 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-based Distributed Learning for Diverse and Discriminative Representations
Apr 20, 2026In large-scale distributed scenarios, increasingly complex tasks demand more intelligent collaboration across networks, requiring the joint extraction of structural representations from data samples. However, conventional task-specific approaches often result in nonstructural embeddings, leading to collapsed variability among data samples within the same class, particularly in classification tasks. To address this issue and fully leverage the intrinsic structure of data for downstream applications, we propose a novel distributed learning framework that ensures both diverse and discriminative representations. For independent and identically distributed (i.i.d.) data, we reformulate and decouple the global optimization function by introducing constraints on representation variance. The update rules are then derived and simplified using a primal-dual approach. For non-i.i.d. data distributions, we tackle the problem by clustering and virtually replicating nodes, allowing model updates within each cluster using block coordinate descent. In both cases, the resulting optimal solutions are theoretically proven to maintain discriminative and diverse properties, with a guaranteed convergence for i.i.d. conditions. Additionally, semantic information from representations is shared among nodes, reducing the need for common neural network architectures. Finally, extensive simulations on MNIST, CIFAR-10 and CIFAR-100 confirm the effectiveness of the proposed algorithms in capturing global structural representations.
Communication-Efficient and Robust Multi-Modal Federated Learning via Latent-Space Consensus
Mar 19, 2026Federated learning (FL) enables collaborative model training across distributed devices without sharing raw data, but applying FL to multi-modal settings introduces significant challenges. Clients typically possess heterogeneous modalities and model architectures, making it difficult to align feature spaces efficiently while preserving privacy and minimizing communication costs. To address this, we introduce CoMFed, a Communication-Efficient Multi-Modal Federated Learning framework that uses learnable projection matrices to generate compressed latent representations. A latent-space regularizer aligns these representations across clients, improving cross-modal consistency and robustness to outliers. Experiments on human activity recognition benchmarks show that CoMFed achieves competitive accuracy with minimal overhead.
SheafAlign: A Sheaf-theoretic Framework for Decentralized Multimodal Alignment
Oct 23, 2025Conventional multimodal alignment methods assume mutual redundancy across all modalities, an assumption that fails in real-world distributed scenarios. We propose SheafAlign, a sheaf-theoretic framework for decentralized multimodal alignment that replaces single-space alignment with multiple comparison spaces. This approach models pairwise modality relations through sheaf structures and leverages decentralized contrastive learning-based objectives for training. SheafAlign overcomes the limitations of prior methods by not requiring mutual redundancy among all modalities, preserving both shared and unique information. Experiments on multimodal sensing datasets show superior zero-shot generalization, cross-modal alignment, and robustness to missing modalities, with 50\% lower communication cost than state-of-the-art baselines.
Learning to Collaborate Over Graphs: A Selective Federated Multi-Task Learning Approach
Jun 11, 2025We present a novel federated multi-task learning method that leverages cross-client similarity to enable personalized learning for each client. To avoid transmitting the entire model to the parameter server, we propose a communication-efficient scheme that introduces a feature anchor, a compact vector representation that summarizes the features learned from the client's local classes. This feature anchor is shared with the server to account for local clients' distribution. In addition, the clients share the classification heads, a lightweight linear layer, and perform a graph-based regularization to enable collaboration among clients. By modeling collaboration between clients as a dynamic graph and continuously updating and refining this graph, we can account for any drift from the clients. To ensure beneficial knowledge transfer and prevent negative collaboration, we leverage a community detection-based approach that partitions this dynamic graph into homogeneous communities, maximizing the sum of task similarities, represented as the graph edges' weights, within each community. This mechanism restricts collaboration to highly similar clients within their formed communities, ensuring positive interaction and preserving personalization. Extensive experiments on two heterogeneous datasets demonstrate that our method significantly outperforms state-of-the-art baselines. Furthermore, we show that our method exhibits superior computation and communication efficiency and promotes fairness across clients.
Distributionally Robust Federated Learning with Client Drift Minimization
May 21, 2025



Federated learning (FL) faces critical challenges, particularly in heterogeneous environments where non-independent and identically distributed data across clients can lead to unfair and inefficient model performance. In this work, we introduce \textit{DRDM}, a novel algorithm that addresses these issues by combining a distributionally robust optimization (DRO) framework with dynamic regularization to mitigate client drift. \textit{DRDM} frames the training as a min-max optimization problem aimed at maximizing performance for the worst-case client, thereby promoting robustness and fairness. This robust objective is optimized through an algorithm leveraging dynamic regularization and efficient local updates, which significantly reduces the required number of communication rounds. Moreover, we provide a theoretical convergence analysis for convex smooth objectives under partial participation. Extensive experiments on three benchmark datasets, covering various model architectures and data heterogeneity levels, demonstrate that \textit{DRDM} significantly improves worst-case test accuracy while requiring fewer communication rounds than existing state-of-the-art baselines. Furthermore, we analyze the impact of signal-to-noise ratio (SNR) and bandwidth on the energy consumption of participating clients, demonstrating that the number of local update steps can be adaptively selected to achieve a target worst-case test accuracy with minimal total energy cost across diverse communication environments.
Large-Scale AI in Telecom: Charting the Roadmap for Innovation, Scalability, and Enhanced Digital Experiences
Mar 06, 2025



This white paper discusses the role of large-scale AI in the telecommunications industry, with a specific focus on the potential of generative AI to revolutionize network functions and user experiences, especially in the context of 6G systems. It highlights the development and deployment of Large Telecom Models (LTMs), which are tailored AI models designed to address the complex challenges faced by modern telecom networks. The paper covers a wide range of topics, from the architecture and deployment strategies of LTMs to their applications in network management, resource allocation, and optimization. It also explores the regulatory, ethical, and standardization considerations for LTMs, offering insights into their future integration into telecom infrastructure. The goal is to provide a comprehensive roadmap for the adoption of LTMs to enhance scalability, performance, and user-centric innovation in telecom networks.
Tackling Feature and Sample Heterogeneity in Decentralized Multi-Task Learning: A Sheaf-Theoretic Approach
Feb 03, 2025



Federated multi-task learning (FMTL) aims to simultaneously learn multiple related tasks across clients without sharing sensitive raw data. However, in the decentralized setting, existing FMTL frameworks are limited in their ability to capture complex task relationships and handle feature and sample heterogeneity across clients. To address these challenges, we introduce a novel sheaf-theoretic-based approach for FMTL. By representing client relationships using cellular sheaves, our framework can flexibly model interactions between heterogeneous client models. We formulate the sheaf-based FMTL optimization problem using sheaf Laplacian regularization and propose the Sheaf-FMTL algorithm to solve it. We show that the proposed framework provides a unified view encompassing many existing federated learning (FL) and FMTL approaches. Furthermore, we prove that our proposed algorithm, Sheaf-FMTL, achieves a sublinear convergence rate in line with state-of-the-art decentralized FMTL algorithms. Extensive experiments demonstrate that Sheaf-FMTL exhibits communication savings by sending significantly fewer bits compared to decentralized FMTL baselines.
MIRA: A Method of Federated MultI-Task Learning for LaRge LAnguage Models
Oct 20, 2024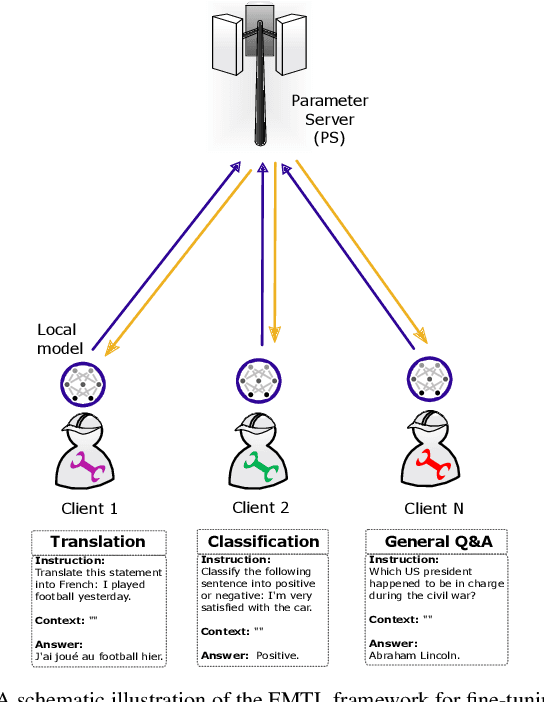
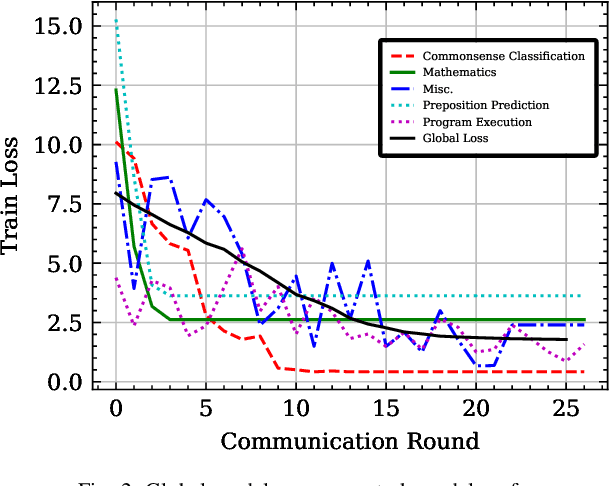
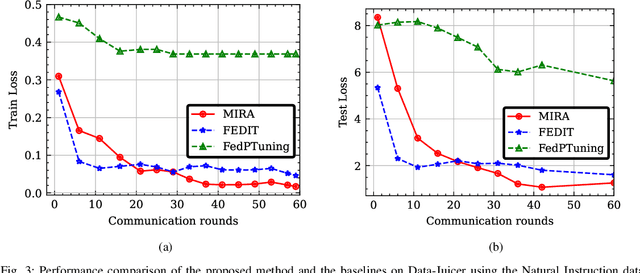
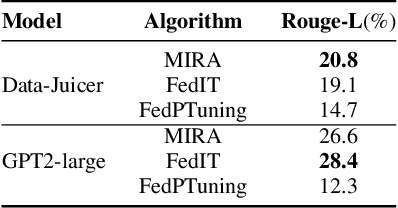
In this paper, we introduce a method for fine-tuning Large Language Models (LLMs), inspired by Multi-Task learning in a federated manner. Our approach leverages the structure of each client's model and enables a learning scheme that considers other clients' tasks and data distribution. To mitigate the extensive computational and communication overhead often associated with LLMs, we utilize a parameter-efficient fine-tuning method, specifically Low-Rank Adaptation (LoRA), reducing the number of trainable parameters. Experimental results, with different datasets and models, demonstrate the proposed method's effectiveness compared to existing frameworks for federated fine-tuning of LLMs in terms of average and local performances. The proposed scheme outperforms existing baselines by achieving lower local loss for each client while maintaining comparable global performance.
Scalable and Resource-Efficient Second-Order Federated Learning via Over-the-Air Aggregation
Oct 10, 2024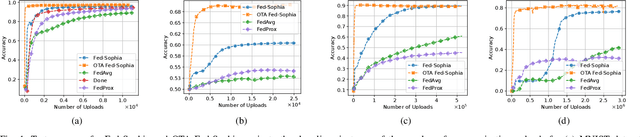

Second-order federated learning (FL) algorithms offer faster convergence than their first-order counterparts by leveraging curvature information. However, they are hindered by high computational and storage costs, particularly for large-scale models. Furthermore, the communication overhead associated with large models and digital transmission exacerbates these challenges, causing communication bottlenecks. In this work, we propose a scalable second-order FL algorithm using a sparse Hessian estimate and leveraging over-the-air aggregation, making it feasible for larger models. Our simulation results demonstrate more than $67\%$ of communication resources and energy savings compared to other first and second-order baselines.
A Web-Based Solution for Federated Learning with LLM-Based Automation
Aug 23, 2024Federated Learning (FL) offers a promising approach for collaborative machine learning across distributed devices. However, its adoption is hindered by the complexity of building reliable communication architectures and the need for expertise in both machine learning and network programming. This paper presents a comprehensive solution that simplifies the orchestration of FL tasks while integrating intent-based automation. We develop a user-friendly web application supporting the federated averaging (FedAvg) algorithm, enabling users to configure parameters through an intuitive interface. The backend solution efficiently manages communication between the parameter server and edge nodes. We also implement model compression and scheduling algorithms to optimize FL performance. Furthermore, we explore intent-based automation in FL using a fine-tuned Language Model (LLM) trained on a tailored dataset, allowing users to conduct FL tasks using high-level prompts. We observe that the LLM-based automated solution achieves comparable test accuracy to the standard web-based solution while reducing transferred bytes by up to 64% and CPU time by up to 46% for FL tasks. Also, we leverage the neural architecture search (NAS) and hyperparameter optimization (HPO) using LLM to improve the performance. We observe that by using this approach test accuracy can be improved by 10-20% for the carried out FL tasks.