 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Optimal Beacon Placement for Range-Aided Localization
May 19, 2024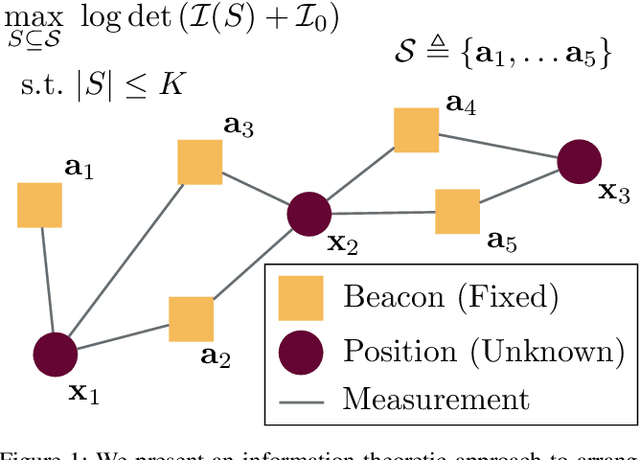
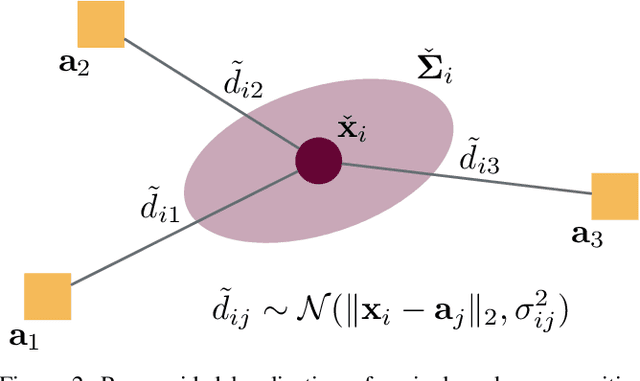

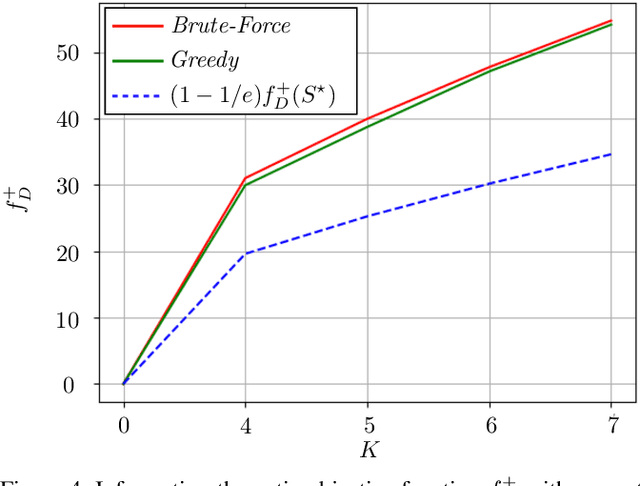
Range-based localization is ubiquitous: global navigation satellite systems (GNSS) power mobile phone-based navigation, and autonomous mobile robots can use range measurements from a variety of modalities including sonar, radar, and even WiFi signals. Many of these localization systems rely on fixed anchors or beacons with known positions acting as transmitters or receivers. In this work, we answer a fundamental question: given a set of positions we would like to localize, how should beacons be placed so as to minimize localization error? Specifically, we present an information theoretic method for optimally selecting an arrangement consisting of a few beacons from a large set of candidate positions. By formulating localization as maximum a posteriori (MAP) estimation, we can cast beacon arrangement as a submodular set function maximization problem. This approach is probabilistically rigorous, simple to implement, and extremely flexible. Furthermore, we prove that the submodular structure of our problem formulation ensures that a greedy algorithm for beacon arrangement has suboptimality guarantees. We compare our method with a number of benchmarks on simulated data and release an open source Python implementation of our algorithm and experiments.
Recovering a Single Community with Side Information
Sep 05, 2018
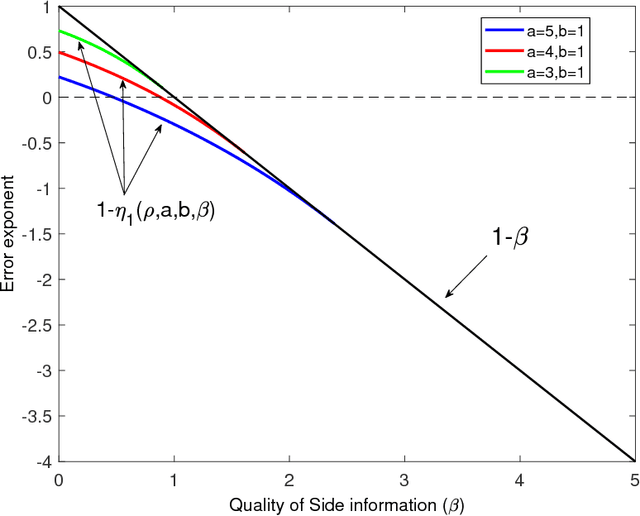
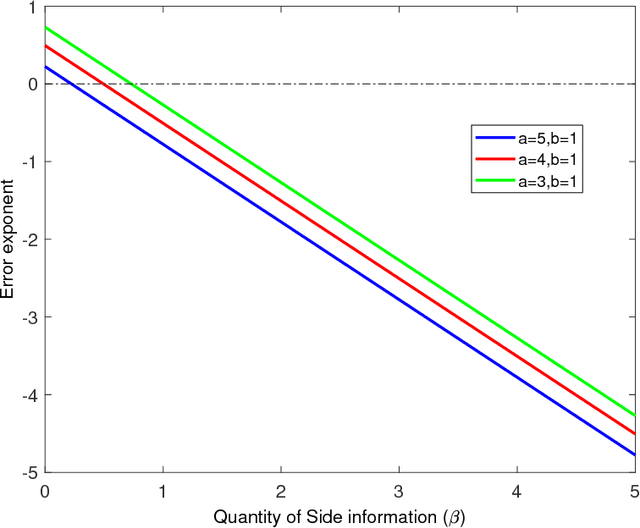
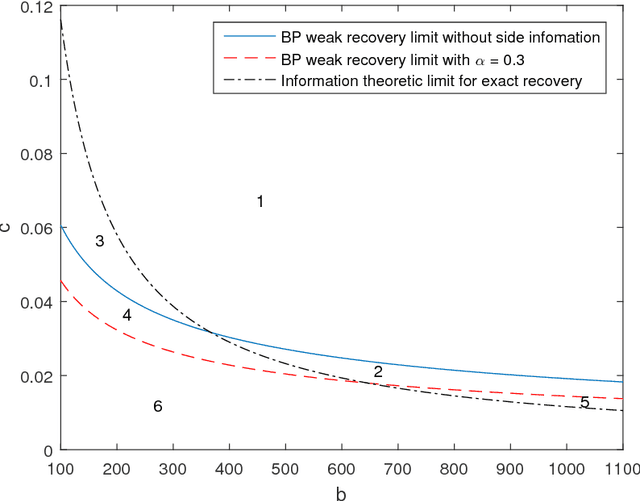
We study the effect of the quality and quantity of side information on the recovery of a hidden community of size $K=o(n)$ in a graph of size $n$. Side information for each node in the graph is modeled by a random vector with the following features: either the dimension of the vector is allowed to vary with $n$, while log-likelihood ratio (LLR) of each component with respect to the node label is fixed, or the LLR is allowed to vary and the vector dimension is fixed. These two models represent the variation in quality and quantity of side information. Under maximum likelihood detection, we calculate tight necessary and sufficient conditions for exact recovery of the labels. We demonstrate how side information needs to evolve with $n$ in terms of either its quantity, or quality, to improve the exact recovery threshold. A similar set of results are obtained for weak recovery. Under belief propagation, tight necessary and sufficient conditions for weak recovery are calculated when the LLRs are constant, and sufficient conditions when the LLRs vary with $n$. Moreover, we design and analyze a local voting procedure using side information that can achieve exact recovery when applied after belief propagation. The results for belief propagation are validated via simulations on finite synthetic data-sets, showing that the asymptotic results of this paper can also shed light on the performance at finite $n$.
A Cooperative Q-learning Approach for Real-time Power Allocation in Femtocell Networks
Mar 12, 2013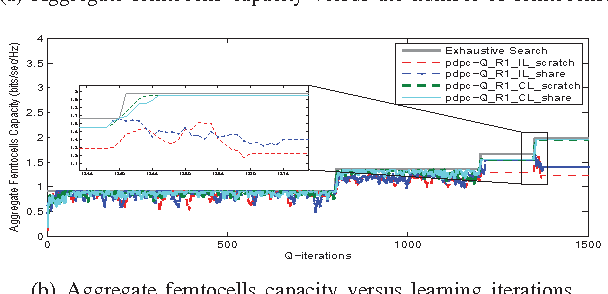
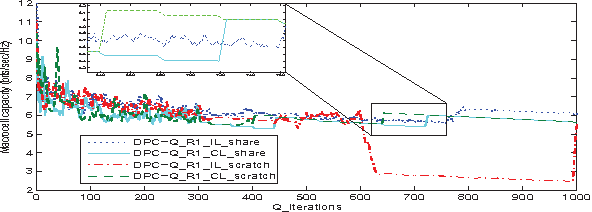
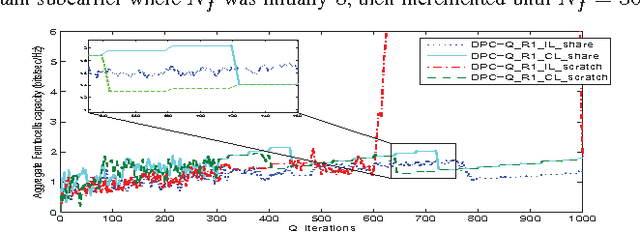

In this paper, we address the problem of distributed interference management of cognitive femtocells that share the same frequency range with macrocells (primary user) using distributed multi-agent Q-learning. We formulate and solve three problems representing three different Q-learning algorithms: namely, centralized, distributed and partially distributed power control using Q-learning (CPC-Q, DPC-Q and PDPC-Q). CPCQ, although not of practical interest, characterizes the global optimum. Each of DPC-Q and PDPC-Q works in two different learning paradigms: Independent (IL) and Cooperative (CL). The former is considered the simplest form for applying Qlearning in multi-agent scenarios, where all the femtocells learn independently. The latter is the proposed scheme in which femtocells share partial information during the learning process in order to strike a balance between practical relevance and performance. In terms of performance, the simulation results showed that the CL paradigm outperforms the IL paradigm and achieves an aggregate femtocells capacity that is very close to the optimal one. For the practical relevance issue, we evaluate the robustness and scalability of DPC-Q, in real time, by deploying new femtocells in the system during the learning process, where we showed that DPC-Q in the CL paradigm is scalable to large number of femtocells and more robust to the network dynamics compared to the IL paradigm
Distributed Cooperative Q-learning for Power Allocation in Cognitive Femtocell Networks
Mar 18, 2012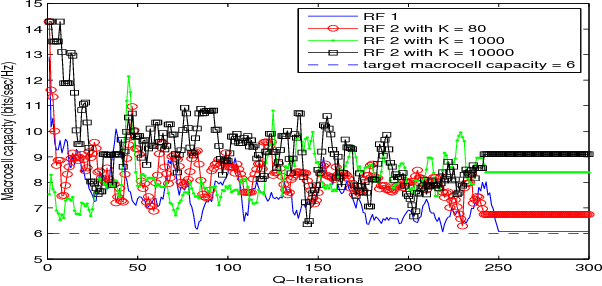
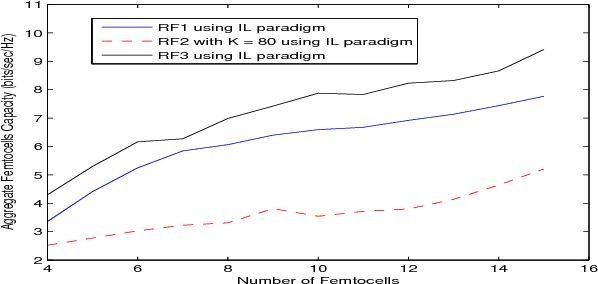
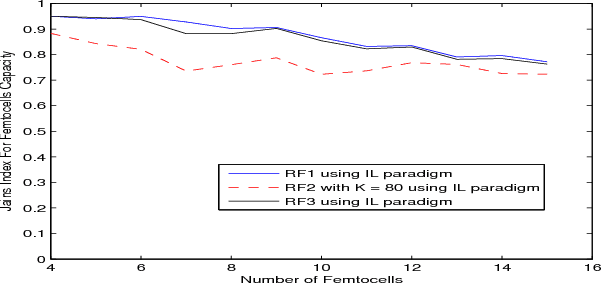
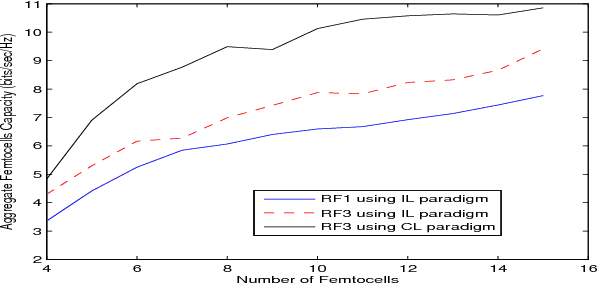
In this paper, we propose a distributed reinforcement learning (RL) technique called distributed power control using Q-learning (DPC-Q) to manage the interference caused by the femtocells on macro-users in the downlink. The DPC-Q leverages Q-Learning to identify the sub-optimal pattern of power allocation, which strives to maximize femtocell capacity, while guaranteeing macrocell capacity level in an underlay cognitive setting. We propose two different approaches for the DPC-Q algorithm: namely, independent, and cooperative. In the former, femtocells learn independently from each other while in the latter, femtocells share some information during learning in order to enhance their performance. Simulation results show that the independent approach is capable of mitigating the interference generated by the femtocells on macro-users. Moreover, the results show that cooperation enhances the performance of the femtocells in terms of speed of convergence, fairness and aggregate femtocell capacity.