 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMix2FLD: Downlink Federated Learning After Uplink Federated Distillation With Two-Way Mixup
Jun 17, 2020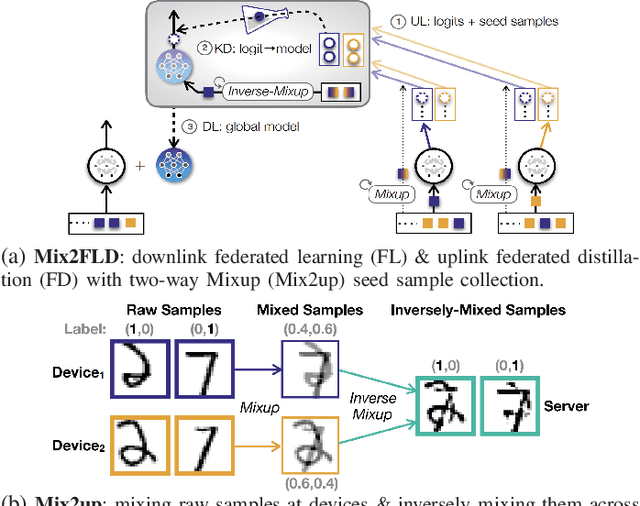
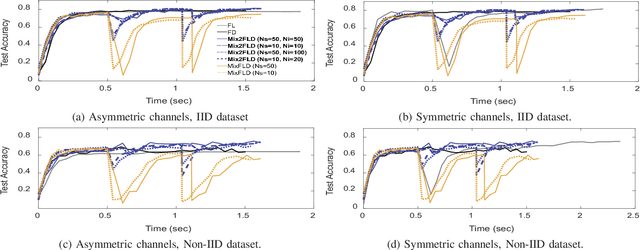
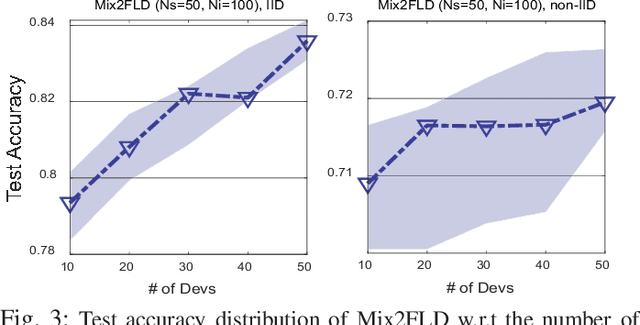
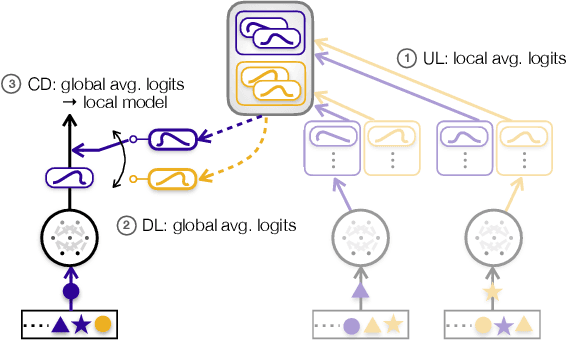
This letter proposes a novel communication-efficient and privacy-preserving distributed machine learning framework, coined Mix2FLD. To address uplink-downlink capacity asymmetry, local model outputs are uploaded to a server in the uplink as in federated distillation (FD), whereas global model parameters are downloaded in the downlink as in federated learning (FL). This requires a model output-to-parameter conversion at the server, after collecting additional data samples from devices. To preserve privacy while not compromising accuracy, linearly mixed-up local samples are uploaded, and inversely mixed up across different devices at the server. Numerical evaluations show that Mix2FLD achieves up to 16.7% higher test accuracy while reducing convergence time by up to 18.8% under asymmetric uplink-downlink channels compared to FL.
Proxy Experience Replay: Federated Distillation for Distributed Reinforcement Learning
May 15, 2020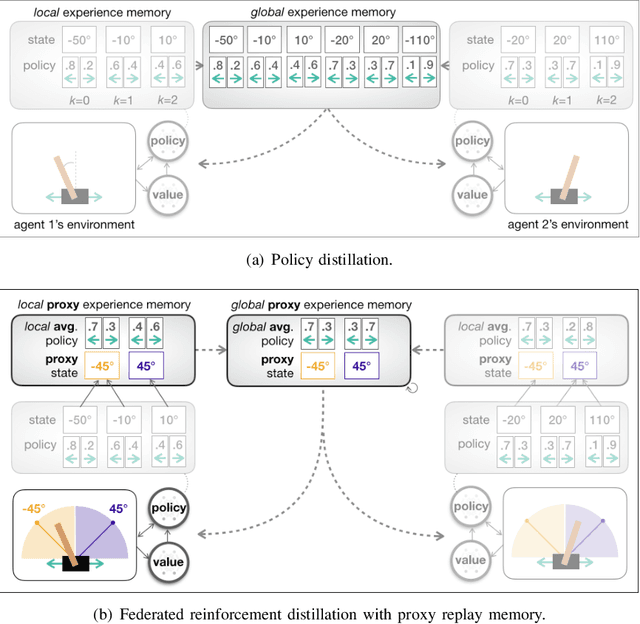
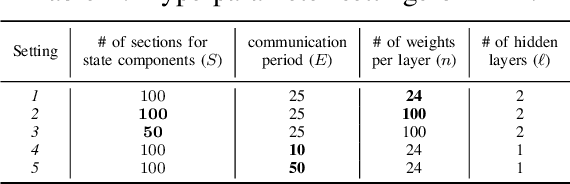
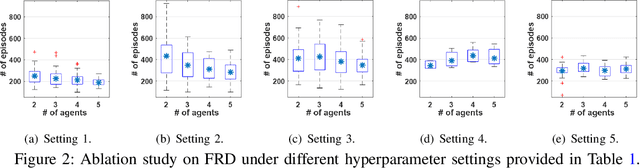
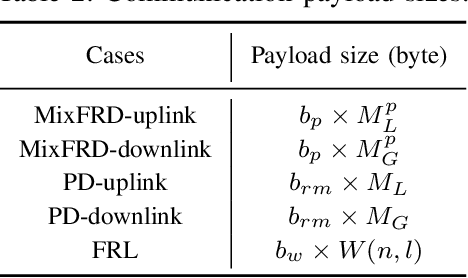
Traditional distributed deep reinforcement learning (RL) commonly relies on exchanging the experience replay memory (RM) of each agent. Since the RM contains all state observations and action policy history, it may incur huge communication overhead while violating the privacy of each agent. Alternatively, this article presents a communication-efficient and privacy-preserving distributed RL framework, coined federated reinforcement distillation (FRD). In FRD, each agent exchanges its proxy experience replay memory (ProxRM), in which policies are locally averaged with respect to proxy states clustering actual states. To provide FRD design insights, we present ablation studies on the impact of ProxRM structures, neural network architectures, and communication intervals. Furthermore, we propose an improved version of FRD, coined mixup augmented FRD (MixFRD), in which ProxRM is interpolated using the mixup data augmentation algorithm. Simulations in a Cartpole environment validate the effectiveness of MixFRD in reducing the variance of mission completion time and communication cost, compared to the benchmark schemes, vanilla FRD, federated reinforcement learning (FRL), and policy distillation (PD).
Distilling On-Device Intelligence at the Network Edge
Aug 16, 2019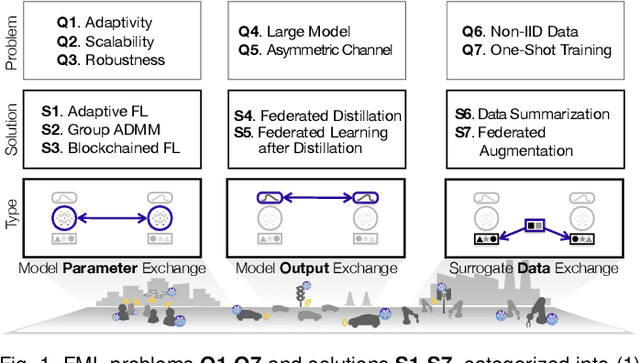
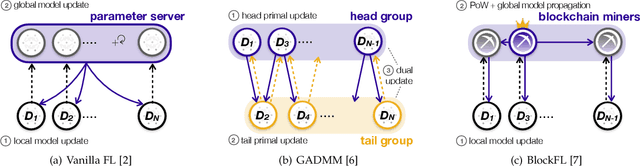
Devices at the edge of wireless networks are the last mile data sources for machine learning (ML). As opposed to traditional ready-made public datasets, these user-generated private datasets reflect the freshest local environments in real time. They are thus indispensable for enabling mission-critical intelligent systems, ranging from fog radio access networks (RANs) to driverless cars and e-Health wearables. This article focuses on how to distill high-quality on-device ML models using fog computing, from such user-generated private data dispersed across wirelessly connected devices. To this end, we introduce communication-efficient and privacy-preserving distributed ML frameworks, termed fog ML (FML), wherein on-device ML models are trained by exchanging model parameters, model outputs, and surrogate data. We then present advanced FML frameworks addressing wireless RAN characteristics, limited on-device resources, and imbalanced data distributions. Our study suggests that the full potential of FML can be reached by co-designing communication and distributed ML operations while accounting for heterogeneous hardware specifications, data characteristics, and user requirements.
Federated Reinforcement Distillation with Proxy Experience Memory
Jul 15, 2019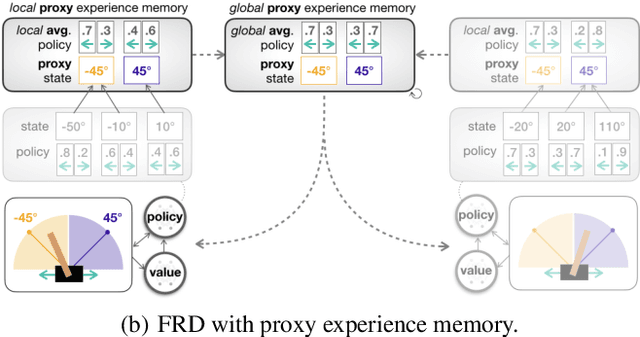
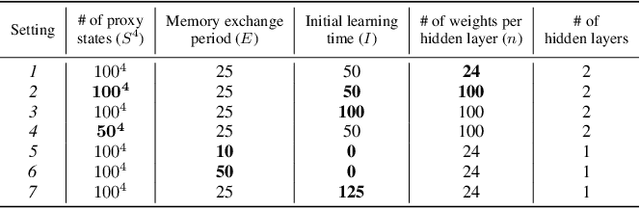
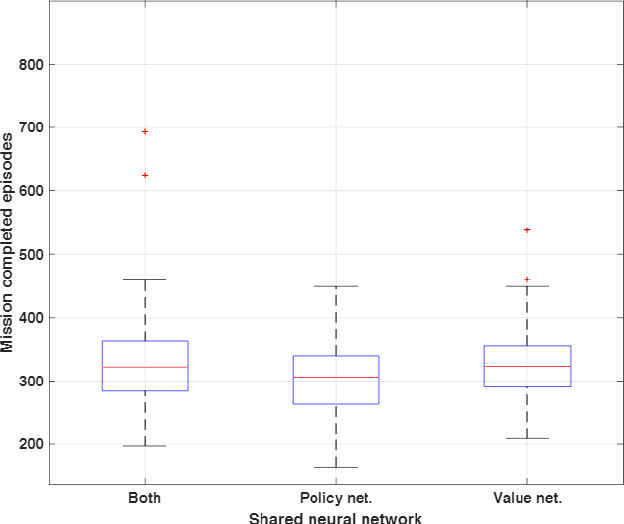
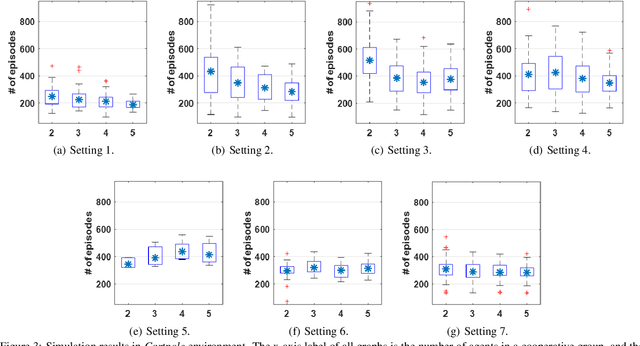
In distributed reinforcement learning, it is common to exchange the experience memory of each agent and thereby collectively train their local models. The experience memory, however, contains all the preceding state observations and their corresponding policies of the host agent, which may violate the privacy of the agent. To avoid this problem, in this work, we propose a privacy-preserving distributed reinforcement learning (RL) framework, termed federated reinforcement distillation (FRD). The key idea is to exchange a proxy experience memory comprising a pre-arranged set of states and time-averaged policies, thereby preserving the privacy of actual experiences. Based on an advantage actor-critic RL architecture, we numerically evaluate the effectiveness of FRD and investigate how the performance of FRD is affected by the proxy memory structure and different memory exchanging rules.
Multi-hop Federated Private Data Augmentation with Sample Compression
Jul 15, 2019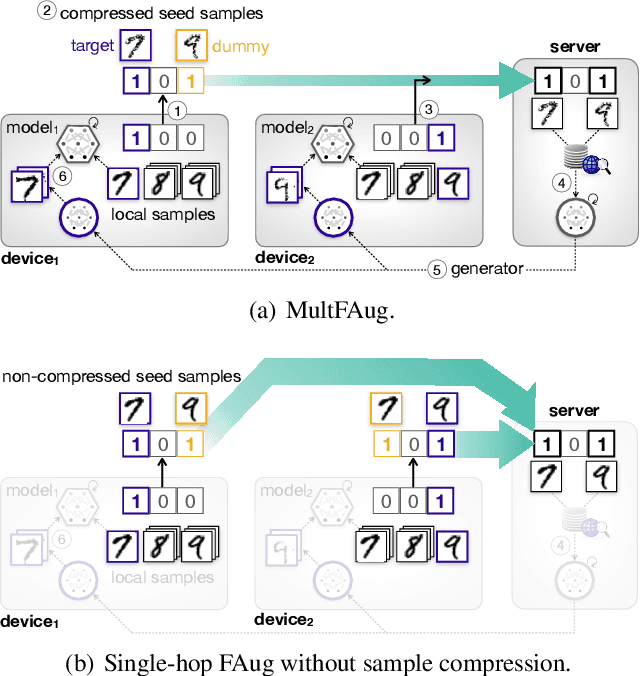

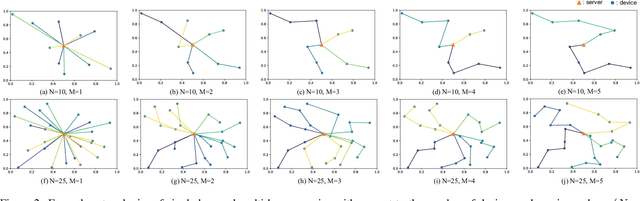
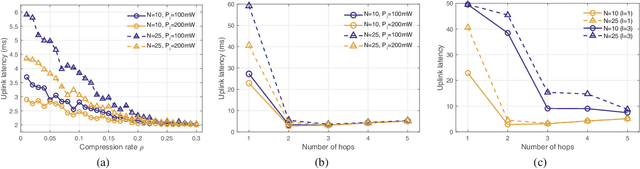
On-device machine learning (ML) has brought about the accessibility to a tremendous amount of data from the users while keeping their local data private instead of storing it in a central entity. However, for privacy guarantee, it is inevitable at each device to compensate for the quality of data or learning performance, especially when it has a non-IID training dataset. In this paper, we propose a data augmentation framework using a generative model: multi-hop federated augmentation with sample compression (MultFAug). A multi-hop protocol speeds up the end-to-end over-the-air transmission of seed samples by enhancing the transport capacity. The relaying devices guarantee stronger privacy preservation as well since the origin of each seed sample is hidden in those participants. For further privatization on the individual sample level, the devices compress their data samples. The devices sparsify their data samples prior to transmissions to reduce the sample size, which impacts the communication payload. This preprocessing also strengthens the privacy of each sample, which corresponds to the input perturbation for preserving sample privacy. The numerical evaluations show that the proposed framework significantly improves privacy guarantee, transmission delay, and local training performance with adjustment to the number of hops and compression rate.
Communication-Efficient On-Device Machine Learning: Federated Distillation and Augmentation under Non-IID Private Data
Nov 28, 2018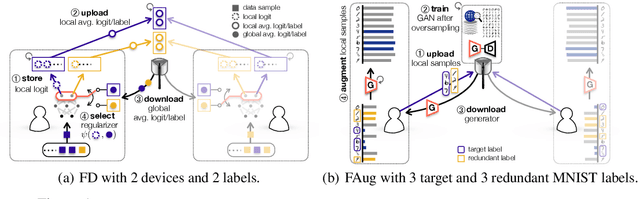

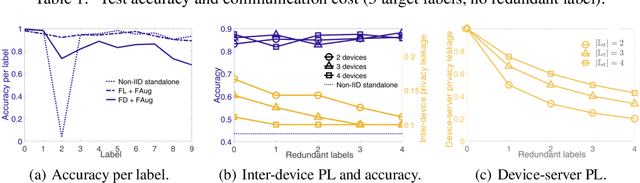
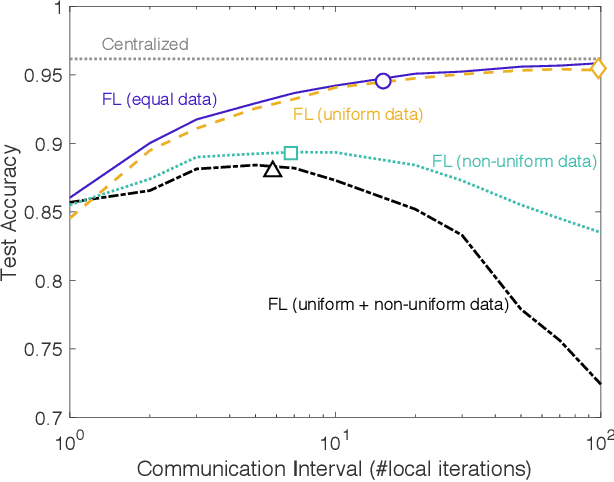
On-device machine learning (ML) enables the training process to exploit a massive amount of user-generated private data samples. To enjoy this benefit, inter-device communication overhead should be minimized. With this end, we propose federated distillation (FD), a distributed model training algorithm whose communication payload size is much smaller than a benchmark scheme, federated learning (FL), particularly when the model size is large. Moreover, user-generated data samples are likely to become non-IID across devices, which commonly degrades the performance compared to the case with an IID dataset. To cope with this, we propose federated augmentation (FAug), where each device collectively trains a generative model, and thereby augments its local data towards yielding an IID dataset. Empirical studies demonstrate that FD with FAug yields around 26x less communication overhead while achieving 95-98% test accuracy compared to FL.