 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIRA: A Method of Federated MultI-Task Learning for LaRge LAnguage Models
Oct 20, 2024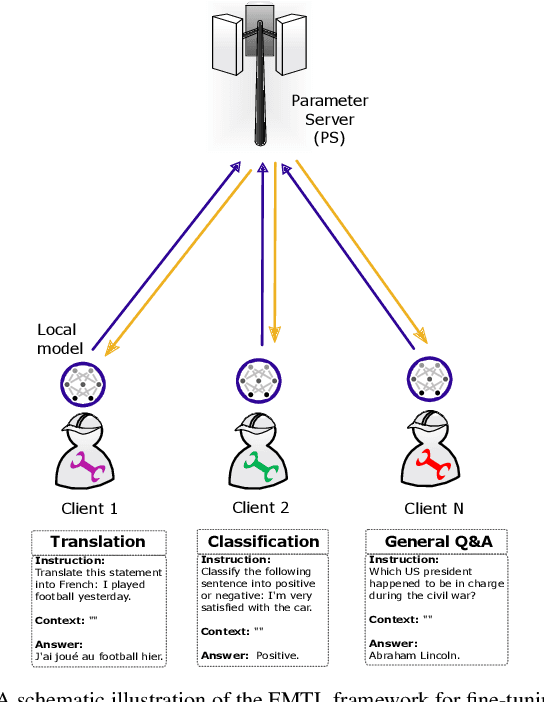
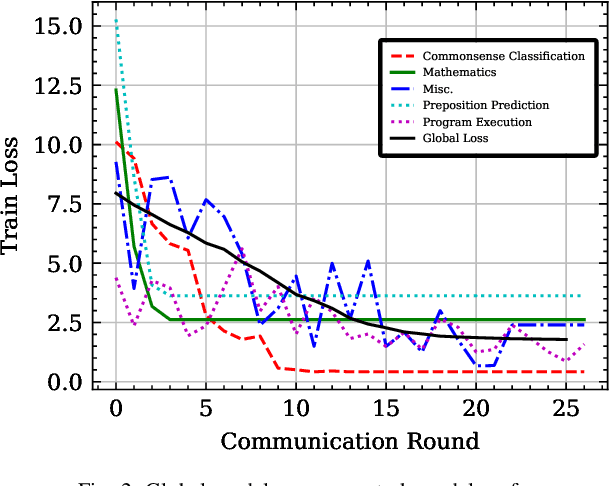
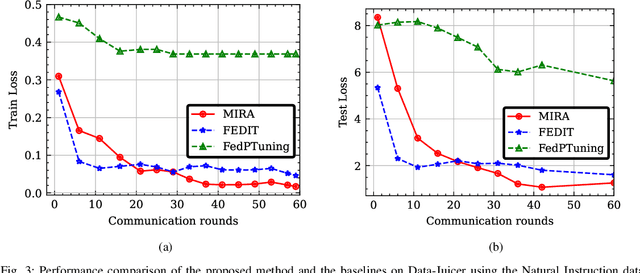
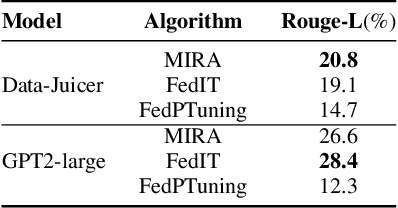
In this paper, we introduce a method for fine-tuning Large Language Models (LLMs), inspired by Multi-Task learning in a federated manner. Our approach leverages the structure of each client's model and enables a learning scheme that considers other clients' tasks and data distribution. To mitigate the extensive computational and communication overhead often associated with LLMs, we utilize a parameter-efficient fine-tuning method, specifically Low-Rank Adaptation (LoRA), reducing the number of trainable parameters. Experimental results, with different datasets and models, demonstrate the proposed method's effectiveness compared to existing frameworks for federated fine-tuning of LLMs in terms of average and local performances. The proposed scheme outperforms existing baselines by achieving lower local loss for each client while maintaining comparable global performance.
Fed-Sophia: A Communication-Efficient Second-Order Federated Learning Algorithm
Jun 10, 2024



Federated learning is a machine learning approach where multiple devices collaboratively learn with the help of a parameter server by sharing only their local updates. While gradient-based optimization techniques are widely adopted in this domain, the curvature information that second-order methods exhibit is crucial to guide and speed up the convergence. This paper introduces a scalable second-order method, allowing the adoption of curvature information in federated large models. Our method, coined Fed-Sophia, combines a weighted moving average of the gradient with a clipping operation to find the descent direction. In addition to that, a lightweight estimation of the Hessian's diagonal is used to incorporate the curvature information. Numerical evaluation shows the superiority, robustness, and scalability of the proposed Fed-Sophia scheme compared to first and second-order baselines.
A Cooperative Q-learning Approach for Real-time Power Allocation in Femtocell Networks
Mar 12, 2013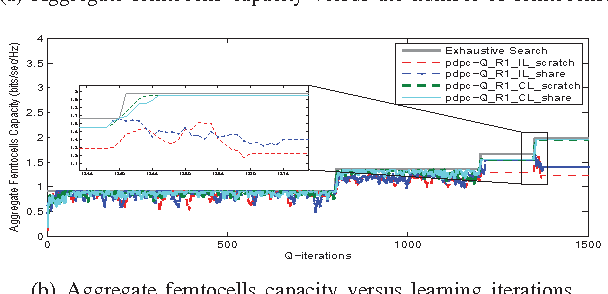
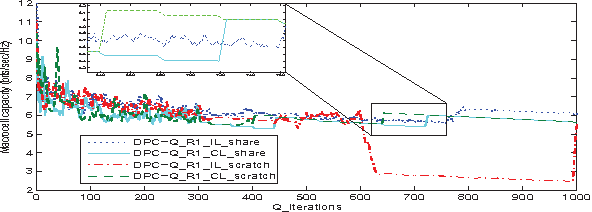

In this paper, we address the problem of distributed interference management of cognitive femtocells that share the same frequency range with macrocells (primary user) using distributed multi-agent Q-learning. We formulate and solve three problems representing three different Q-learning algorithms: namely, centralized, distributed and partially distributed power control using Q-learning (CPC-Q, DPC-Q and PDPC-Q). CPCQ, although not of practical interest, characterizes the global optimum. Each of DPC-Q and PDPC-Q works in two different learning paradigms: Independent (IL) and Cooperative (CL). The former is considered the simplest form for applying Qlearning in multi-agent scenarios, where all the femtocells learn independently. The latter is the proposed scheme in which femtocells share partial information during the learning process in order to strike a balance between practical relevance and performance. In terms of performance, the simulation results showed that the CL paradigm outperforms the IL paradigm and achieves an aggregate femtocells capacity that is very close to the optimal one. For the practical relevance issue, we evaluate the robustness and scalability of DPC-Q, in real time, by deploying new femtocells in the system during the learning process, where we showed that DPC-Q in the CL paradigm is scalable to large number of femtocells and more robust to the network dynamics compared to the IL paradigm
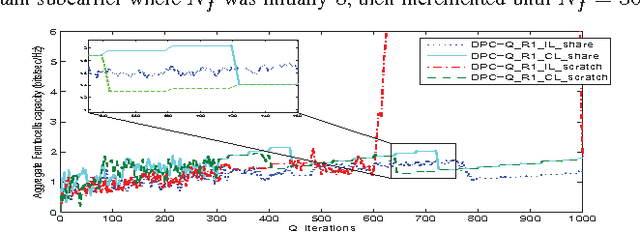
Distributed Cooperative Q-learning for Power Allocation in Cognitive Femtocell Networks
Mar 18, 2012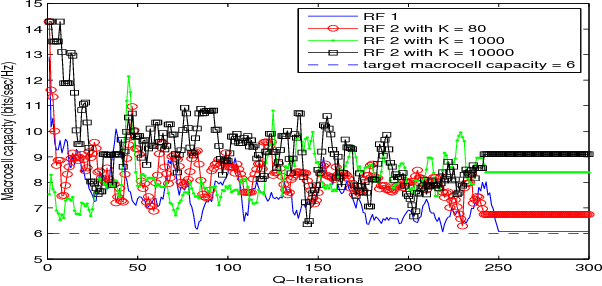
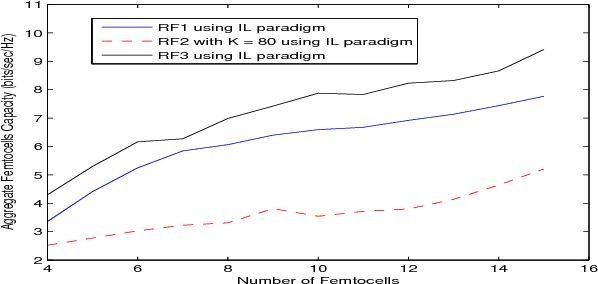
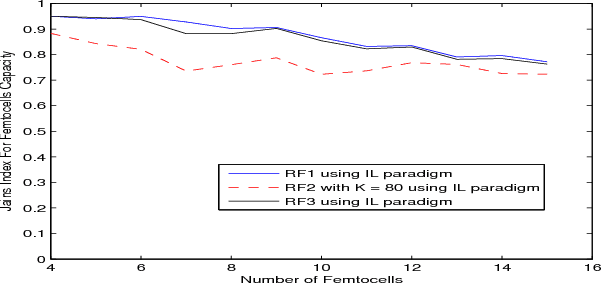
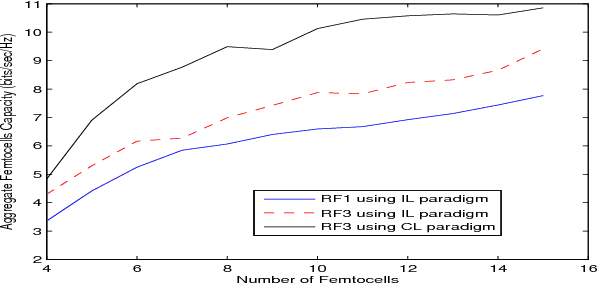
In this paper, we propose a distributed reinforcement learning (RL) technique called distributed power control using Q-learning (DPC-Q) to manage the interference caused by the femtocells on macro-users in the downlink. The DPC-Q leverages Q-Learning to identify the sub-optimal pattern of power allocation, which strives to maximize femtocell capacity, while guaranteeing macrocell capacity level in an underlay cognitive setting. We propose two different approaches for the DPC-Q algorithm: namely, independent, and cooperative. In the former, femtocells learn independently from each other while in the latter, femtocells share some information during learning in order to enhance their performance. Simulation results show that the independent approach is capable of mitigating the interference generated by the femtocells on macro-users. Moreover, the results show that cooperation enhances the performance of the femtocells in terms of speed of convergence, fairness and aggregate femtocell capacity.