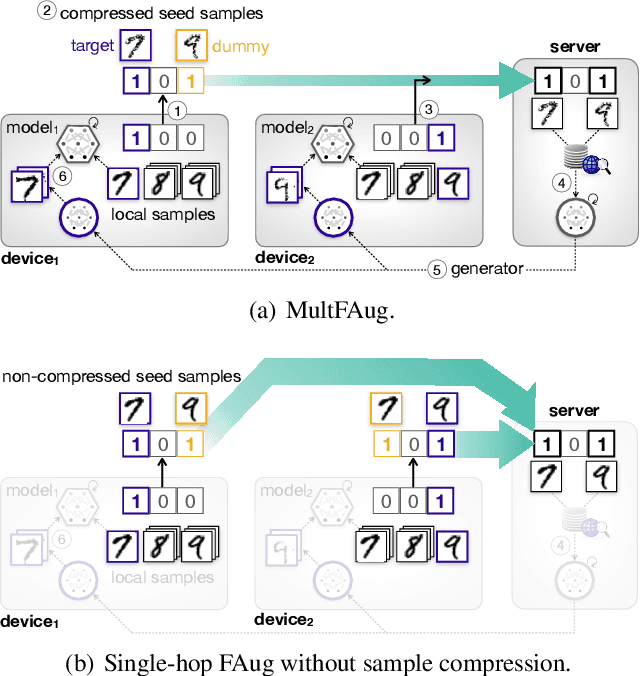

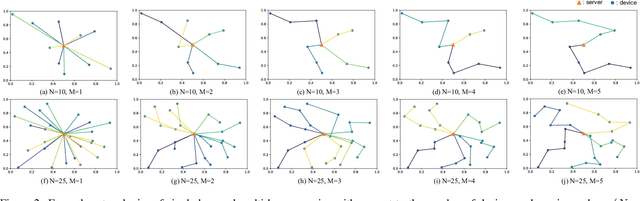
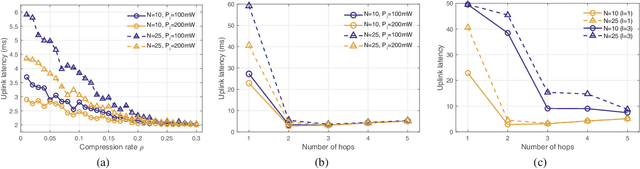
On-device machine learning (ML) has brought about the accessibility to a tremendous amount of data from the users while keeping their local data private instead of storing it in a central entity. However, for privacy guarantee, it is inevitable at each device to compensate for the quality of data or learning performance, especially when it has a non-IID training dataset. In this paper, we propose a data augmentation framework using a generative model: multi-hop federated augmentation with sample compression (MultFAug). A multi-hop protocol speeds up the end-to-end over-the-air transmission of seed samples by enhancing the transport capacity. The relaying devices guarantee stronger privacy preservation as well since the origin of each seed sample is hidden in those participants. For further privatization on the individual sample level, the devices compress their data samples. The devices sparsify their data samples prior to transmissions to reduce the sample size, which impacts the communication payload. This preprocessing also strengthens the privacy of each sample, which corresponds to the input perturbation for preserving sample privacy. The numerical evaluations show that the proposed framework significantly improves privacy guarantee, transmission delay, and local training performance with adjustment to the number of hops and compression rate.