 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Optimal Beacon Placement for Range-Aided Localization
May 19, 2024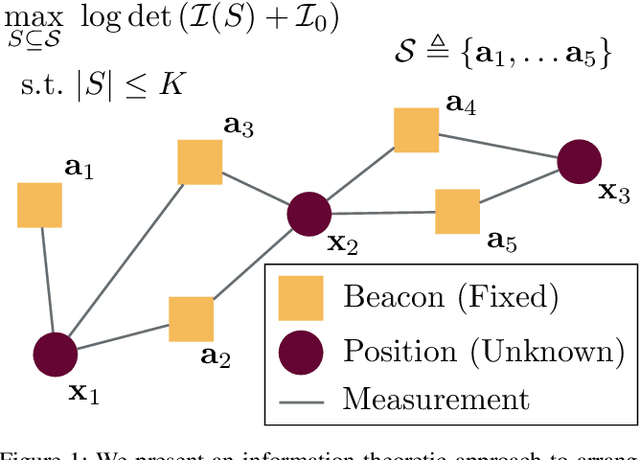
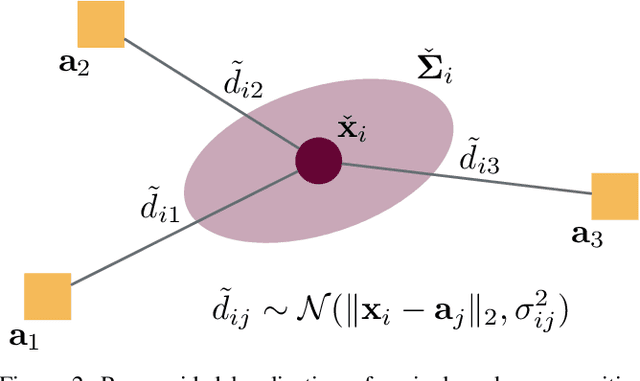

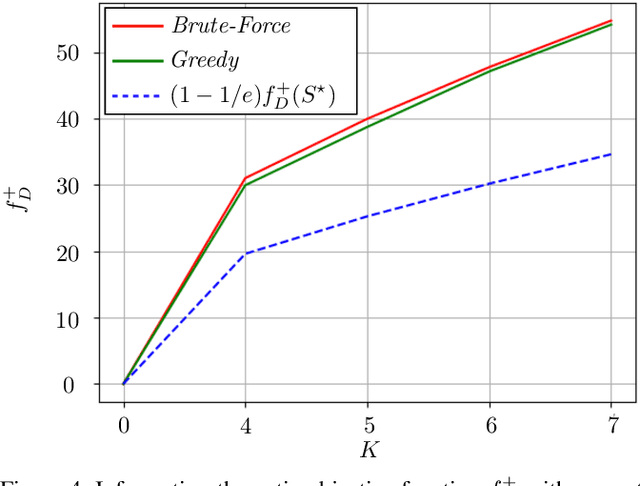
Range-based localization is ubiquitous: global navigation satellite systems (GNSS) power mobile phone-based navigation, and autonomous mobile robots can use range measurements from a variety of modalities including sonar, radar, and even WiFi signals. Many of these localization systems rely on fixed anchors or beacons with known positions acting as transmitters or receivers. In this work, we answer a fundamental question: given a set of positions we would like to localize, how should beacons be placed so as to minimize localization error? Specifically, we present an information theoretic method for optimally selecting an arrangement consisting of a few beacons from a large set of candidate positions. By formulating localization as maximum a posteriori (MAP) estimation, we can cast beacon arrangement as a submodular set function maximization problem. This approach is probabilistically rigorous, simple to implement, and extremely flexible. Furthermore, we prove that the submodular structure of our problem formulation ensures that a greedy algorithm for beacon arrangement has suboptimality guarantees. We compare our method with a number of benchmarks on simulated data and release an open source Python implementation of our algorithm and experiments.
Discovering Adaptable Symbolic Algorithms from Scratch
Jul 31, 2023

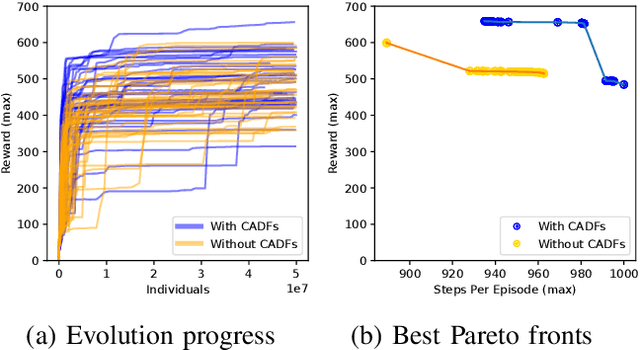
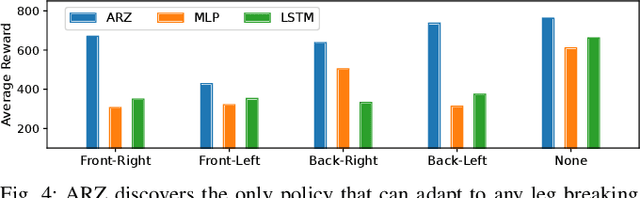
Autonomous robots deployed in the real world will need control policies that rapidly adapt to environmental changes. To this end, we propose AutoRobotics-Zero (ARZ), a method based on AutoML-Zero that discovers zero-shot adaptable policies from scratch. In contrast to neural network adaption policies, where only model parameters are optimized, ARZ can build control algorithms with the full expressive power of a linear register machine. We evolve modular policies that tune their model parameters and alter their inference algorithm on-the-fly to adapt to sudden environmental changes. We demonstrate our method on a realistic simulated quadruped robot, for which we evolve safe control policies that avoid falling when individual limbs suddenly break. This is a challenging task in which two popular neural network baselines fail. Finally, we conduct a detailed analysis of our method on a novel and challenging non-stationary control task dubbed Cataclysmic Cartpole. Results confirm our findings that ARZ is significantly more robust to sudden environmental changes and can build simple, interpretable control policies.
Evolving Hierarchical Memory-Prediction Machines in Multi-Task Reinforcement Learning
Jun 23, 2021

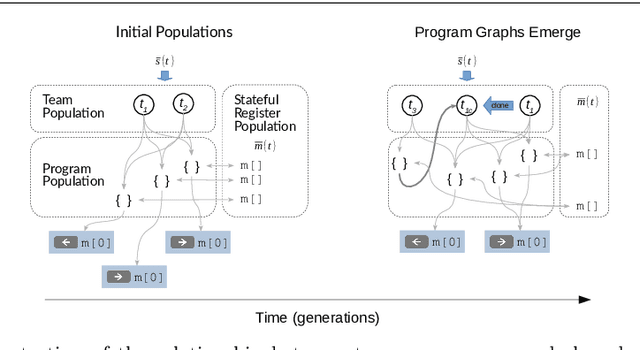
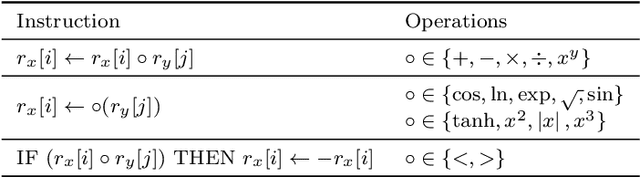
A fundamental aspect of behaviour is the ability to encode salient features of experience in memory and use these memories, in combination with current sensory information, to predict the best action for each situation such that long-term objectives are maximized. The world is highly dynamic, and behavioural agents must generalize across a variety of environments and objectives over time. This scenario can be modeled as a partially-observable multi-task reinforcement learning problem. We use genetic programming to evolve highly-generalized agents capable of operating in six unique environments from the control literature, including OpenAI's entire Classic Control suite. This requires the agent to support discrete and continuous actions simultaneously. No task-identification sensor inputs are provided, thus agents must identify tasks from the dynamics of state variables alone and define control policies for each task. We show that emergent hierarchical structure in the evolving programs leads to multi-task agents that succeed by performing a temporal decomposition and encoding of the problem environments in memory. The resulting agents are competitive with task-specific agents in all six environments. Furthermore, the hierarchical structure of programs allows for dynamic run-time complexity, which results in relatively efficient operation.
The Factory Must Grow: Automation in Factorio
Feb 09, 2021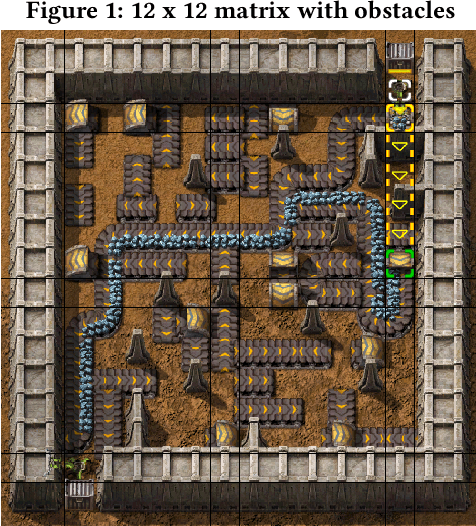

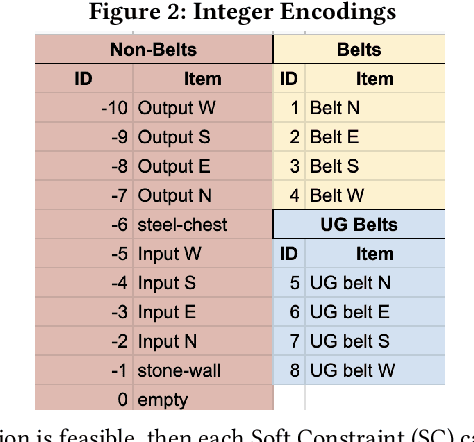
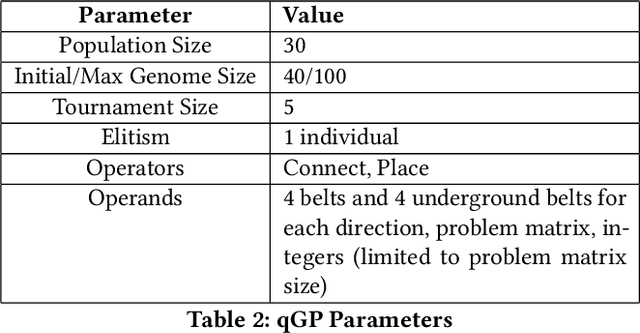
Efficient optimization of resources is paramount to success in many problems faced today. In the field of operational research the efficient scheduling of employees; packing of vans; routing of vehicles; logistics of airlines and transport of materials can be the difference between emission reduction or excess, profits or losses and feasibility or unworkable solutions. The video game Factorio, by Wube Software, has a myriad of problems which are analogous to such real-world problems, and is a useful simulator for developing solutions for these problems. In this paper we define the logistic transport belt problem and define mathematical integer programming model of it. We developed an interface to allow optimizers in any programming language to interact with Factorio, and we provide an initial benchmark of logistic transport belt problems. We present results for Simulated Annealing, quick Genetic Programming and Evolutionary Reinforcement Learning, three different meta-heuristic techniques to optimize this novel problem.