 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Adaptable Symbolic Algorithms from Scratch
Jul 31, 2023

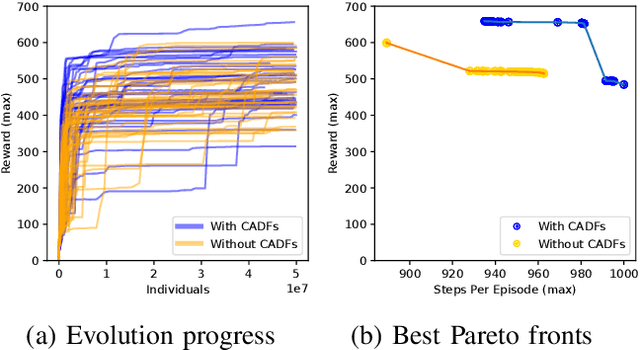
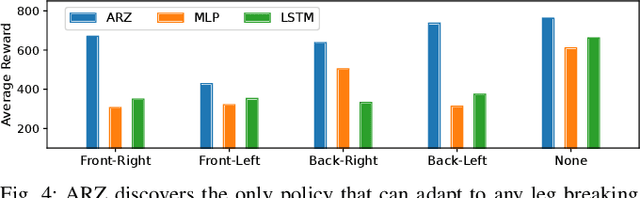
Autonomous robots deployed in the real world will need control policies that rapidly adapt to environmental changes. To this end, we propose AutoRobotics-Zero (ARZ), a method based on AutoML-Zero that discovers zero-shot adaptable policies from scratch. In contrast to neural network adaption policies, where only model parameters are optimized, ARZ can build control algorithms with the full expressive power of a linear register machine. We evolve modular policies that tune their model parameters and alter their inference algorithm on-the-fly to adapt to sudden environmental changes. We demonstrate our method on a realistic simulated quadruped robot, for which we evolve safe control policies that avoid falling when individual limbs suddenly break. This is a challenging task in which two popular neural network baselines fail. Finally, we conduct a detailed analysis of our method on a novel and challenging non-stationary control task dubbed Cataclysmic Cartpole. Results confirm our findings that ARZ is significantly more robust to sudden environmental changes and can build simple, interpretable control policies.
Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages
Mar 03, 2023
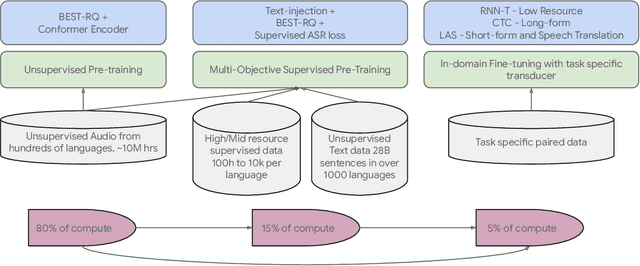
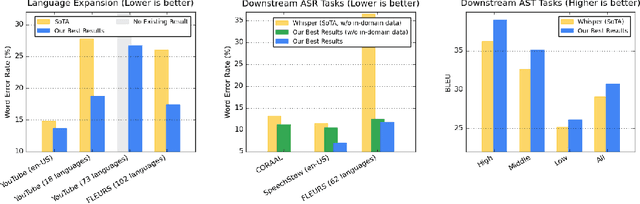

We introduce the Universal Speech Model (USM), a single large model that performs automatic speech recognition (ASR) across 100+ languages. This is achieved by pre-training the encoder of the model on a large unlabeled multilingual dataset of 12 million (M) hours spanning over 300 languages, and fine-tuning on a smaller labeled dataset. We use multilingual pre-training with random-projection quantization and speech-text modality matching to achieve state-of-the-art performance on downstream multilingual ASR and speech-to-text translation tasks. We also demonstrate that despite using a labeled training set 1/7-th the size of that used for the Whisper model, our model exhibits comparable or better performance on both in-domain and out-of-domain speech recognition tasks across many languages.
Noise2Music: Text-conditioned Music Generation with Diffusion Models
Feb 08, 2023

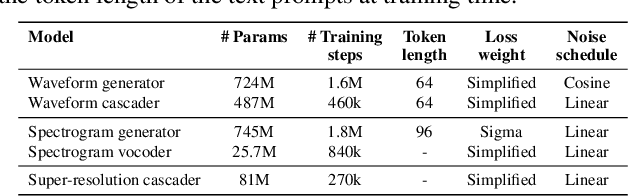
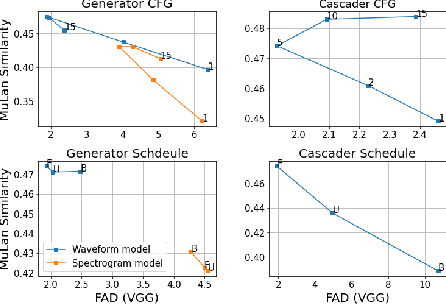
We introduce Noise2Music, where a series of diffusion models is trained to generate high-quality 30-second music clips from text prompts. Two types of diffusion models, a generator model, which generates an intermediate representation conditioned on text, and a cascader model, which generates high-fidelity audio conditioned on the intermediate representation and possibly the text, are trained and utilized in succession to generate high-fidelity music. We explore two options for the intermediate representation, one using a spectrogram and the other using audio with lower fidelity. We find that the generated audio is not only able to faithfully reflect key elements of the text prompt such as genre, tempo, instruments, mood, and era, but goes beyond to ground fine-grained semantics of the prompt. Pretrained large language models play a key role in this story -- they are used to generate paired text for the audio of the training set and to extract embeddings of the text prompts ingested by the diffusion models. Generated examples: https://google-research.github.io/noise2music
G-Augment: Searching For The Meta-Structure Of Data Augmentation Policies For ASR
Oct 19, 2022
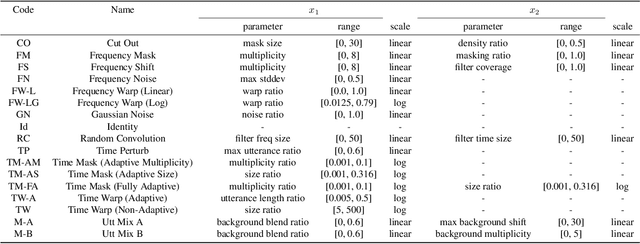
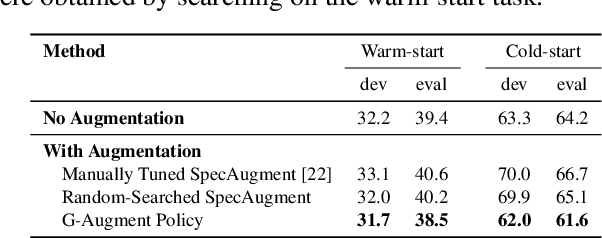
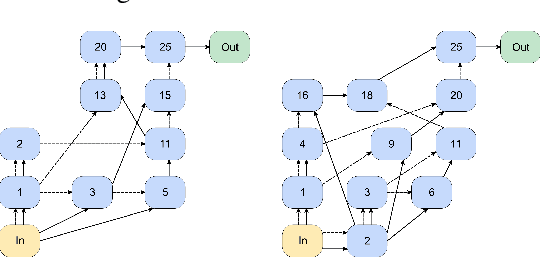
Data augmentation is a ubiquitous technique used to provide robustness to automatic speech recognition (ASR) training. However, even as so much of the ASR training process has become automated and more "end-to-end", the data augmentation policy (what augmentation functions to use, and how to apply them) remains hand-crafted. We present Graph-Augment, a technique to define the augmentation space as directed acyclic graphs (DAGs) and search over this space to optimize the augmentation policy itself. We show that given the same computational budget, policies produced by G-Augment are able to perform better than SpecAugment policies obtained by random search on fine-tuning tasks on CHiME-6 and AMI. G-Augment is also able to establish a new state-of-the-art ASR performance on the CHiME-6 evaluation set (30.7% WER). We further demonstrate that G-Augment policies show better transfer properties across warm-start to cold-start training and model size compared to random-searched SpecAugment policies.
BigSSL: Exploring the Frontier of Large-Scale Semi-Supervised Learning for Automatic Speech Recognition
Oct 01, 2021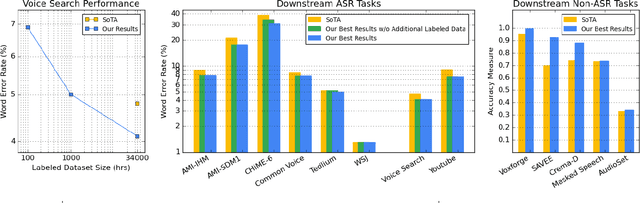
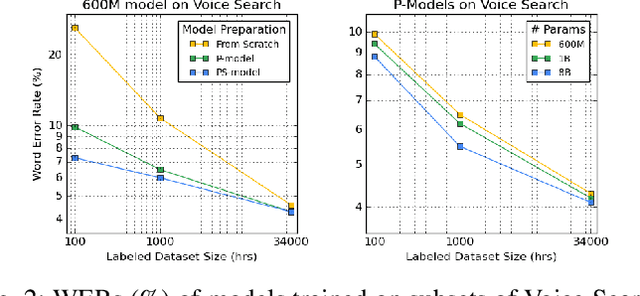
We summarize the results of a host of efforts using giant automatic speech recognition (ASR) models pre-trained using large, diverse unlabeled datasets containing approximately a million hours of audio. We find that the combination of pre-training, self-training and scaling up model size greatly increases data efficiency, even for extremely large tasks with tens of thousands of hours of labeled data. In particular, on an ASR task with 34k hours of labeled data, by fine-tuning an 8 billion parameter pre-trained Conformer model we can match state-of-the-art (SoTA) performance with only 3% of the training data and significantly improve SoTA with the full training set. We also report on the universal benefits gained from using big pre-trained and self-trained models for a large set of downstream tasks that cover a wide range of speech domains and span multiple orders of magnitudes of dataset sizes, including obtaining SoTA performance on many public benchmarks. In addition, we utilize the learned representation of pre-trained networks to achieve SoTA results on non-ASR tasks.
Towards NNGP-guided Neural Architecture Search
Nov 11, 2020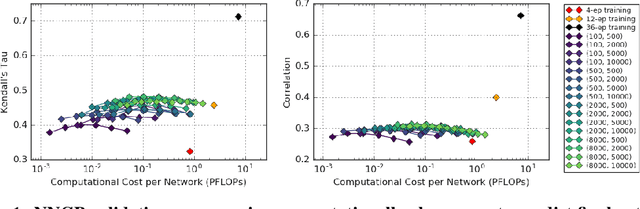

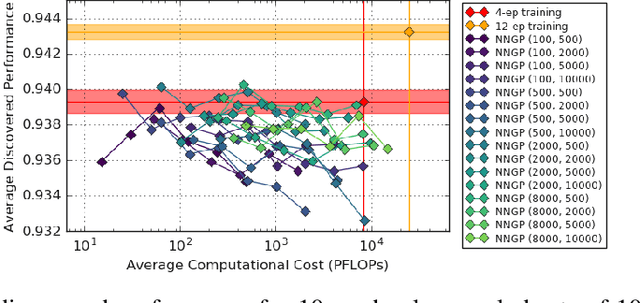

The predictions of wide Bayesian neural networks are described by a Gaussian process, known as the Neural Network Gaussian Process (NNGP). Analytic forms for NNGP kernels are known for many models, but computing the exact kernel for convolutional architectures is prohibitively expensive. One can obtain effective approximations of these kernels through Monte-Carlo estimation using finite networks at initialization. Monte-Carlo NNGP inference is orders-of-magnitude cheaper in FLOPs compared to gradient descent training when the dataset size is small. Since NNGP inference provides a cheap measure of performance of a network architecture, we investigate its potential as a signal for neural architecture search (NAS). We compute the NNGP performance of approximately 423k networks in the NAS-bench 101 dataset on CIFAR-10 and compare its utility against conventional performance measures obtained by shortened gradient-based training. We carry out a similar analysis on 10k randomly sampled networks in the mobile neural architecture search (MNAS) space for ImageNet. We discover comparative advantages of NNGP-based metrics, and discuss potential applications. In particular, we propose that NNGP performance is an inexpensive signal independent of metrics obtained from training that can either be used for reducing big search spaces, or improving training-based performance measures.
Pushing the Limits of Semi-Supervised Learning for Automatic Speech Recognition
Oct 20, 2020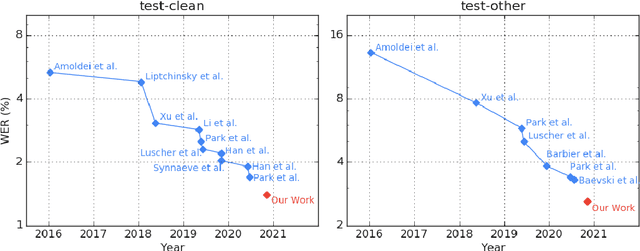

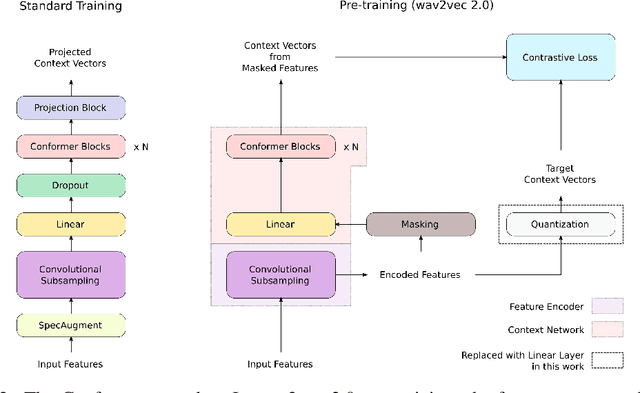
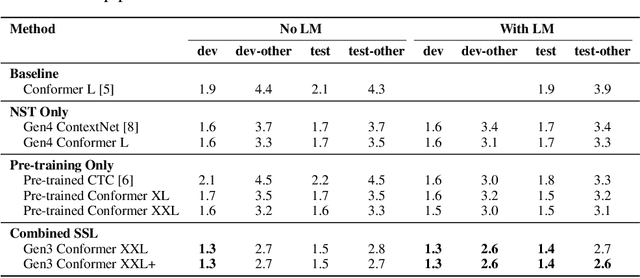
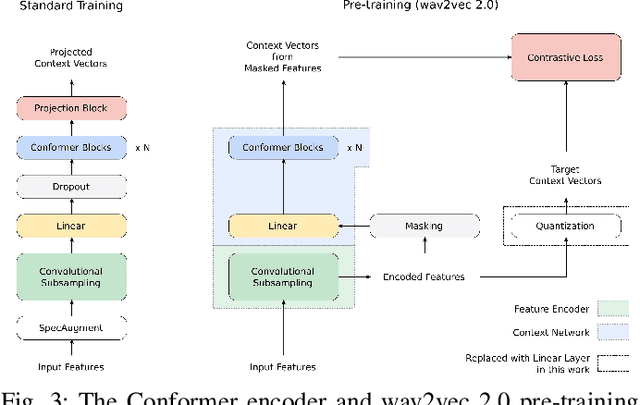
We employ a combination of recent developments in semi-supervised learning for automatic speech recognition to obtain state-of-the-art results on LibriSpeech utilizing the unlabeled audio of the Libri-Light dataset. More precisely, we carry out noisy student training with SpecAugment using giant Conformer models pre-trained using wav2vec 2.0 pre-training. By doing so, we are able to achieve word-error-rates (WERs) 1.4%/2.6% on the LibriSpeech test/test-other sets against the current state-of-the-art WERs 1.7%/3.3%.
Improved Noisy Student Training for Automatic Speech Recognition
May 19, 2020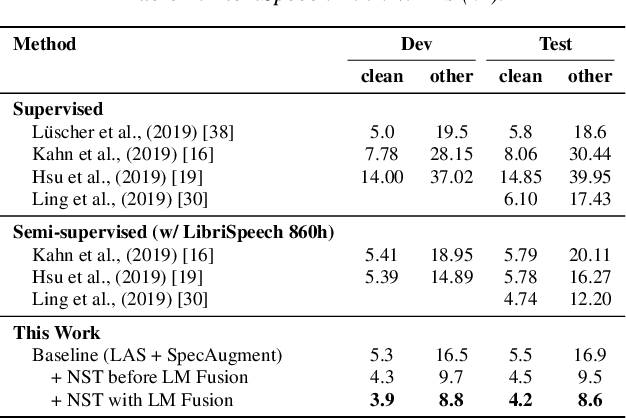
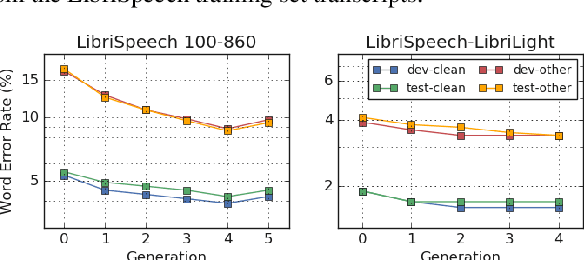
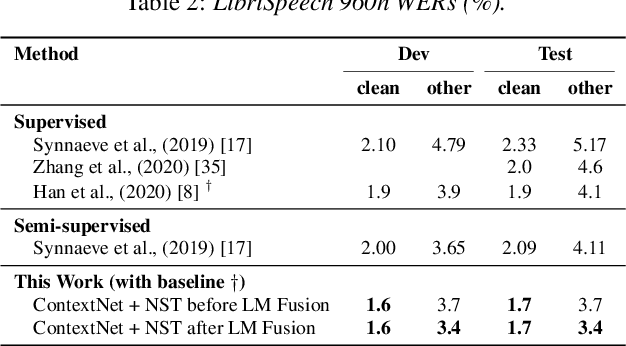
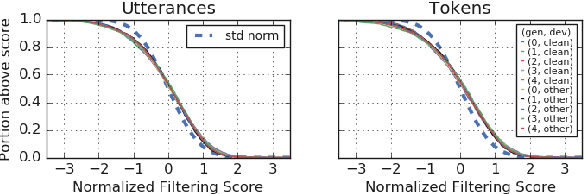
Recently, a semi-supervised learning method known as "noisy student training" has been shown to improve image classification performance of deep networks significantly. Noisy student training is an iterative self-training method that leverages augmentation to improve network performance. In this work, we adapt and improve noisy student training for automatic speech recognition, employing (adaptive) SpecAugment as the augmentation method. We find effective methods to filter, balance and augment the data generated in between self-training iterations. By doing so, we are able to obtain word error rates (WERs) 4.2%/8.6% on the clean/noisy LibriSpeech test sets by only using the clean 100h subset of LibriSpeech as the supervised set and the rest (860h) as the unlabeled set. Furthermore, we are able to achieve WERs 1.7%/3.4% on the clean/noisy LibriSpeech test sets by using the unlab-60k subset of LibriLight as the unlabeled set for LibriSpeech 960h. We are thus able to improve upon the previous state-of-the-art clean/noisy test WERs achieved on LibriSpeech 100h (4.74%/12.20%) and LibriSpeech (1.9%/4.1%).
SpecAugment on Large Scale Datasets
Dec 11, 2019
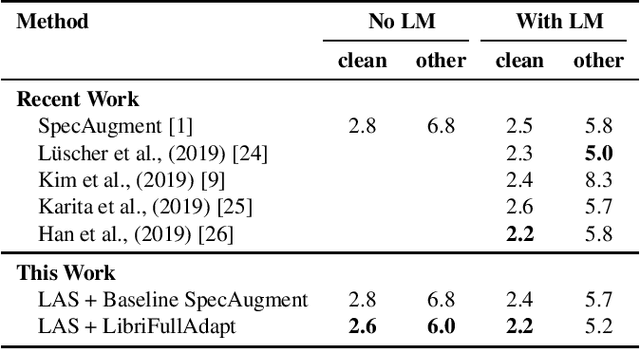
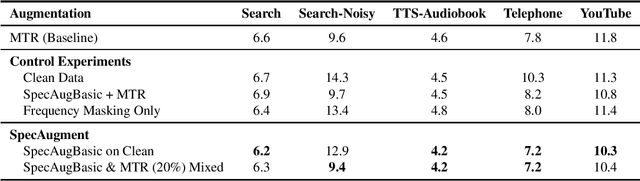
Recently, SpecAugment, an augmentation scheme for automatic speech recognition that acts directly on the spectrogram of input utterances, has shown to be highly effective in enhancing the performance of end-to-end networks on public datasets. In this paper, we demonstrate its effectiveness on tasks with large scale datasets by investigating its application to the Google Multidomain Dataset (Narayanan et al., 2018). We achieve improvement across all test domains by mixing raw training data augmented with SpecAugment and noise-perturbed training data when training the acoustic model. We also introduce a modification of SpecAugment that adapts the time mask size and/or multiplicity depending on the length of the utterance, which can potentially benefit large scale tasks. By using adaptive masking, we are able to further improve the performance of the Listen, Attend and Spell model on LibriSpeech to 2.2% WER on test-clean and 5.2% WER on test-other.
The Effect of Network Width on Stochastic Gradient Descent and Generalization: an Empirical Study
May 09, 2019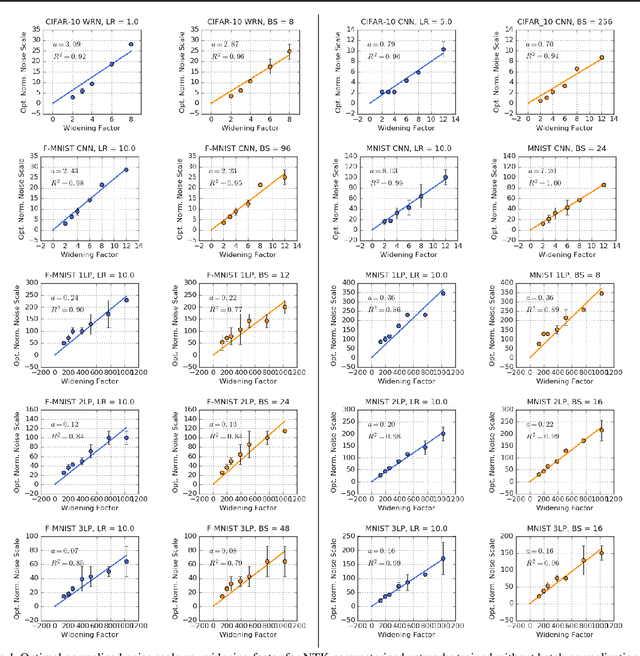
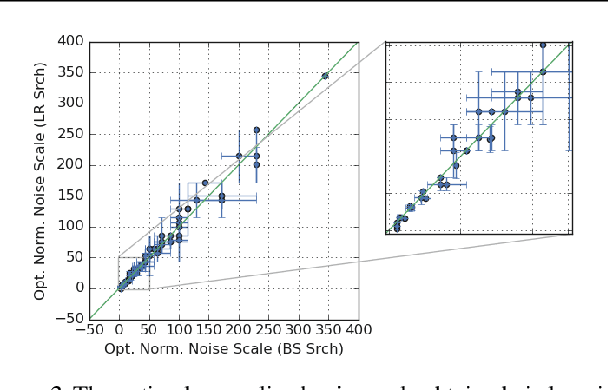
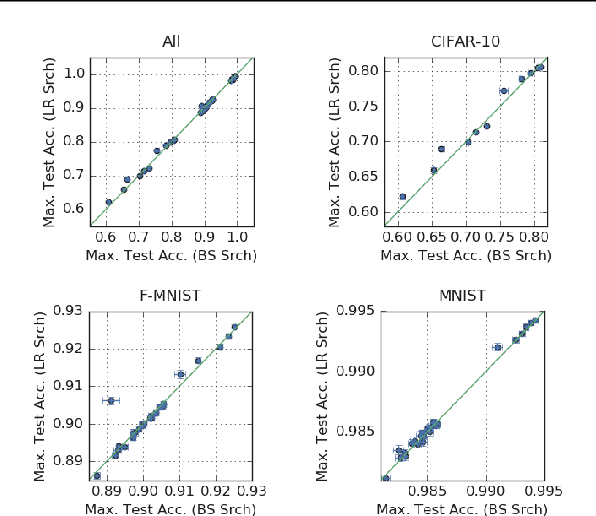

We investigate how the final parameters found by stochastic gradient descent are influenced by over-parameterization. We generate families of models by increasing the number of channels in a base network, and then perform a large hyper-parameter search to study how the test error depends on learning rate, batch size, and network width. We find that the optimal SGD hyper-parameters are determined by a "normalized noise scale," which is a function of the batch size, learning rate, and initialization conditions. In the absence of batch normalization, the optimal normalized noise scale is directly proportional to width. Wider networks, with their higher optimal noise scale, also achieve higher test accuracy. These observations hold for MLPs, ConvNets, and ResNets, and for two different parameterization schemes ("Standard" and "NTK"). We observe a similar trend with batch normalization for ResNets. Surprisingly, since the largest stable learning rate is bounded, the largest batch size consistent with the optimal normalized noise scale decreases as the width increases.