 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Energy Efficiency and Distributional Robustness in Over-the-Air Federated Learning
Dec 22, 2023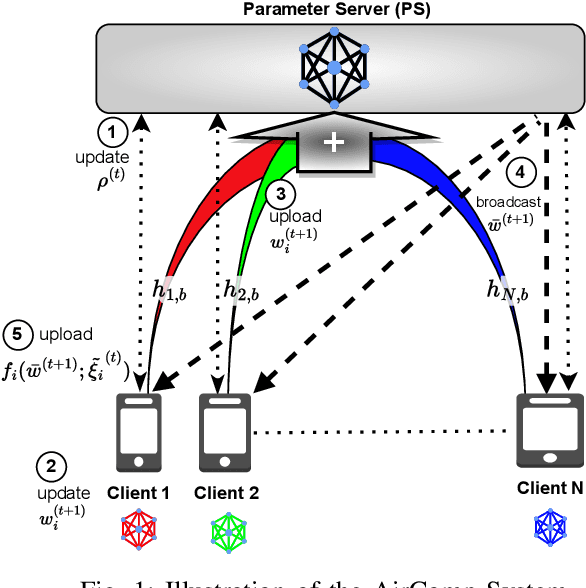
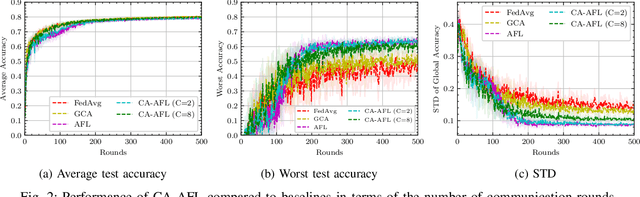
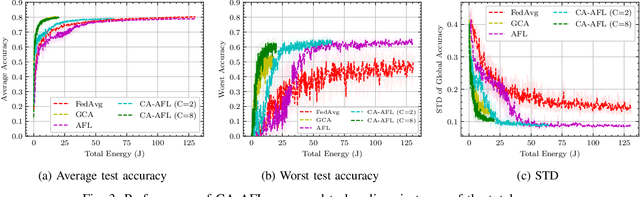
The growing number of wireless edge devices has magnified challenges concerning energy, bandwidth, latency, and data heterogeneity. These challenges have become bottlenecks for distributed learning. To address these issues, this paper presents a novel approach that ensures energy efficiency for distributionally robust federated learning (FL) with over air computation (AirComp). In this context, to effectively balance robustness with energy efficiency, we introduce a novel client selection method that integrates two complementary insights: a deterministic one that is designed for energy efficiency, and a probabilistic one designed for distributional robustness. Simulation results underscore the efficacy of the proposed algorithm, revealing its superior performance compared to baselines from both robustness and energy efficiency perspectives, achieving more than 3-fold energy savings compared to the considered baselines.
DR-DSGD: A Distributionally Robust Decentralized Learning Algorithm over Graphs
Aug 29, 2022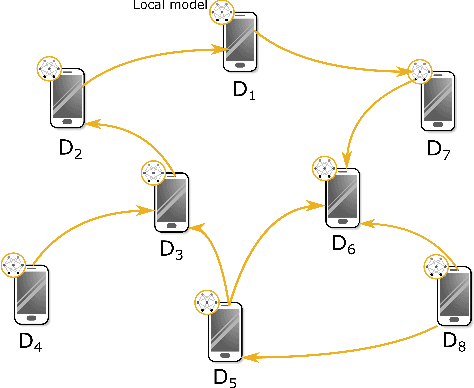
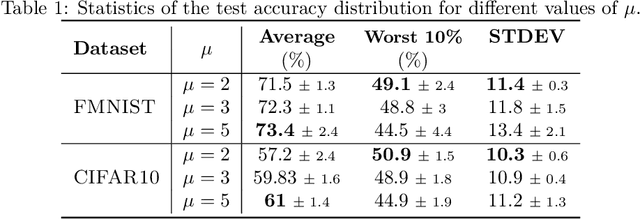
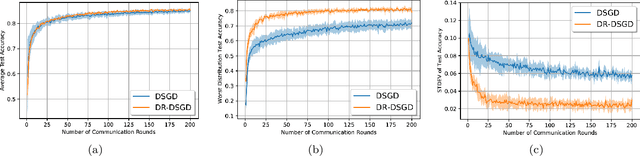

In this paper, we propose to solve a regularized distributionally robust learning problem in the decentralized setting, taking into account the data distribution shift. By adding a Kullback-Liebler regularization function to the robust min-max optimization problem, the learning problem can be reduced to a modified robust minimization problem and solved efficiently. Leveraging the newly formulated optimization problem, we propose a robust version of Decentralized Stochastic Gradient Descent (DSGD), coined Distributionally Robust Decentralized Stochastic Gradient Descent (DR-DSGD). Under some mild assumptions and provided that the regularization parameter is larger than one, we theoretically prove that DR-DSGD achieves a convergence rate of $\mathcal{O}\left(1/\sqrt{KT} + K/T\right)$, where $K$ is the number of devices and $T$ is the number of iterations. Simulation results show that our proposed algorithm can improve the worst distribution test accuracy by up to $10\%$. Moreover, DR-DSGD is more communication-efficient than DSGD since it requires fewer communication rounds (up to $20$ times less) to achieve the same worst distribution test accuracy target. Furthermore, the conducted experiments reveal that DR-DSGD results in a fairer performance across devices in terms of test accuracy.
FedNew: A Communication-Efficient and Privacy-Preserving Newton-Type Method for Federated Learning
Jun 17, 2022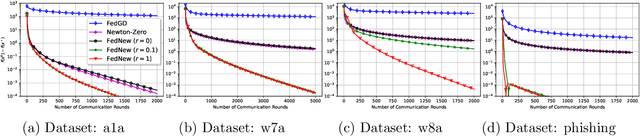
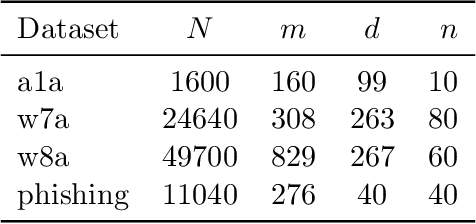
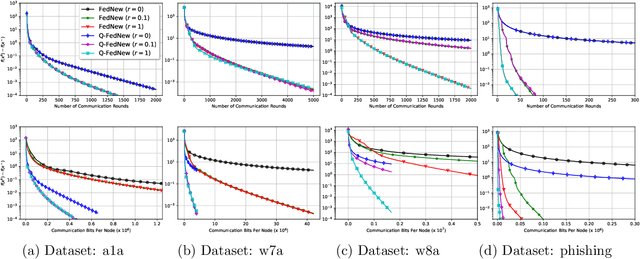
Newton-type methods are popular in federated learning due to their fast convergence. Still, they suffer from two main issues, namely: low communication efficiency and low privacy due to the requirement of sending Hessian information from clients to parameter server (PS). In this work, we introduced a novel framework called FedNew in which there is no need to transmit Hessian information from clients to PS, hence resolving the bottleneck to improve communication efficiency. In addition, FedNew hides the gradient information and results in a privacy-preserving approach compared to the existing state-of-the-art. The core novel idea in FedNew is to introduce a two level framework, and alternate between updating the inverse Hessian-gradient product using only one alternating direction method of multipliers (ADMM) step and then performing the global model update using Newton's method. Though only one ADMM pass is used to approximate the inverse Hessian-gradient product at each iteration, we develop a novel theoretical approach to show the converging behavior of FedNew for convex problems. Additionally, a significant reduction in communication overhead is achieved by utilizing stochastic quantization. Numerical results using real datasets show the superiority of FedNew compared to existing methods in terms of communication costs.
Communication-Efficient Split Learning Based on Analog Communication and Over the Air Aggregation
Jun 02, 2021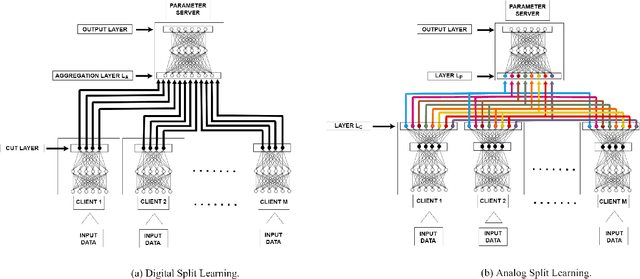
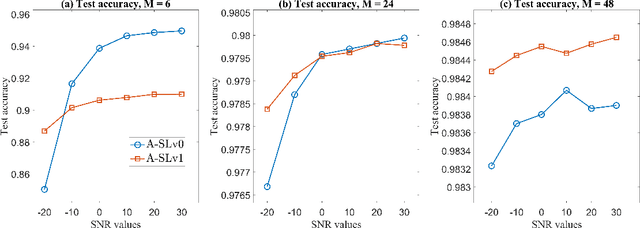
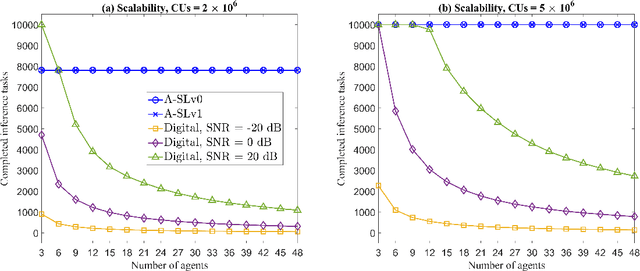
Split-learning (SL) has recently gained popularity due to its inherent privacy-preserving capabilities and ability to enable collaborative inference for devices with limited computational power. Standard SL algorithms assume an ideal underlying digital communication system and ignore the problem of scarce communication bandwidth. However, for a large number of agents, limited bandwidth resources, and time-varying communication channels, the communication bandwidth can become the bottleneck. To address this challenge, in this work, we propose a novel SL framework to solve the remote inference problem that introduces an additional layer at the agent side and constrains the choices of the weights and the biases to ensure over the air aggregation. Hence, the proposed approach maintains constant communication cost with respect to the number of agents enabling remote inference under limited bandwidth. Numerical results show that our proposed algorithm significantly outperforms the digital implementation in terms of communication-efficiency, especially as the number of agents grows large.
Energy-Efficient Model Compression and Splitting for Collaborative Inference Over Time-Varying Channels
Jun 02, 2021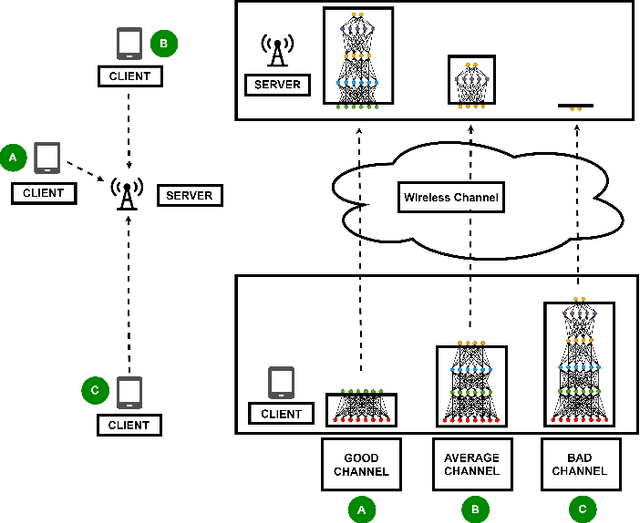
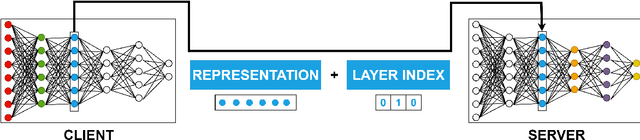
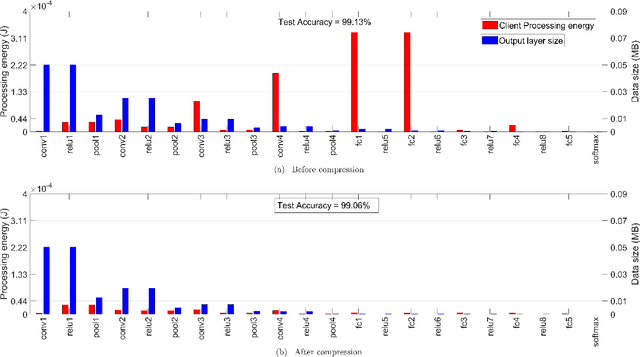
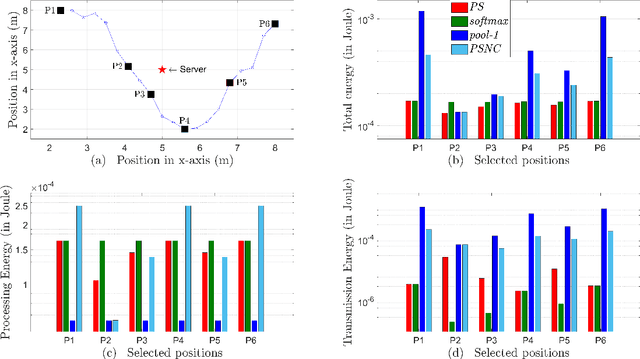
Today's intelligent applications can achieve high performance accuracy using machine learning (ML) techniques, such as deep neural networks (DNNs). Traditionally, in a remote DNN inference problem, an edge device transmits raw data to a remote node that performs the inference task. However, this may incur high transmission energy costs and puts data privacy at risk. In this paper, we propose a technique to reduce the total energy bill at the edge device by utilizing model compression and time-varying model split between the edge and remote nodes. The time-varying representation accounts for time-varying channels and can significantly reduce the total energy at the edge device while maintaining high accuracy (low loss). We implement our approach in an image classification task using the MNIST dataset, and the system environment is simulated as a trajectory navigation scenario to emulate different channel conditions. Numerical simulations show that our proposed solution results in minimal energy consumption and $CO_2$ emission compared to the considered baselines while exhibiting robust performance across different channel conditions and bandwidth regime choices.
Energy-Efficient and Federated Meta-Learning via Projected Stochastic Gradient Ascent
May 31, 2021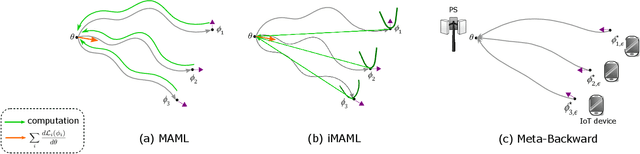
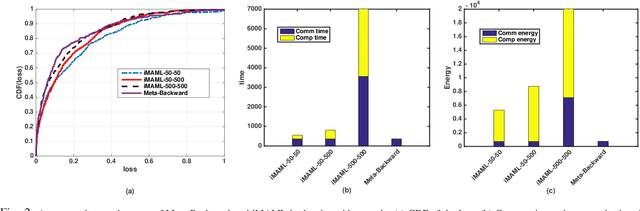
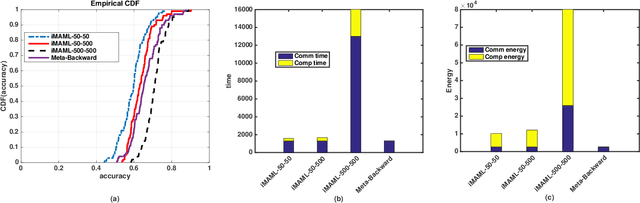
In this paper, we propose an energy-efficient federated meta-learning framework. The objective is to enable learning a meta-model that can be fine-tuned to a new task with a few number of samples in a distributed setting and at low computation and communication energy consumption. We assume that each task is owned by a separate agent, so a limited number of tasks is used to train a meta-model. Assuming each task was trained offline on the agent's local data, we propose a lightweight algorithm that starts from the local models of all agents, and in a backward manner using projected stochastic gradient ascent (P-SGA) finds a meta-model. The proposed method avoids complex computations such as computing hessian, double looping, and matrix inversion, while achieving high performance at significantly less energy consumption compared to the state-of-the-art methods such as MAML and iMAML on conducted experiments for sinusoid regression and image classification tasks.
Cross Layer Optimization and Distributed Reinforcement Learning Approach for Tile-Based 360 Degree Wireless Video Streaming
Nov 12, 2020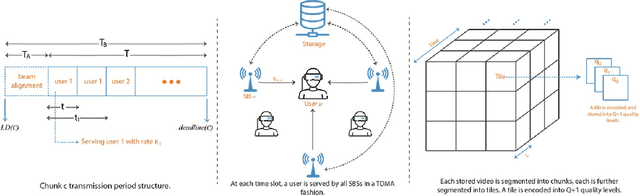
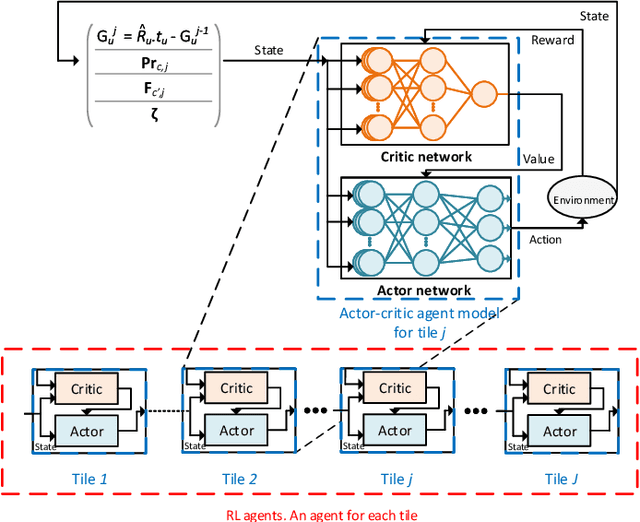

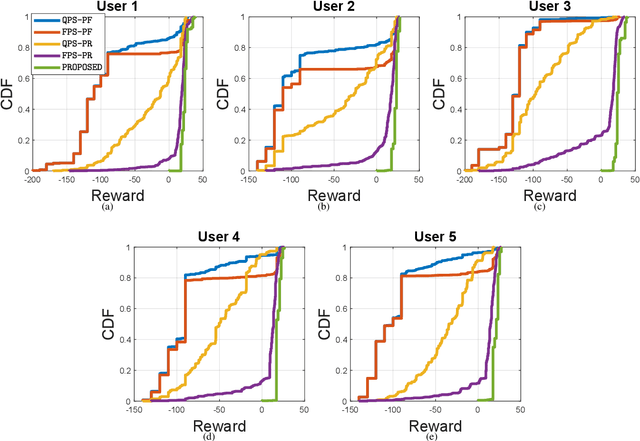
Wirelessly streaming high quality 360 degree videos is still a challenging problem. When there are many users watching different 360 degree videos and competing for the computing and communication resources, the streaming algorithm at hand should maximize the average quality of experience (QoE) while guaranteeing a minimum rate for each user. In this paper, we propose a \emph{cross layer} optimization approach that maximizes the available rate to each user and efficiently uses it to maximize users' QoE. Particularly, we consider a tile based 360 degree video streaming, and we optimize a QoE metric that balances the tradeoff between maximizing each user's QoE and ensuring fairness among users. We show that the problem can be decoupled into two interrelated subproblems: (i) a physical layer subproblem whose objective is to find the download rate for each user, and (ii) an application layer subproblem whose objective is to use that rate to find a quality decision per tile such that the user's QoE is maximized. We prove that the physical layer subproblem can be solved optimally with low complexity and an actor-critic deep reinforcement learning (DRL) is proposed to leverage the parallel training of multiple independent agents and solve the application layer subproblem. Extensive experiments reveal the robustness of our scheme and demonstrate its significant performance improvement compared to several baseline algorithms.
BayGo: Joint Bayesian Learning and Information-Aware Graph Optimization
Nov 09, 2020
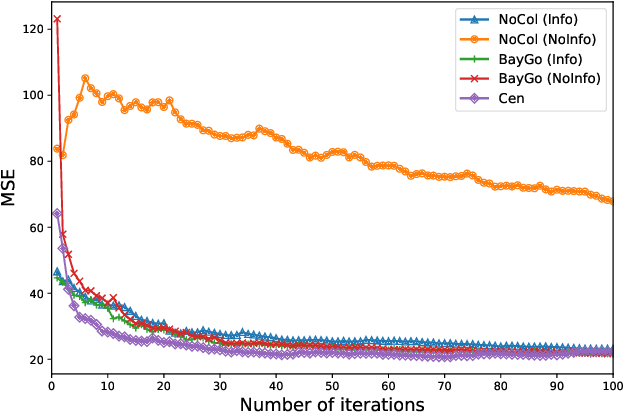
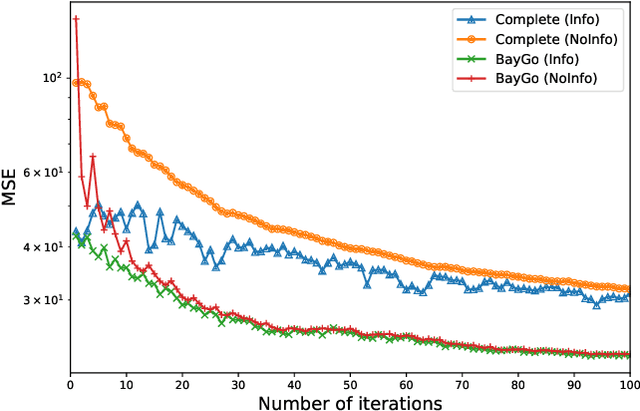
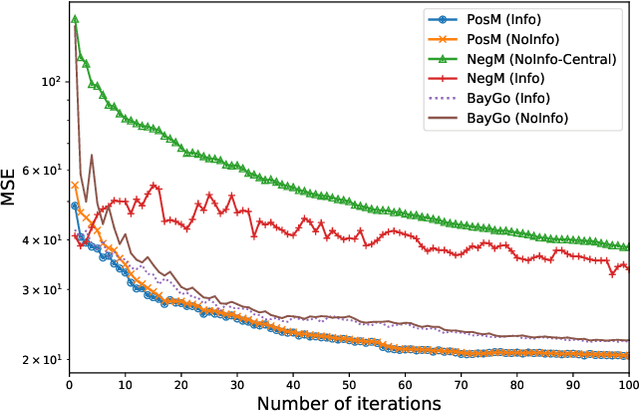
This article deals with the problem of distributed machine learning, in which agents update their models based on their local datasets, and aggregate the updated models collaboratively and in a fully decentralized manner. In this paper, we tackle the problem of information heterogeneity arising in multi-agent networks where the placement of informative agents plays a crucial role in the learning dynamics. Specifically, we propose BayGo, a novel fully decentralized joint Bayesian learning and graph optimization framework with proven fast convergence over a sparse graph. Under our framework, agents are able to learn and communicate with the most informative agent to their own learning. Unlike prior works, our framework assumes no prior knowledge of the data distribution across agents nor does it assume any knowledge of the true parameter of the system. The proposed alternating minimization based framework ensures global connectivity in a fully decentralized way while minimizing the number of communication links. We theoretically show that by optimizing the proposed objective function, the estimation error of the posterior probability distribution decreases exponentially at each iteration. Via extensive simulations, we show that our framework achieves faster convergence and higher accuracy compared to fully-connected and star topology graphs.
Communication Efficient Distributed Learning with Censored, Quantized, and Generalized Group ADMM
Sep 14, 2020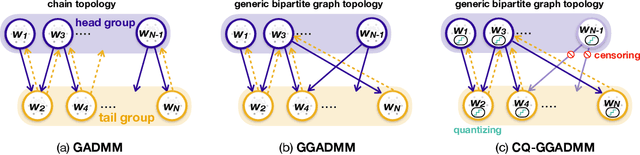

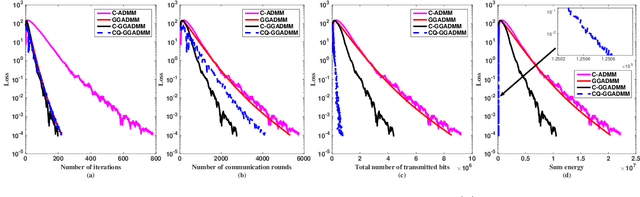
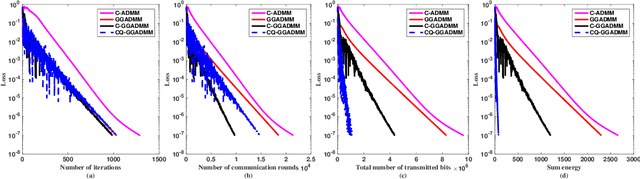
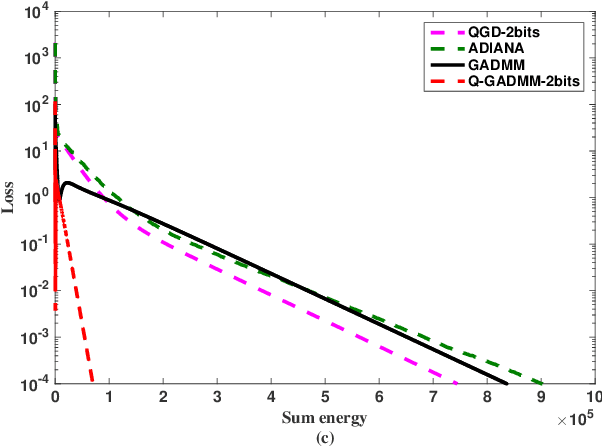
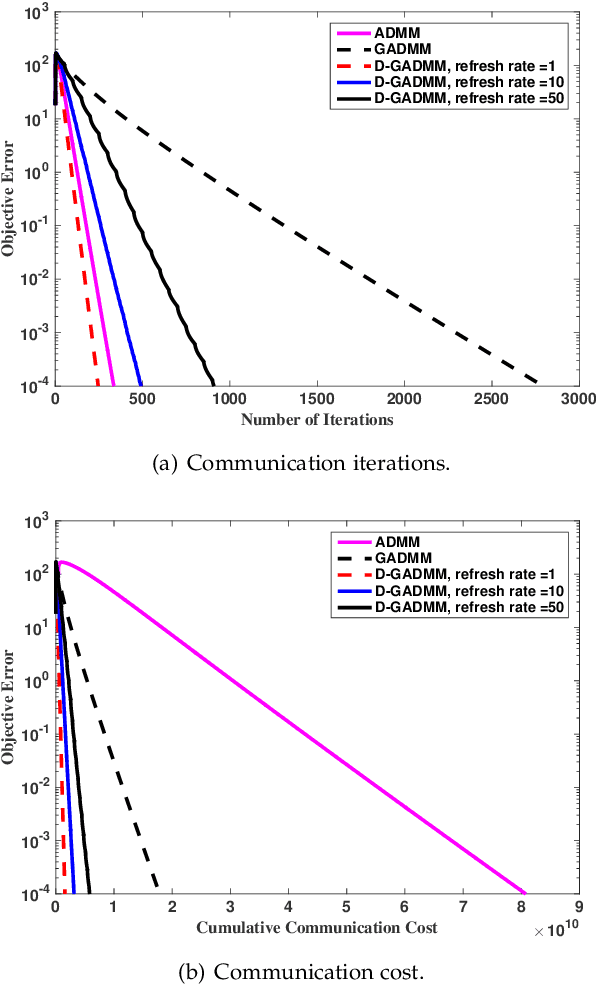
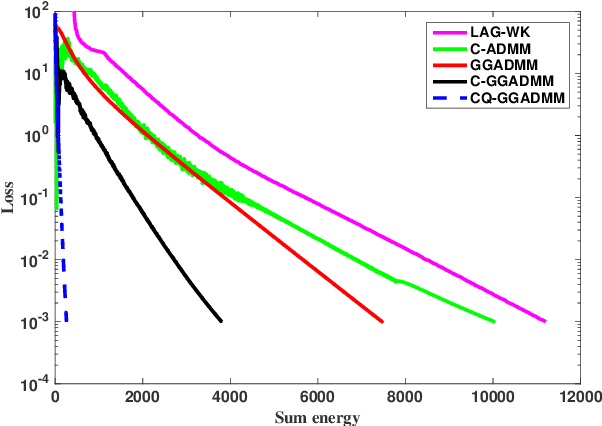
In this paper, we propose a communication-efficiently decentralized machine learning framework that solves a consensus optimization problem defined over a network of inter-connected workers. The proposed algorithm, Censored-and-Quantized Generalized GADMM (CQ-GGADMM), leverages the novel worker grouping and decentralized learning ideas of Group Alternating Direction Method of Multipliers (GADMM), and pushes the frontier in communication efficiency by extending its applicability to generalized network topologies, while incorporating link censoring for negligible updates after quantization. We theoretically prove that CQ-GGADMM achieves the linear convergence rate when the local objective functions are strongly convex under some mild assumptions. Numerical simulations corroborate that CQ-GGADMM exhibits higher communication efficiency in terms of the number of communication rounds and transmit energy consumption without compromising the accuracy and convergence speed, compared to the benchmark schemes based on decentralized ADMM without censoring, quantization, and/or the worker grouping method of GADMM.
Communication-Efficient and Distributed Learning Over Wireless Networks: Principles and Applications
Aug 06, 2020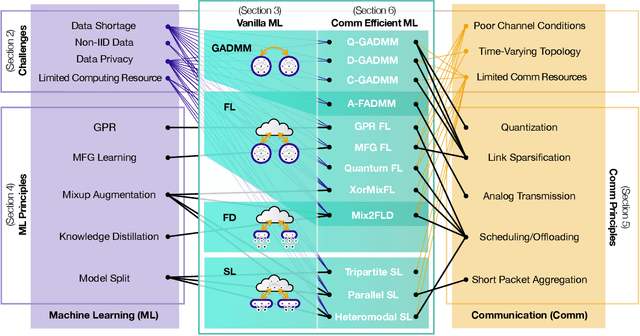
Machine learning (ML) is a promising enabler for the fifth generation (5G) communication systems and beyond. By imbuing intelligence into the network edge, edge nodes can proactively carry out decision-making, and thereby react to local environmental changes and disturbances while experiencing zero communication latency. To achieve this goal, it is essential to cater for high ML inference accuracy at scale under time-varying channel and network dynamics, by continuously exchanging fresh data and ML model updates in a distributed way. Taming this new kind of data traffic boils down to improving the communication efficiency of distributed learning by optimizing communication payload types, transmission techniques, and scheduling, as well as ML architectures, algorithms, and data processing methods. To this end, this article aims to provide a holistic overview of relevant communication and ML principles, and thereby present communication-efficient and distributed learning frameworks with selected use cases.